







目录
学习目的
应该选择哪种统计方法?|变量有哪些类型?
软件版本
IBM SPSS Statistics 26。
参考文档
困扰
我们学统计常常遇到这样的困扰:上完统计学课,自我感觉良好,考试分数也挺高的。可是到了独立处理数据时,仍茫然不知所措,不能确定自己应该选择哪种统计方法。
什么原因造成的?
统计学的应用一般包括【方法选择—数据处理—结果呈现】三部分。如果你较好地掌握各种统计分析方法的原理、数据操作和结果呈现,虽然这对文科生,特别是体育生来说已经有较大的挑战了,但只学到这一层面是远远不够的。因为,掌握各种具体统计方法,相当掌握一个个统计工具,存储在我们头脑的工具箱中,但面临一大堆科研数据时,却不知怎么从大脑中灵活地提取各种统计方法,服务于科研项目,那么这个工具箱就是一个“无用”箱。本公众号认为:选择统计方法比掌握统计方法更重要,因为选择统计方法是一种全局观,是统计思维的高级体现,而掌握统计方法只是一个技术实现而已。事实上,统计方法的选择是个非常具有艺术性的问题,有难度也有高度。统计分析也是不断尝试、不断思考和判断过程,它不是一锤定音的。比如针对一份连续型数据,我们首先会考虑方差分析,但是分析过程中发现数据不服从正态分布,又改为秩和检验。很多时候,同样的数据可以采用不同的统计方法,而不同的数据也可以采用同一种统计方法,因此,统计方法选择有很强灵活性。
如何破解难题?
面对这一难题,我们在统计方法的选择中要把握其根本:通过研究目的、研究方法和变量类型来综合选择统计方法,在头脑中构建一个脑图(如下图,强烈建议保存)。

简而言之,统计方法选择的策略可概括为两句话:目的引导设计,变量确定方法。
虽然研究目的有很多,但依据统计目的,本脑图将其划分为关联分析和差异比较两大类。同样,研究设计也有多种,主要包括调查法和实验法。其中关联分析一般采用调查法实现的,包括相关分析和回归分析两大统计方法;而差异比较一般采用实验法来实现的,大致包括t检验、F检验、卡方研究和秩和检验四大统计方法。如此,可将研究设计与统计方法契合在一起,有个全局观,这就是【目的引导设计】。当然,具体采用何种统计方法,还会涉及到有多少个变量,是否重复测量、连续变量的正态分布和方差齐性等因素,但最主要考虑的因素是变量类型,变量类型包括分类变量、有序变量和连续型变量。为此,脑图依据变量类型,将各种统计方法嵌入到各种变量类型中,也就是【变量确定方法】。
脑图有何指导作用?
Q1: 脑图包括所有统计方法吗?答:没有。统计方法有100多种,脑图只列举了常规的统计方法,未涉及一些高级统计方法,比如多因素方差分析,多元方差分析,因子分析等。
Q2:各统计方法的使用条件都齐全吗?答:没有。脑图主要依据研究目的,研究设计和变量类型主要因素来确定常用统计方法。一些简单的统计方法的使用条件基本齐全,而一些较复杂的统计方法,比如多因素线性回归分析,需要满足线性、独立性、正态性和方差齐性,以及避免多重共线性等条件,没有一一列举。
Q3:既然都不齐全,我们该如何选择统计方法呢?答:脑图主要起抛砖引玉作用,提供一个统计思维的全局观。提示我们在选择统计方法时,需要依据研究目的、研究设计、变量类型,以及连续变量正态性、方差齐性等角度去选择统计方法。至于一些复杂统计分析方法需要进一步加强学习,需要我们依据具体情况逐步完善脑图,或者咨询统计专家。在此,我呼吁,在撰写研究方案时,需要将统计分析策略纳入研究方案中,而且要写详细,考虑到各种统计方法的使用条件。比如:本研究拟采用单因素方差分析,如果数据不满足正态分布,将采用秩和检验;如果方差不齐,则采用Welch检验……,如果方差分析结果显著,则采用XX多重平均数比较……只有这样,统计才学到家,拿到数据后才能胸有成竹,应对自如。
本公众号后续将依托上述脑图,从研究设计、研究目的和变量类型的视角,逐步讲解各种常规统计方法原理、数据操作和规范表达,让你对统计方法有一个新的全局观,敬请关注!
