







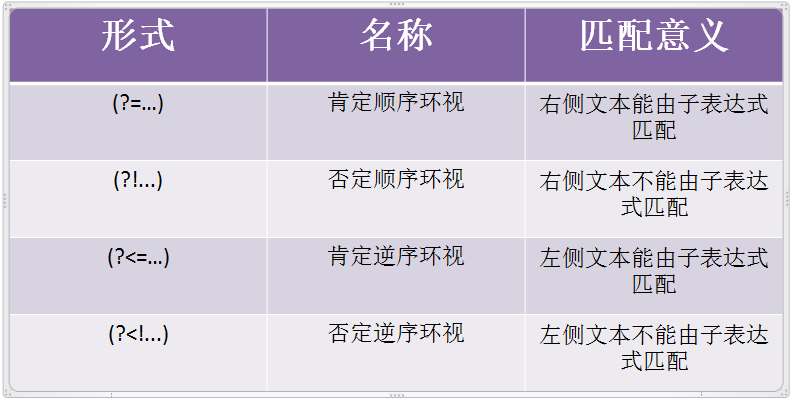
环视
锚点对位置的判断不够灵活所以引出环视
作用:应用子表达式对位置进行判断
形式:
(?=...)
(?!...)
(?<=...)
(?<!...)
例子1:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa17 {
public static void main(String[] args) {
String[] strings = new String[] { "Jeff", "Jeffrey", "Jefferson"};
String[] regexes = new String[] { "Jeff", "Jeff(?=rey)", "Jeff(?!rey)"};
for (String regex : regexes) {
for (String str : strings) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(str);
if(m.find()) {
System.out.println("\"" + str
+ "\" can be matched with regex \"" + regex
+ "\"");
}
else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex
+ "\"");
}
}
System.out.println("");
}
}
}
运行结果:
"Jeff" can be matched with regex "Jeff"
"Jeffrey" can be matched with regex "Jeff"
"Jefferson" can be matched with regex "Jeff"
"Jeff" can not be matched with regex "Jeff(?=rey)"
"Jeffrey" can be matched with regex "Jeff(?=rey)"
"Jefferson" can not be matched with regex "Jeff(?=rey)"
"Jeff" can be matched with regex "Jeff(?!rey)"
"Jeffrey" can not be matched with regex "Jeff(?!rey)"
"Jefferson" can be matched with regex "Jeff(?!rey)"
例子2:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa18 {
public static void main(String[] args) {
String[] strings = new String[] {"see", "bee", "tee"};
String[] regexes = new String[] { "(?<=s)ee", "(?<!s)ee"};
for (String regex : regexes) {
for (String str : strings) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(str);
if(m.find()) {
System.out.println("\"" + str
+ "\" can be matched with regex \"" + regex
+ "\"");
}
else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex
+ "\"");
}
}
System.out.println("");
}
}
}
运行结果:
"see" can be matched with regex "(?<=s)ee"
"bee" can not be matched with regex "(?<=s)ee"
"tee" can not be matched with regex "(?<=s)ee"
"see" can not be matched with regex "(?<!s)ee"
"bee" can be matched with regex "(?<!s)ee"
"tee" can be matched with regex "(?<!s)ee"环视的注意事项
- 环视结构仅仅用于布尔判断,位置查找替换或者分割,结构内的子表达式所匹配的文本,不会保存在整个表达式的匹配结果之中,所以不能用于字符的获取。
例子:
import java.util.regex.*;
public class pa22{
public static void main(String args[]){
String sta="see";
String regex="(?<=s)ee";
