







1.多层装饰器
Python的装饰器原理能够在不破坏函数原本结构的基础上,加入新的功能创新。当我们需要对一个函数补充不同的功能,可能需要用到多层的装饰器,接下来给大家演示一个多层装饰器的解题思路。
'''注意语法糖会将下面紧挨着的函数当作参数传递给@符号后面的函数名运行'''
def outter1(func1): 12.这个时候func1就接到了wrapper2的函数名了
print('加载了outter1') 13.打印加载outter1
def wrapper1(*args, **kwargs): 14.在创建新的wapper1 return
print('执行了wrapper1') 16.打印wrapper1
res1 = func1(*args, **kwargs) 17.遇到括号优先执行 这个时候的fun1是wrapper2所以直接跳到wrapper2
return res1
return wrapper1 15. 返回 wrapper1
def outter2(func2): 07.所以这个时候的func2就是wrapper3
print('加载了outter2') 08.打印加载outter2
def wrapper2(*args, **kwargs): 09.然后定义了wrapper2 下一步return
print('执行了wrapper2') 18.打印wrapper2
res2 = func2(*args, **kwargs) 19.func2就是wrapper1
return res2
return wrapper2 10.这个时候返回wrapper2就是index返回了
def outter3(func3): 02.这个时候fun3是真的index 运行fun3函数
print('加载了outter3') 03.打印加载了outter3 函数定义不用看代码函数体代码 所以下一步 return
def wrapper3(*args, **kwargs):
print('执行了wrapper3') 20.打印wrapper3
res3 = func3(*args, **kwargs) 21.func3就是index跳到index
return res3
return wrapper3 04.所以这时候index的返回值就是wrapper3 这个时候wrapper就成了函数名 再次触发 outter2
@outter1 11.这个时候index就到了outter1在运行outter1 15.这个时候就变成伪装的 index = routter1(wrapper2)
@outter2 06.所以这个时候wrapper3会传到outter2里面在运行
@outter3 01.这个时候就会把真正的index传给outter3 所以 outer3(index) 括号优先级执行 05.所以这个时候就是 wrapper3 = outter3(index)
def index():
print('from index') 22.结束
index()
2.有参装饰器
现在我们有一个已经设置好了的用户登录校验的函数,但是我们想知道这个用户的数据来源来自哪里?已知有了列表、字典、文件所以我们该用什么来实现呢?就需要用到有参装饰器啦!
'''这是已知的用户登陆函数'''
def login_auth(func_name):
def inner(*args, **kwargs):
username = input('username>>>:').strip()
password = input('password>>>:').strip()
if username == 'meijin' and password == '123':
res = func_name(*args, **kwargs)
return res
else:
print('用户权限不够 无法调用函数')
return inner