统计策略| 变量有哪些类型?向《西游记》取经
统计学习的方法很多,今天我们就从《西游记》中取经,学习变量类型。
之前一篇推文“一张脑图搞定!统计方法选择”中提到,“变量确定方法”。作为统计的初学者,一定要掌握变量类型。
01 什么是变量?
简而言之,变量就是变化的数量。比如,你的心跳忽高忽低变化,你口袋里的钱,忽多忽少变化,这里的心跳和钱就是变量。那么变量有什么用呢?变量的本质就是一个量,也就是说变量里只装数据。比如,我们收集到教练员的月收入,张三1.3万,李娟0.9万……。收集好之后,把这一列数据排成一列。给这个变量命个名,叫“收入变量”。
当然,我们还不止只收集教练员的收入,我还要收集他们性别,年龄等。这些变量组合在一起,就组成了一个表格。表格有很多行,也有很多列。通常说行代表ID。对教练员的数据来说,行就是一个一个人,张三占一行,李娟占一行。列就是一个个变量,姓名、性别、年龄和收入等。图片聪明的你可能发现,性别这个变量有些特殊。一般而言,性别为男性或者女性,这不是数字。可是,变量只能装数据的呀。怎么办呢?是个小麻烦。这时候,我们要学会“编码”。编码的意思就是,我们规定男性编码为0,女性编码为1。就可以用0和1代替性别变量中的男男女女。同理也可以对每名教练员姓名进行编码,分别用1 2 3 4代替姓名。
你可能还会问,为什么一定要把男性编码为0呢?可不可以反过来把女性编码为0,男性编码为1呢?当然可以随便编,你还可以把男性编码为250,把女性编码为520。可是,你这么做,别人可能不太容易理解,也不利于后期处理,处理过程还容易出错,你何必把编码弄得这么复杂。所以,编码以简单、方便容易理解为原则。这样我们有三层概念:数据——变量——表格。数据的级别最低,是一个变量的具体数值;变量是一组数据的集合,代表事物一个维度的信息;表格的级别最高,是各个变量,也就是事物各个维度信息的集合。
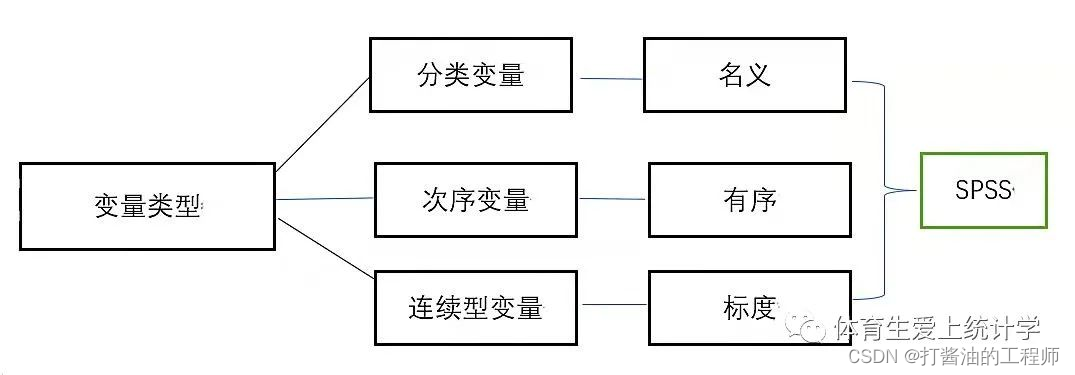
02 变量有哪些类型?