Pattern pattern=Pattern.compile(regex);
Matcher matcher=pattern.matcher(sta);
while(matcher.find()){
System.out.println(matcher.group());
}
}
}运行结果:
ee逆序环视结构对子表达式存在限制
- Perl,Python:逆序环视结构中的子表达式必须为固定长度。(即不能够使用长度不固定的量词也不能够使用长度不相同的多选结构)
- PHP,Java:逆序环视结构中的子表达式可以不定长度,但必须有上限。(即不能够使用*,+等无上限量词)
- .NET:逆序环视结构中的子表达式完全没有限制。
环视应用实例
- 修整数值
要求:在数值中的合适位置插入逗号,将其修正为便于阅读的形式。
举例:
123456789->1,234,567,890
123456->123,456
仔细总结就会知道这个规律:
左侧至少出现一位数字,右侧出现的数字位数是3的倍数。
例子:
如果下面这个例子大家第一眼看不懂不要紧,我会在第一个例子之后给大家解释这是怎么来的。
因为我第一眼当时也没看懂。当然大神就另当别论了。
public class pa19{
public static void main(String args[]){
String sta="123456789";
String regex="(?<=\\d)(?=(?:\\d{3})+(?!\\d))";
System.out.println("["+sta.replaceAll(regex,",")+"]");
}
}运行结果:
[123,456,789]不知道大家还记得我以前解释的那两个锚点不??//b和//B,在这里我就要用\b给大家解释了。\b和\B的用法及区别及注意事项
\b和\B是分界符,^,$也是分界符,而我们这里说的环视的四个表达式也是分界符,(?=…)肯定顺序环视,(?!…)否定顺序环视,(?<=…)逆序肯定环视,(?< !…)逆序否定环视。它们四个是匹配子表达式的右边或者左边的那个边界。就像是\b匹配单词和符号之间的边界一样。
再结合下面这个例子来解释:
public class pa20{
public static void main(String args[]){
String sta="123456789";
String regex="(?=\\d)";
System.out.println("####################### 1 ##########################");
System.out.println("1是想让你知道,它是否能够切割字符,并且你要仔细斟酌它是从哪儿里切割的!!!");
String arrays[]=sta.split(regex);
for(String i:arrays){
System.out.println("["+i+"]");
}
System.out.println("####################### 2 ##########################");
System.out.println("2是想让你知道这个答案,它是从哪儿被切割的!!!");
System.out.println(sta.replaceAll(regex,","));
}
}运行结果:
####################### 1 ##########################
1是想让你知道,它是否能够切割字符,并且你要仔细斟酌它是从哪儿里切割的!!!
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
####################### 2 ##########################
2是想让你知道这个答案,它是从哪儿被切割的!!!
,1,2,3,4,5,6,7,8,9是否这个切割的部位让你出乎意料呢???
如果没有的话,我当时确实是出乎了意料的。但是仔细想了下。答案也确实该这样。为什么呢??因为(?=…)是顺序环视结构,而它的子表达式所匹配的是右边,而它的边界所在位置应该在左边。想一想前面的一个例子 “Jeff(?=rey)”。(?=rey)的子表达式rey匹配的是右边,而它本身也是一种子表达式类型的相对定位,用来定位边界的所在位置。只是恰巧也可以来判断类似于这种 “Jeff(?=rey)” 的组成罢了。而它本身却是用来确定边界的所在位置。而(?=…)它就是用来确定子表达式匹配位置的左边边界。(?<=…)它就是用来确定子表达式匹配位置的右边边界。
所以那个数字格式整理的例子也就迎刃而解了。
整理数字正则表达式执行顺序:
整理数字的那个例子为什么该有的地方都有 “,”号了呢??首先它的执行顺序是从左到右,因为第一遍只有最后扫描的文本最后才找到匹配的那个规则,而之后因为有了第一个 “,”号所以就陆续在文本前面就有满足正则的字符串,以此类推就出现了输出得最终结果。
那么想不想看看”\b”的匹配规则呢??