--------------------------------------------------------------------------------------------------------
def outer(condition,type_user):
def login_auth(func_name): # 这里不能再填写其他形参
def inner(*args, **kwargs): # 这里不能再填写非被装饰对象所需的参数
username = input('username>>>:').strip()
password = input('password>>>:').strip()
# 应该根据用户的需求执行不同的代码
if type_user =='meijin':
print('使用vip方式作为数据来源 比对用户数据')
if condition == '列表':
print('使用列表作为数据来源 比对用户数据')
elif condition == '字典':
print('使用字典作为数据来源 比对用户数据')
elif condition == '文件':
print('使用文件作为数据来源 比对用户数据')
else:
print('去你妹的 我目前只有上面几种方式')
return inner
return login_auth
@outer('文件','jason')
def index():
print('from index')
index()
3.递归函数
递归函数的概念
函数直接接调用了自己或者是间接使用了自己就是递归调用
ex:
def index(): 在全局寻找index 无限循环
print('from index') 上面说法其实也是错误的
index() 不会无限循环 python的循环次数是有限的
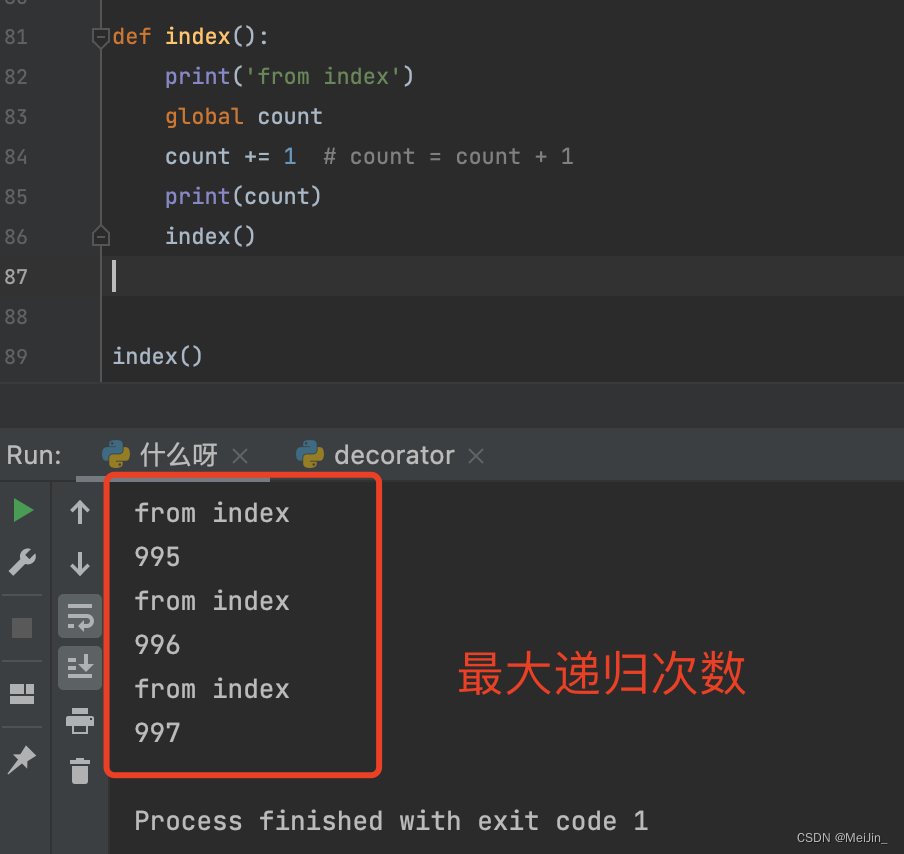
index() 官方给出的限制是1000 用代码去验证可能会有些许偏差(997 998...)
那我们就在测试测试:
count = 1 计数器默认=1
def index(): 创建一个函数index
print('from index') 打印from index
global count global 修改全局空间中的变量名
count += 1 # count = count + 1 运行一次+1
print(count)
index() 调用index 进入循环
index()
小技巧:
import sys 倒入系统板块
print(sys.getrecursionlimit()) 内置方法. 1000是递归最大次数
sys.setrecursionlimit(2000) 可以自定义最大次数
print(sys.getrecursionlimit())
递归函数真正的应用场景
递推:一次次寻找答案直到找到答案
回溯:根据最终答案在向回推导找到答案
递归函数
1.每次调用的时候都必须感觉要比上一次简单!!!
2.并且递归函数最终都必须要有一个明确的结束条件!!!
ex: 我们已知有一个列表,但是呢我只要里面的数字不要中括号这么获取呢!
就可以用到我们学习的递归函数了
l1 = [1, [2, [3, [4, [5, [6, [7, [8, [9, [10, ]]]]]]]]]]
def get_num(l1):
for i in l1: 循环打印出列表中所有的数据值
if isinstance(i,int): 判断当前对象数据值是否是数字
print(i) 如果是则打印
else:
get_num(i) 如果不是则继续循环打印列表剩余列表
get_num(l1)
4.算法之二分法
什么是算法?
算法不是我们想的什么加减乘除上面的算法,而是指能解决问题的方法就是算法
算法永远都在精进 但是很少有最完美的算法
二分法是所有算法里面最简单的算法但是也有人说二分法不是算法
跟二分法类似的还有?
