






词法分析的目的将分割代码,并转化成词法单元:关键字、变量名称、关系运算符等等

一段代码,我们写起来是上面那个规范的形式,但是对于编译器而言,代码就是下面的那一段话,空格、换行等都是字符,通过字符可以知道发生了什么。
Token Class
In English: noun, verb, adjective..
In a programming language: identifier, keywords, (, ), numbers..
每个token class都是对应了一组字符串
identifier: strings of letters or digits, starting with a letter
integer: a non-empty string of digits
whitespace: a non-empty sequence of blanks, newlines, and tabs
代码可以被分割成很多子字符串,每个子字符串都是其中一种
classify program substrings according to role
communicate tokens to the parser
因此,lexical analysis其实就是把代码进行分割为一个个子串,每个子串都对应了一种token class。
下一阶段的parser语法分析就是基于这些token进行分析的
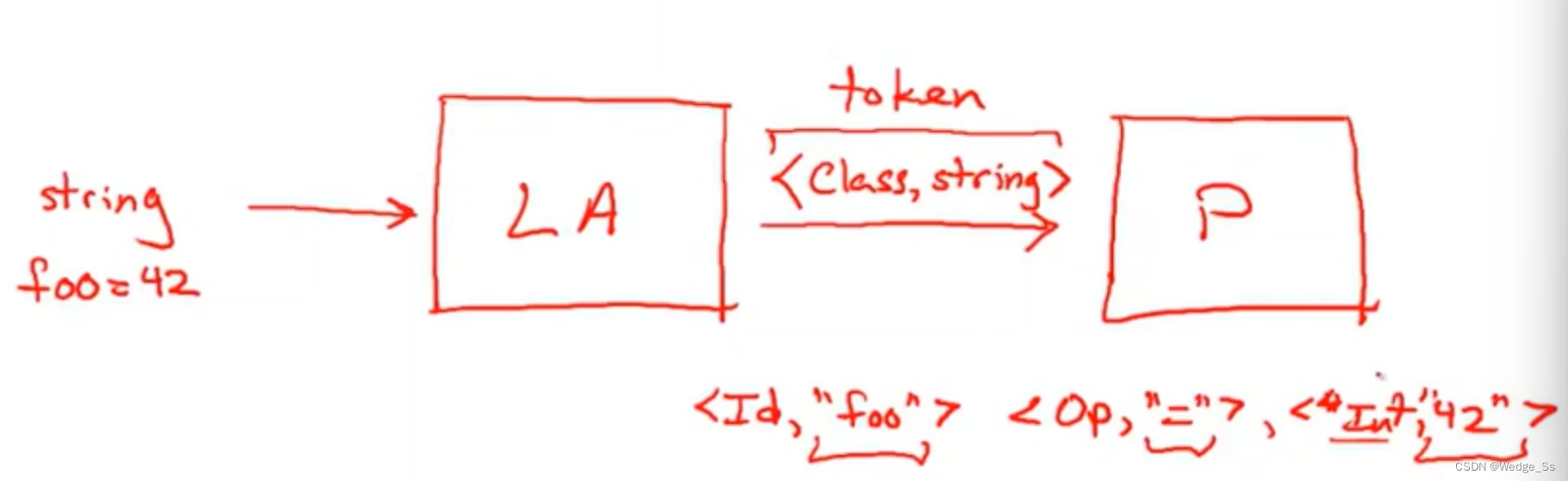
简单来说LA需要做的两件事情
1、Recognize substrings(The lexemes) corresponding to tokens;
2、Identify the token class of each lexeme;
首先就是根据tokens的规则,识别出代码中的每个词素(lexemes),也就是每个子字符串,后续给每个lexemes分配它的类型,到底是idtentifier还是numbers或是别的。
FORTRAN中LA的实现
rule: Whitespace is insignificant
可以无视空格,VAR1和VA R1是等效的,处理的时候会将那些空格都删掉