例子:
public class pa21{
public static void main(String args[]){
String sta="1-2-3-4-5-6";
String regex="\\b";
System.out.println(sta.replaceAll(regex,"|"));
}
}运行结果:
|1|-|2|-|3|-|4|-|5|-|6|\b在每个单词和符号的分界地方都添加了”|”号(因为是replaceAll),也包括字符开头和结尾!!!字符串的开头和结尾当然也在\b的规定范围中。
这也可以明显看出,\b和环视一样,都是匹配边界的。
匹配模式
- 作用:改变某些结构的匹配规定。
- 以下介绍的模式都是常用的模式。所以其它模式我就没有再介绍了。
形式:
- I: Case Insensitive 不区分大小写
- S: SingleLine(dot All) 点号通配,这里得dot(点)号是能够匹配所有的字符,包括换行和回车符
- M: MultiLine 多行模式
- X: Comment 注释模式
1.I:不区分大小写
作用:在匹配时,不对英文单词区分大小写。
首先来看这个例子:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa23 {
public static void main(String[] args) {
String str = "abc";
String regex = "ABC";
Pattern p = Pattern.compile(regex);//
Matcher m = p.matcher(str);
if(m.find()) {
System.out.println("\"" + str
+ "\" can be matched with regex \"" + regex
+ "\"");
} else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex
+ "\"");
}
}
}
运行结果:
"abc" can not be matched with regex "ABC"然后我们来加上匹配模式试试:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa23 {
public static void main(String[] args) {
String str = "abc";
String regex = "ABC";
Pattern p = Pattern.compile(regex,Pattern.CASE_INSENSITIVE);//这里加了个CASE_INSENSITIVE
Matcher m = p.matcher(str);
if(m.find()) {
System.out.println("\"" + str
+ "\" can be matched with regex \"" + regex
+ "\"");
} else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex
+ "\"");
}
}
}
运行结果:
"abc" can be matched with regex "ABC"2.S: 单行模式
- 作用:更改点号 “.”的匹配规定,本来默认的匹配模式 “.”号是不会匹配换行和回车的,现在,设定了这个模式也就可以匹配换行符了。
例子1:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa24 {
public static void main(String[] args) {
String str = "<a href=www.itcast.net>\nITCAST\n</a>";
String regex = "<a href=([^>]+)>.*</a>";
Pattern p = Pattern.compile(regex);//
Matcher m = p.matcher(str);
if(m.find()) {
System.out.println("\"" + str
+ "\" can be matched with regex \"" + regex
+ "\"");
} else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex
+ "\"");
}
}
}运行结果:
"<a href=www.itcast.net>
ITCAST
</a>" can not be matched with regex "<a href=([^>]+)>.*</a>"所以,在普通模式下是不能够匹配换行的。
例子2:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa24 {
public static void main(String[] args) {
String str = "<a href=www.itcast.net>\nITCAST\n</a>";
String regex = "<a href=([^>]+)>.*</a>";
Pattern p = Pattern.compile(regex,Pattern.DOTALL);//加了个DOTALL匹配模式,就能够匹配换行和回车符号了。
Matcher m = p.matcher(str);
if(m.find()) {
System.out.println("\"" + str
+ "\" can be matched with regex \"" + regex
+ "\"");
} else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex
+ "\"");
}
}
}运行结果:
"<a href=www.itcast.net>
ITCAST
</a>" can be matched with regex "<a href=([^>]+)>.*</a>"这下就匹配了所有字符,包括换行和回车符号。
3.M: 多行模式
- 作用:更改 “^”和 “$”的匹配规定,它们可以匹配字符串内部各行文本的开头和结束位置。
- \A和\Z则不受影响。
例子1:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa25 {
public static void main(String[] args) {
String str = "<a href=www.itcast.net>\nITCAST\n</a>";
String regex = "^ITCAST$";
Pattern p = Pattern.compile(regex);//
Matcher m = p.matcher(str);
if (m.find()) {
System.out.println("\"" + str + "\" can be matched with regex \""
+ regex + "\"");
} else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex + "\"");
}
}
}
运行结果:
"<a href=www.itcast.net>
ITCAST
</a>" can not be matched with regex "^ITCAST$"很明显,在默认情况下, “^”和 “$”是匹配整个字符串的开始和结尾的。
那么在修改了匹配模式之后呢??是否匹配能够有所改变!!!
