







 本文探讨了神经机器翻译(NMT)中遇到的大规模词汇表问题,导致训练复杂度和解码效率降低。为解决此问题,文章提出了Sampled Softmax方法,允许NMT系统使用超大词表。通过采样子集近似计算概率,降低了训练时的计算复杂度和空间开销,同时在WMT14上进行了实验验证。
本文探讨了神经机器翻译(NMT)中遇到的大规模词汇表问题,导致训练复杂度和解码效率降低。为解决此问题,文章提出了Sampled Softmax方法,允许NMT系统使用超大词表。通过采样子集近似计算概率,降低了训练时的计算复杂度和空间开销,同时在WMT14上进行了实验验证。
前言
记录下Sampled Softmax的一些原理,相当于论文
《 On Using Very Large Target Vocabulary for Neural Machine Translation 》的个人读书笔记,语句很不通顺,仅用作个人记录,若是有人有问题 再讨论吧
1 问题
NMT(神经网络系统现在已经得到了极大的发展,但是NMT系统一直存在一个问题,就是如何去应对词表过大的问题。词表过大导致了训练复杂度的提升,以及解码的效率。
为了解决这个问题,这篇文章提出了一种方法去允许NMT系统能够使用超大的词表。
2 介绍
首先介绍了NMT的历史和优点。
在NMT或者相关的系统当中,一般情况下,他的词典构造方法是选择排序最靠前的K个词(Bahdanau K=3000,80000 Sutskever),超过这个数额的词,就通过UNK的形式去表现。同时根据文献,发现如果一个句子当中的UNK数量过多,会造成性能的极具下降.
在本文中,为了解决这个问题,提出了一种近似求解的算法,使得NMT系统可以使用一个较大的词表。并且在WMT14评测上进行了对比试验。
3 .1 NMT模型 经典模型
接下来,就首先简单的介绍下NMT系统的一些基本构架,然后再指出其存在的问题。现在比较流行的NMT系统都是基于Encoder-Decoder架构的,简单来说,就是输入一个源语言的句子,然后Encoder将其编码到一个中间的隐状态h,然后Decoder根据再生成最终的翻译。整个Encoder-Decoder模型在训练时,是根据其机器生成的句子和对照句子最大化其条件对数概率。
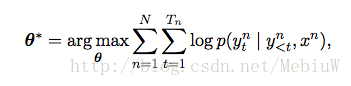
具体来说,在这个框架中,Encoder部分可以采用一个双向的RNN网络来实现,分别从正向和反向将句子输入到RNN网络,每输入一个词,就可以得到两个隐状态h,将他们拼合到一起表示。每一个时间点都会输
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