二分法、快拍、插入、堆排、链表、双向链表、约瑟夫问题
比如我们想从下方列表中获取到999的这个数据值 我们用二分法来试试
ex:
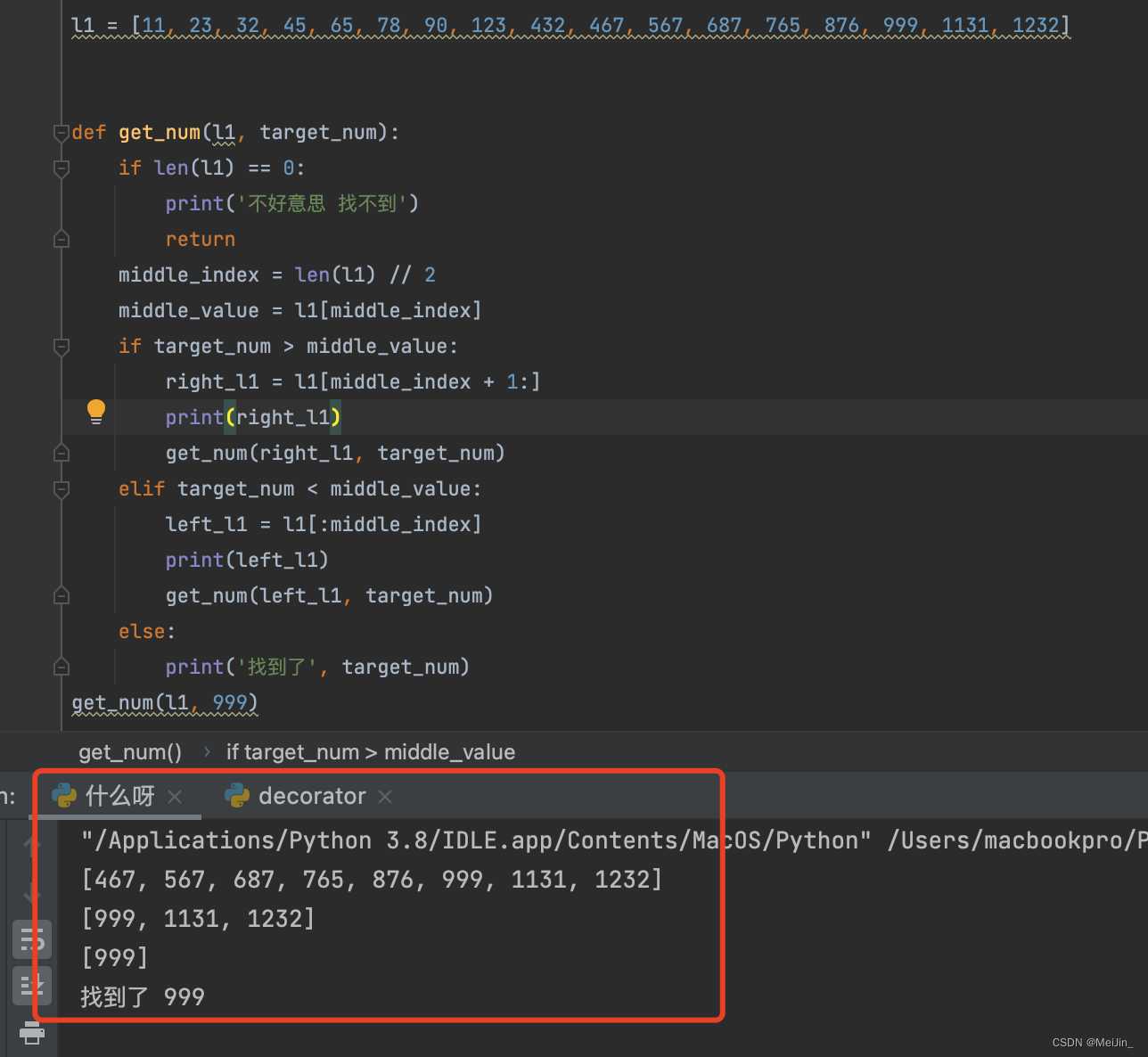
l1 = [11, 23, 32, 45, 65, 78, 90, 123, 432, 467, 567, 687, 765, 876, 999, 1131, 1232]
def get_num(l1, target_num):
if len(l1) == 0: 添加递归函数的结束条件
print('不好意思 找不到')
return
middle_index = len(l1) // 2 获取整个列表中间的值
middle_value = l1[middle_index]
if target_num > middle_value: 判断目标数据值在不在右边的数据值列表里面
right_l1 = l1[middle_index + 1:] 如果数据值在列表的右边再加一位数据继续
print(right_l1) 打印右边截取的列表
get_num(right_l1, target_num) 返回到最开始再次比值看是否在右边继续截取
elif target_num < middle_value: 判断目标数据值在不在左边的数据值列表里面
left_l1 = l1[:middle_index] 用left_l1来接手左边的数据列表
print(left_l1) 打印左边截取的列表
get_num(left_l1, target_num) 返回到最开始再次比值看是否在左边继续比较截取
else:
print('找到了', target_num)
get_num(l1, 999)
















 258
258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