例子2:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa25 {
public static void main(String[] args) {
String str = "<a href=www.itcast.net>\nITCAST\n</a>";
String regex = "^ITCAST$";
Pattern p = Pattern.compile(regex,Pattern.MULTILINE);//
Matcher m = p.matcher(str);
if (m.find()) {
System.out.println("\"" + str + "\" can be matched with regex \""
+ regex + "\"");
} else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex + "\"");
}
}
}运行结果:
"<a href=www.itcast.net>
ITCAST
</a>" can be matched with regex "^ITCAST$"所以,修改匹配模式,用来匹配整段字符串的逻辑行的开始和结尾是有效的。
4.X: 注释模式
- 作用:在正则表达式内部可以使用注释。
- 形式:注释以 “#”开头,以换行符结束(或者直到表达式的末尾)
- 使用此模式后,会忽略正则表达式中的所有空白字符。
例子:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa27 {
public static void main(String[] args) {
String str = "webmaster@itcast.net";
String regex = "\\w+ #username\n" + "@" + "[\\w.]+ #hostname";
//相当于"\\w+@[\\w.]+"
Pattern p = Pattern.compile(regex, Pattern.COMMENTS);//
Matcher m = p.matcher(str);
if (m.find()) {
System.out.println("\"" + str + "\" can be matched with regex \""
+ regex + "\"");
} else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex + "\"");
}
}
}运行结果:
"webmaster@itcast.net" can be matched with regex "\w+ #username
@[\w.]+ #hostname"模式的混合
- 作用:同时使用多个模式。
- 形式:在编译正则表达式时,把表示模式的多个参数以竖线 “|”连接起来。这就是或运算传递多个状态。
例子:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa28 {
public static void main(String[] args) {
String str = "<A HREF=www.itcast.net>\nITCAST\n</A>";
String regex = "<a href=([^>]+)>.*</a>";
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE | Pattern.DOTALL);
Matcher m = p.matcher(str);
if (m.find()) {
System.out.println("\"" + str + "\" can be matched with regex \""
+ regex + "\"");
} else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex + "\"");
}
}
}
运行结果:
"<A HREF=www.itcast.net>
ITCAST
</A>" can be matched with regex "<a href=([^>]+)>.*</a>"然后,这样就能同时使用多个模式。
模式的作用范围
- 作用:精确控制各个模式的作用范围。
- 形式:在表达式中,以(?ismx)的方式启用模式,以(?-ismx)的方式停用模式。
例子1:
public class pa30{
public static void main(String args[]){
String sta="abc";
String regex="(?i)ABC";//没有写(?-i),并且(?i)处于正则的开始,所以就表示整个正则表达式都是忽略大小写的。
if(sta.matches(regex)){
System.out.println("匹配成功!!!");
}
}
}运行结果:
匹配成功!!!然后我们来看看怎么停用作用范围的例子:
public class pa31{
public static void main(String args[]){
String sta="abc";
String regex="(?i)AB(?-i)C";
if(sta.matches(regex)){
System.out.println("匹配成功!!!");
}else{
System.out.println("匹配失败!!!");
}
}
}运行结果:
匹配失败!!!作用范围的多模式匹配
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa32 {
public static void main(String[] args) {
String str = "<A Href=www.itcast.net>\nITCAST\n</A>";
String regex = "(?is)<a href=([^>]+)>.*</a>";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(str);
if (m.find()) {
System.out.println("\"" + str + "\" can be matched with regex \""
+ regex + "\"");
} else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex + "\"");
}
}
}
运行结果:
"<A Href=www.itcast.net>
ITCAST
</A>" can be matched with regex "(?is)<a href=([^>]+)>.*</a>"模式的冲突
- 如果在正则表达式内部,通过模式作用范围指定了模式,而在外部又指定了其他模式参数,则模式作用范围的优先级更高。
例子:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pa33 {
public static void main(String[] args) {
String str = "abc";
String regex = "(?-i)ABC";
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);//
Matcher m = p.matcher(str);
if(m.find()) {
System.out.println("\"" + str
+ "\" can be matched with regex \"" + regex
+ "\"");
} else {
System.out.println("\"" + str
+ "\" can not be matched with regex \"" + regex
+ "\"");
}
}
}
运行结果:
"abc" can not be matched with regex "(?-i)ABC"














 150
150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









