









栈的定义:
限制仅在表的一端进行插入和删除运算的线性表。
可以实现“先进后出(或者叫后进先出)”的存储结构。
栈顶(Top): 允许操作的一端。
栈底(Bottom): 不允许操作的一端。
特点:后进先出。
举例:物流装车,先装车的后出来,后装车的先出来。
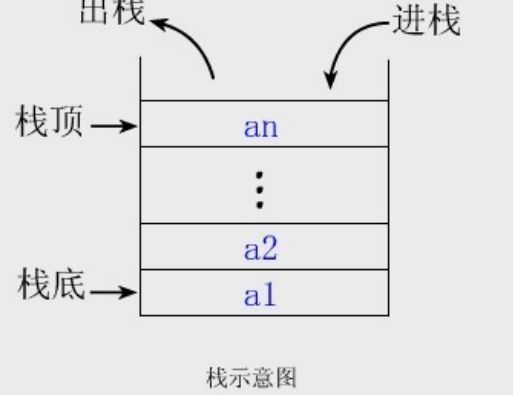
栈的结构:
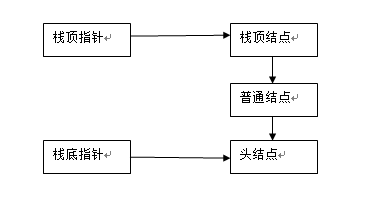
空栈:栈顶和栈顶都指向一个无用的头结点

存有结点的栈:栈顶指针指向栈顶结点,栈底指针指向头结点
栈的三种实现方案:静态数组、动态分配的数组、动态分配的链式结构。
静态数组:长度固定,在编译时确定。优点:结构简单,实现方便。缺点:不够灵活、适用于知道明确长度的场合。
动态数组:长度可在运行的时才确定,并且可以更改原来数组的长度。优点:灵活。缺点:会因此增加程序的复杂性。
链式结构:无长度上限。需要的时候再申请分配内存空间。优点:最灵活。缺点:链式结构的链接字段需要消耗一定内存;在链式结构中访问特定元素效率不如数组。
栈的三种实现:
首先确定一个栈接口的头文件,里面包含了各个实现方案下的函数原型,放在一起是为了实现程序的模块化以及便于修改。然后再分别介绍各个方案的具体实现方法。
静态数组实现栈:
/*
**
** 静态数组实现堆栈程序,数组长度由#define确定
*/
#include <stack.h>
#include <stdio.h>
#include <assert.h>
#define STACK_SIZE 100 /*栈最大容纳元素数量*/
typedef struct Stack{
SElemType data[STACK_SIZE]; /*栈中的数组*/
int top; /*指向栈顶元素的指针*/
}SeqStack;
/*init stack*/
void InitStack(SeqStack *S)
{
S->top = 0;
}
/*判断栈是否为空*/
int StackEmpty(SeqStack *S)
{
if(S->top == 0)
return 1;
else
return 0;
}
/*取栈顶元素*/
int GetTop(SeqStack S, SElemType *e)
{
if(S->top <= 0){
printf("当前栈已空\n");
return 0;
}
*e = S.stack[S.top - 1];
return 1;
}
/*将元素e入栈*/
int push(SeqStack *S, SElemType e)
{
if(S->top >= StackSize){
printf("栈满\n");
return 0;
}
S->stack[S->top] = e;
S->top ++;
return 1;
}
/*将栈顶元素出栈,并赋值给e*/
int PopStack(SeqStack *S, SElemType *e)
{
if(S->top == 0){
printf("空栈");
return 0;
}
S->top --;
*e = S->stack[S->top];
return 1;
}
/*栈的长度*/
int StackLength(SeqStack S){
return S.top;//存储着数据的部分是0到top-1,入栈时,如果栈未满,则在top处存入数据,然后top++
}
/*清空栈*/
void ClearStack(SeqStack *S){
S->top = 0;
}
/*判断栈是否为空*/
int isEmpty(SeqStack *S)
{
return S->top == 0;
}
/*判断栈是否满*/
int isFull(SeqStack *S)
{
return S->top == StackSize;
}
动态分配的数组实现栈:并用栈解决禁止转换问题:(十进制转二进制或八进制)
#include<stdio.h>
#include<stdlib.h>
#define STACK_INIT_SIZE 10 //定义最初申请的内存大小
#define STACK_INCREMENT 2 //每一次申请内存不足的时候扩展的内存大小
#define OVERFLOW 0
#define FALSE 0
#define TRUE 1
#define ERROR 0
#define INFEAIBLE 0 //不可实行的
#define OK 1
typedef int SElemType;
typedef int Status;
int Length;
/*****************结构类型部分******************/
typedef struct Stack
{
SElemType *base;
SElemType *top;
int stacksize;
}SqStack; //sequence stack顺序栈
/*****************构造一个空栈**********************/
Status InitStack(SqStack &S)
{
if( !( S.base = (SElemType *)malloc( STACK_INIT_SIZE * sizeof(SElemType) ) ) )
exit(OVERFLOW); //存储分配失败
S.top = S.base;
S.stacksize = STACK_INIT_SIZE; //初始栈容量
return OK;
}
/******************压入栈元素*********************/
Status Push(SqStack &S, SElemType e)//这里不是SElemType &e
{
//栈满追加内存
if(S.top - S.base >= S.stacksize){
S.base = (SElemType *) realloc(S.base, sizeof(SElemType) * (S.stacksize + STACK_INCREMENT));
if(!S.base)
exit(OVERFLOW);
//给SqStack的三个对象赋值
S.top = S.base + S.stacksize;
S.stacksize += STACK_INCREMENT;
}
*S.top++ = e;//先把e压入栈顶,S.top再增加1指向栈顶元素e的下一个位置
return OK;
}
/******************输出栈元素*********************/
void PrintList(SqStack S)
{
S.top = S.base;
for( int i = 0; i< Length; i++){
printf("%d\n",*(S.top) ++);
}
}
/******************判断栈是否为空*****************/
Status StackEmpty(SqStack S)
{
if(S.base == S.top) return true;
else return false;
}
/******************删除栈顶元素*******************/
Status Pop(SqStack &S, SElemType &e)
{
//判断是否为空
if( S.base == S.top ) return ERROR;
e = *--S.top;
return OK;
}
/********************进制转换********************/
int conversion(unsigned int n,unsigned int m)//十进制数转化成m进制
{
SqStack s;
InitStack(s);
int e = 0;
unsigned result = 0;
while(n)
{
Push(s, (SElemType)n%m);
n /= m;
}
while( !StackEmpty(s))
{
Pop(s,e);
result = result*10 + e;
}
return result;
}
int main()
{
int n = 123;
int m = 2;
int result = conversion(n,m);
printf("%d\n", result);
return 0;
}















 5977
5977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









