









定义
逐层归一化(Layer-wise Normalization)是将传统机器学习中的数据归一
化方法应用到深度神经网络中,对神经网络中隐藏层的输入进行归一化,从而使
得网络更容易训练。
为什么需要归一化
- 缓解内部协变量偏移问题【具体解释看这个】
- 简单来说,层层网络,各种变换,数据分布会带来很大变化, 就是每一点偏移累计起来就多了。使得高层需要很精细的训练才能适应底层。
- 使得输入处于不饱和区域,缓解梯度消失问题,更平滑更稳定——更大的学习率,更快收敛
有哪些归一化的方式?
1、Batch Normalization
-
归一化的对象:
经过线性变换后,激活函数之前的该层净输入 z ( l ) z^{(l)} z(l)。
a ( l ) = f ( z ( l ) ) = f ( W a ( l − 1 ) + b ) a^{(l)} = f(z^{(l)}) = f(Wa^{(l-1)}+b) a(l)=f(z(l))=f(Wa(l−1)+b) -
归一化的方式:
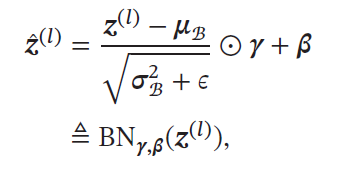
其中:
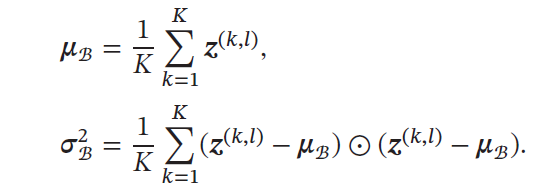
K就是Batch size。可以看作在每一层输入和上一次输出之间加了一个新的计算层,对于数据分布进行额外的约束,从而提升模型的泛化能力。 -
为什么标准化后还要进行缩放和平移?
标准归一化会使得其取值集中到0 附近,降低模型的拟合能力。同时,如果使用Sigmoid 型激活函数时,这个取值区间刚好是接近线性变换的区间,减弱了神经网络的非 线性性质,破坏了模型之前学习到的特征分布.因此,为了使得归一化不对网络的表示能力造成负面影响,可以通过一个附加的缩放和平移变换改变取值区间 -
注意的点:
- 因为BN本身就有平移,所以再次经过激活函数时,不需要加上偏置参数 b b b。
- 训练时,每个Batch的 μ B \mu_B μB和方差 σ B 2 \sigma^2_B σB2是净输入 z ( l ) z^{(l)} z(l)的函数,不是参量,再计算梯度时也要考虑到。
- 训练完成,推断时,可以用整个数据集上的均值和方差做代替。实践中, μ B \mu_B μB和 σ B 2 \sigma^2_B σB2也可以用移动平均来计算【啥意思?】
-
作用:提高优化效率,隐形的正则化方法。因为归一化时,用到该Batch的其他样本的信息,再加上选取构建Batch具有随机性,使得网络不会过拟合到具体某个样本,一定程度提高泛化能力
-
存在的问题
- BN操作的效果受batchsize影响很大,如果batchsize较小,每次训练计算的均值方差不具有代表性且不稳定,甚至使模型效果恶化。
- BN很难用在RNN这种序列模型中(神经元的净输入的分布在神经网络中是动态变化的),难以应用(句子长度不等),就算Padding了效果也不好
2、Layer Normalization
层归一化是对一个中间层的所有神经元进行归一化
- 公式化描述,对于
z
(
l
)
z^{(l)}
z(l):
层归一化的定义为:
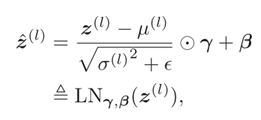
其中:
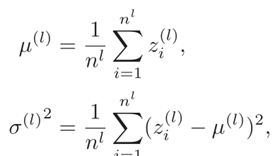
- LN v.s. BN

LN无需考虑batch,就是在这个样本上进行归一化,BN是对于每个batch进行归一化
再看这张图:

从前两幅图,N是Batch size就能很清晰的看到BN 与LN的差异。
- 经验:.一般而言,批量归一化是一种更好的选择.当小批量样本数量比较小时,可以选择层归一化。
NLP:BN还是LN?
首先是几点:
- 从模型角度,RNN中LN效果更好,CNN中BN效果更好。
- 从领域角度,NLP中用LN更多。在Transformer中使用的是LN。
为什么?
从网上摘录的几个观点。主要是知乎上的这个问题:
-
BN为什么不好?
- 如果将transformer中换成BN,batch统计量和其贡献的梯度都会呈现一定的不稳定
-
LN为什么好?
- 一方面通过使得前向传播的输入分布变得稳定;另外一方面,使得后向的梯度更加稳定。二者相比,梯度带来的效果更加明显一些。
-
结合两者:
- mean 和 bias 带来的梯度对于 Transformer 模型的训练很重要,所以需要好的一个 estimation,而 Batch Normalization 无法提供较好的一个估计,从而造成不太 work。
-
从领域数据的角度:
- CV图像数据的编码是本身就有的(像素),NLP的embedding是模型学习的。
- CV应用场景中,数据在不同channel中的信息很重要,如果对其进行归一化将会损失不同channel的差异信息。
- NLP中不同batch,或者说不同句子关联性不大,embedding是基于上下文的,所以句子内部的信息是有关联的,所以在信息归一化时,对样本内部差异信息进行一些损失,反而能降低方差。
以上都是一些摘录。但这种trick的好坏很难有严格的数学证明。更多是直观理解+实验论证,仅供参考。















 7371
7371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