这个是龙书上一个例子
上下两个式子的差别在于:
第一个式子中1和25之间的符号为逗号
第二个式子中1和25之间的符号为点号
第一个式子的语义为进行一个loop循环,让i从1开始递增到25
第二个式子的语义为,为一个变量名为DO5I的变量赋值1.25
而编译器从左向右进行顺序扫描,直到扫描到后面的符号是逗号还是点号才能进行token的划分
这就是编译器lookahead的特性,很多时候那些substring有多种可能性,需要不断往后扫描获取信息才能够确定那个substring到底是类型。
因此编译器的一个设计目标就是最小化lookahead的开销
那么为什么FORTRAN设计的时候,为什么要无视空格呢?因为当时程序都是写在打卡机上,所以避免打卡机重复打空格,最终的程序都是没有空格存在。
FORTRAN的LA分析
为了分割这个代码,按照从左向右进行扫描,每次识别一个token,但是还需要Lookahead机制来确认一个token到底划分到哪里为止。
PL/1语言的LA设计
PL/1中并不会限制标识符和关键字进行区分,那么就会有下面这个神奇的代码出现
此时,LA的设计实现就会变得十分复杂

此外,另一个案例,DECLARE本来应作为关键词来声明变量,但是如果无法不进行区分的话,那可能就会DECLARE(ARG1,..,ARGN)可能表示的就是一个数组,DECLARE是一个数组名
编译器不得不需要完整扫描整行代码,根据后面有没有等号来确定这到底是数组还是声明表达式
并且ARG的数量是不受限制的,如果数量非常多的话,将会带来高昂的lookahead开销
C++编译器的一个典型问题
C++的模板类语法和流类型的语法
vector<vector<int>>; cin >>; vector<vector<int> >;
我们可以看到这个>>难以区分到底是哪种语法
目前编译器要求程序员针对嵌套模板类,两个尖括号之间需要加入空格来区分,这种修复方式十分丑陋。
但是新的编译器应该都已经解决这个问题了
Fortran编译器的结论
我们可以看到LA阶段进行顺序扫描的时候,有时候还需要lookahead机制,此外还需要区分标识符和关键词,这些都是从过去的编译器中吸取到的经验
正则表达式
词法结构就是token classes,我们既然需要将一段代码划分成子串,那么我们就需要知道那些token class里面应该包含哪些子串,我们通常就会使用regular languages(正则表达式)来表示。
基本组成部分
-
Single character:表示一个字符
-
Epsilon:表示一个单个字符的空字符串
-
Union:表示两个集合的并集
-
Concatenation:表示两个集合中每个元素进行级联
-
Iteration:循环构造,通常用克莱尼星号来表示