搞明白了这一点,接下来就可以学习变量类型了。我们别看现实世界的数据千差万别,归类方法也多种,在统计学中,我们将其归为三大类,分别是 分类变量、次序变量和连续型变量。由于变量就是变化的数值,所以有些教材中也将其称之为分类数据、次序数据和连续型数据。听起来有很多陌生名词,好像很难记。宣明栋老师在《数据思维课》借鉴了《西游记》人物来帮助大家理解变量类型,我也效仿之。《西游记》的取经队伍有四位,我们借用三位就好了,分别是唐僧、沙和尚和孙悟空。图片第一种:分类变量,“唐僧变量”。
我们知道,唐僧的思维是非此即彼的、非黑即白,给所有的东西分类,不是行,就是不行,不是好人,就是坏人,没有中间状态。分类变量也是这样。典型的就是性别,相同的还有民族、婚姻状况、出过国没有出过国等,都是分类变量,它没有大小之分,只有区别功能。依据分类数量,我们可以分成二分类变量和多分类变量。像性别分成男、女,属于二分类;而血型分成A、B、O、AB四大类,属于多分类变量。
虽然“分类”这个概念挺简单,但还是要提示一点——设置分类既要完备,又要排他。举个例子。我们填各种表时,经常有一项“婚姻状况”,一般会有四个选项——未婚、已婚、离婚和丧偶。完备是指这四个选项包括所有婚姻状态;而排他是指这四个选项相互排斥,不存在交叉。如果在婚姻状况中添加“同居”这个选项,那么它会与未婚和离婚这两个选项存在交叉。因为有人可能是未婚同居,也可能离婚同居,让人无法填写。第二种:次序变量,“沙和尚变量”。
为什么叫沙和尚变量呢?因为沙和尚工作都要找领导。唐僧在的时候,就找唐僧;唐僧被抓了,就找大师兄孙悟空;孙悟空不在了,就找二师兄猪八戒。你看,特别有次序。图片
比如这样提问:“我特别喜欢运动,这句话符合你吗”,是非常符合、符合、不确定、不符合,还是非常不符合呢?这个问题测量出来的结果就是次序数据。本质上,次序变量还是分类变量,但是多了一个大小顺序的信息。所以有些教材分成将次序变量称为有序分类变量,而分类变量称为无序分类变量。注意,次序变量只能说明几个选项是有顺序的,只有大小之分,而不关心选项之间差距是否相同。就像刚才那个问题,回答“非常符合”和“符合”之间、“符合”和“不确定”之间,程度是否相同,是无法确定的。第三种:连续型变量,“孙悟空变量”。
为什么是孙悟空呢?因为孙悟空的武器是金箍棒,可以任意放大缩小。它可以取任意数值。比如我们月收入变量,可以取5000, 5001,甚至可以取5001.1元任意数值。图片
连续型变量的特征是,各种数据之间不但有大小之分,而且还有相同间隔,比如2000元、3000元和4000元的之间的间隔是相等的,而且还可以做乘除运算,比如4000元收入是2000元收入的两倍。小结一下:变量一共有三种类型,分别是分类变量、次序变量、连续型变量,分别对应唐僧、沙和尚和孙悟空。在SPSS软件中,这三类变量就对应了名义、有序和标度。
03 变量类型有何指导意义?
了解这些变量类型,我认为至少有两方面作用。第一,能指导我们收集数据比如收入变量,本来是连续型变量,但如果把收入划分成四个档次——贫困人口、工薪阶层、中产阶级和富人群体,连续型就变成了次序变量。但是,反过来就不行。先有工薪阶层、中产阶级这些有序分类变量之后,就没有办法转化为收入的连续型数据。这就叫向下兼容。向下兼容的本质是说,从分类变量、次序变量和连续型变量。越往后,变量拥有的信息越多;反之,就是一个丢失信息的过程。这也给我们一个提示:收集数据的时候,尽量多收集连续型数据,以后需要的话可以向下转换。第二,能指导我们选择统计方法简单取个例子,得到教练员的收入情况,这是连续型变量,我们就可以计算平均值,比较收入的高低。但如果是得到教练员的性别呢?这是分类变量,计算平均性别就很荒谬了。
更重要的是,变量指导我们统计方法,详细请查看之前的推文,一张脑图搞定,统计方法选择。最后,虽然我想说的是,尽量多收集连续型数据,但也不是说连续型变量就比其他变量更好。每一种类型的数据都有它的用处,这里没有鄙视链。现在已经进入了大数据时代,大量的数据都是类别数据,比如打开还是关闭,是否完整阅读完这篇推文,是否点击本文后面的广告等。把这些数据组合起来,同样能提供大量的信息。就像唐僧一样,虽然他打妖怪没啥功劳,还经常惹事,但每当遇到困难时,就采用二分类变量思维,目标明确,坚定地说:“徒弟们,别往东看了;咱们向西出发,走起”
划重点、
1.变量就是变化的数量。数据是一个变量的具体值,变量代表一个维度的信息,表格是各种维度信息的集合。
2.变量可分为分类变量、次序变量和连续型变量。其中,分类变量只能用于区别;次序变量能比较大小;连续型变量具有等距离和等比例特性。
3.了解变量类型,可指导我们收集数据和选择统计方法。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