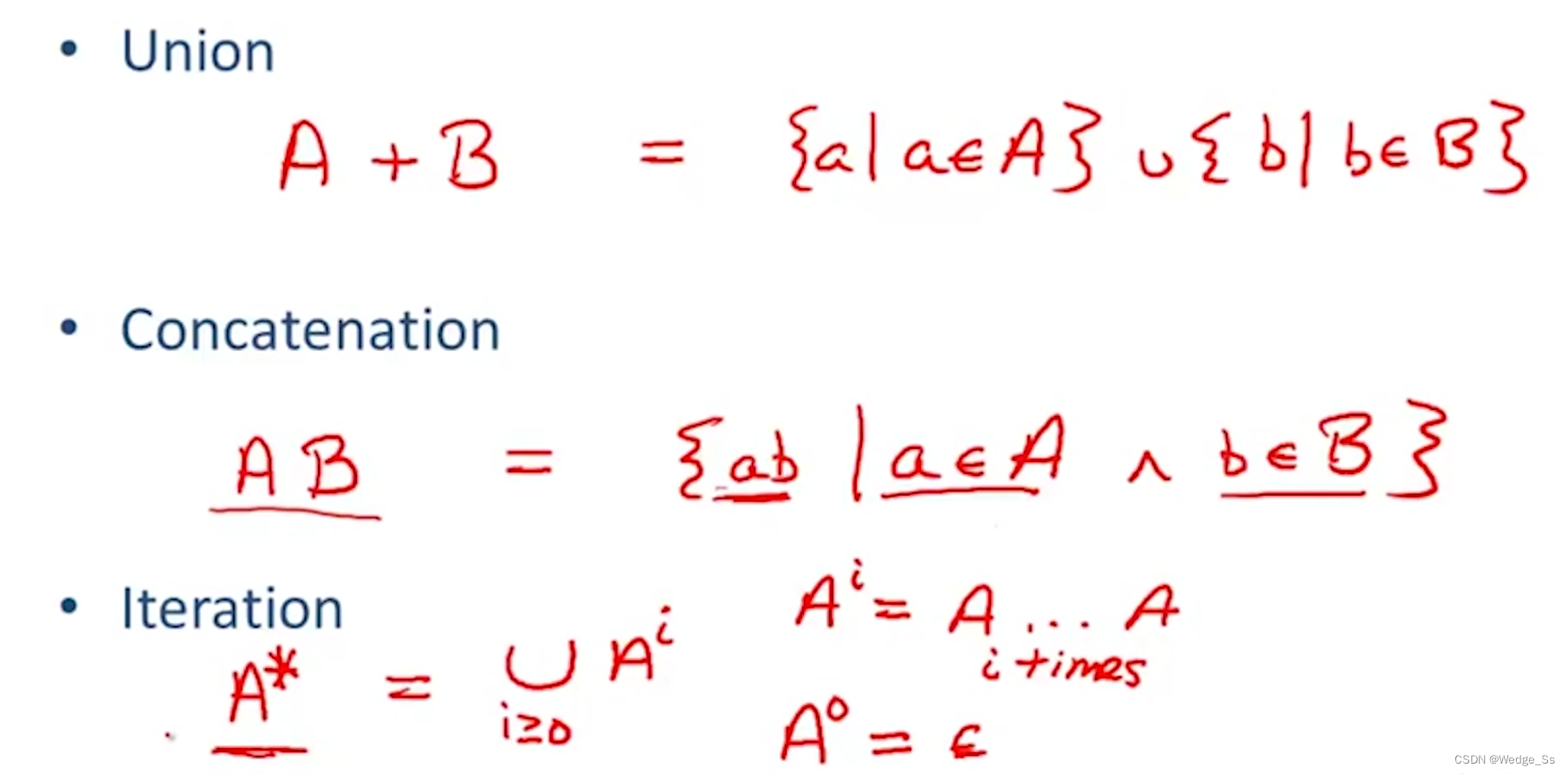
Alphabet:匹配字母表的正则表达式是最小的表达式集合

表示一个集合往往有好多种正则表达式来表示,例如(1+0)1 = 11 + 01
小结
正则表达式定义正则语言,所谓的正则语言记录了一组字符串,也就是正则表达式地含义。
正则表达式由5种基本组件,空或单个字符,和3种复合表达式
Formal Languages

一个formal language就是基于指定的字符构建的任意字符集
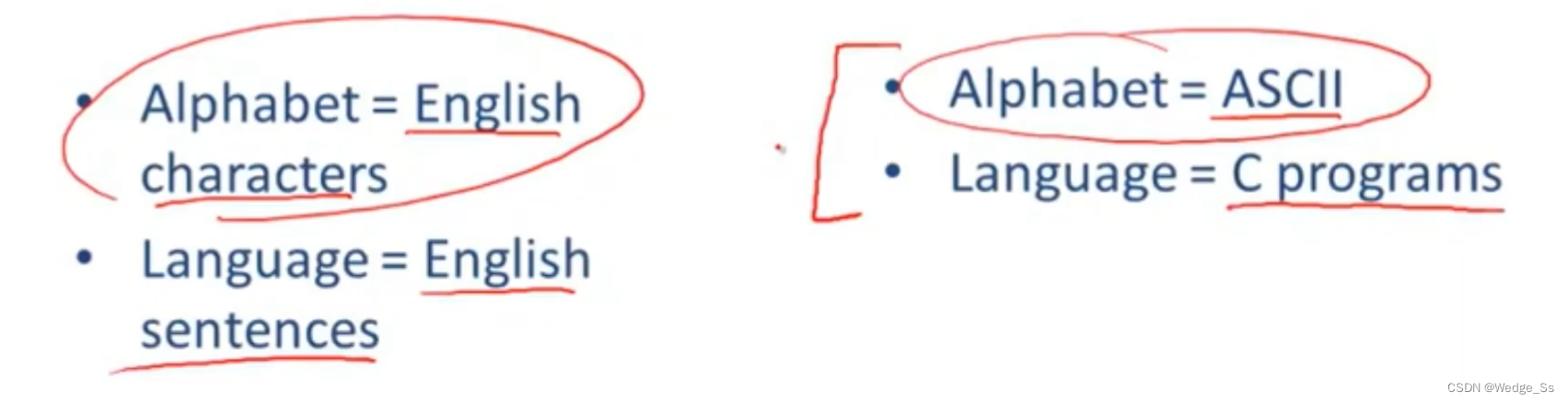
类比的方式来说明的话
在英语里面,Alphabet就是英文字母,Language就是由英文字母组成的那些句子
对于编译器而言,Alphabet就是ACSII码对应的字符,而C程序就是由那些ASCII码所表示的那些字符构建
Meaning function
Meaning function L maps syntax to semantics
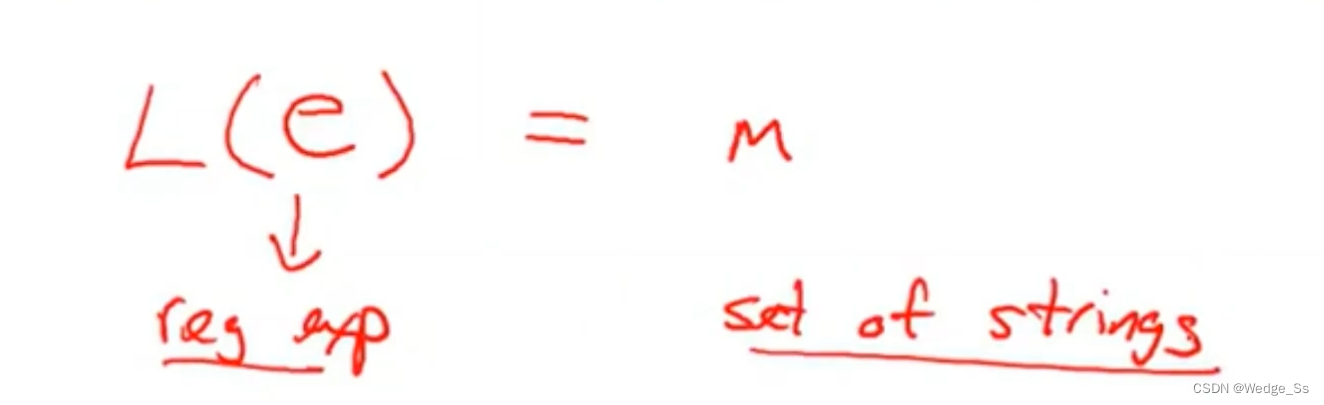
一个有意义的语法规则,可以将没有意义的语法映射到一个语义上,将语法和语义建立数理逻辑关系。
图中的e就是正则表达式,通过L可以将这个正则表达式映射为一组字符串集合
L让正则表达式e对应一组字符串集合M,正则表达式成为了L的定义域中的值,M就是指定定义域所对应的值域

关于正则表达式含义的正确定义,可以通过L(e)来显式表达指定的语义,也就是指定的字符串集合
并且L()可以递归地将复合表达式分解为多个子表达式,通过对子表达式计算得到子集,再由子集得到最终集合
Why use a meaning function?
Makes clear what is syntax, what is semantics.
从上面的分析中,我们可以将语法和语义分开
Allows us to consider notation as a separate issue
语法和语义分开后,我们可以思考一个点,那就是进行修改时,我们可以做到改变语法的同时保持语义不变。
我们可以发现,对于同一种语义的表示中,不同语言使用的是不同的语法,有些语言的语法会比另种语言的语法更好
Because expressions and meanings are not 1-1
此外,还有一点语法和语义并非是一对一的关系,很多语法组合可能表示都是同一种语义
举例理解:对于罗马数字和阿拉伯数字,罗马数字的加减乘除计算是非常费力的,而阿拉伯数字则有了很大的改善,因为人们更容易学习如何使用这些数字进行基本的算术,不同的系统都使用阿拉伯数字,但是不同系统之间可能存在不同的运算符号,唯一改变的就是符号系统,符号非常重要,它决定了你的思维方式、可以说的话以及将使用的程序,因此分离了语法和语义,仅凭数字是无法表达我们想要做什么。
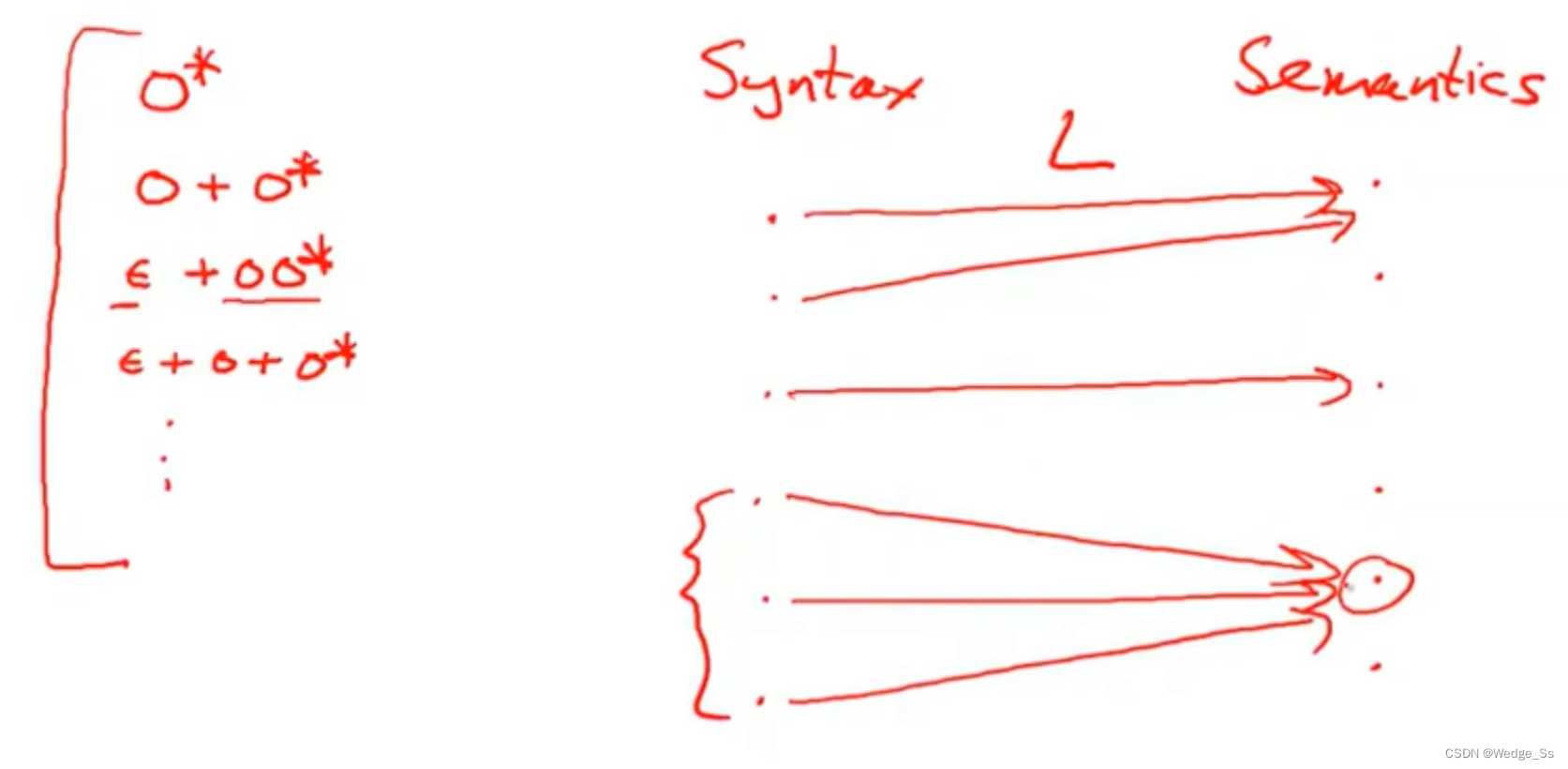
上图中,左边的正则表达式其实表示的含义都是相同的,不同的表达式或者说不同的语法讲的可能是同一件事情,
这就是formal languages的一个通用特征,这对于编译器而言非常重要,因为这是后面优化的基础,很多程序其实都是等效的,如果另个程序可以运行的更快并且执行效果完全相同,那就可以进行替换。
![]()
写程序时不应该出现相反的情况,也就是L可以单个点映射到不同的含义中,这表明某些表达式在我们的编程语言中的含义没有得到很好的定义,这个程序的执行结果时模棱两可的,这绝不是我们想要的。

















 141
141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









