







一、Source(修改序列化字段名称)
tips:获取所有电影接口
models.py
class Movie(models.Model):
name = models.CharField(max_length=32)
price = models.CharField(max_length=32)
director = models.CharField(max_length=32)
views.py
class MovieView(APIView):
def get(self, request):
movie_list = Movie.objects.all()
ser = MovieSerializer(instance=movie_list, many=True)
return Response(ser.data)
serializer.py
class MovieSerializer(serializers.Serializer):
# name = serializers.CharField(max_length=8, min_length=3)
movie_name = serializers.CharField(max_length=8, min_length=3, source='name') # 给字段取别名 需要加上Source
# name = serializers.CharField(max_length=8, min_length=3,
# source='name') # 如果字段名跟原名称一样则会报错 Remove the `source` keyword argument.
price = serializers.IntegerField(min_value=10, max_value=99, write_only=True) # 只写所以不会显示在前端
director = serializers.CharField(max_length=8, min_length=3, read_only=True) # 只读可以显示在前端
'''
tips: 如果需要字段名需要修改使用Source方法指定模型字段即可
read_only 前端可以显示但是不能写入
whrite_only 前端不能显示但是可以写入
'''
class MovieSerializer(serializers.Serializer):
# name = serializers.CharField(max_length=8, min_length=3)
movie = serializers.CharField(max_length=8, min_length=3, source='name') # 给字段区别名 需要加上Source
name = serializers.CharField(max_length=8, min_length=3, source='six') # source指定的可以是字段 也可以是方法 用于重命名
# name = serializers.CharField(max_length=8, min_length=3,
# source='name') # 如果字段名跟原名称一样则会报错 Remove the `source` keyword argument.
price = serializers.IntegerField(min_value=10, max_value=99, write_only=True) # 只写所以不会显示在前端
director = serializers.CharField(max_length=8, min_length=3, read_only=True) # 只读可以显示在前端
'''
tips:
source可以写指定的字段也可以是方法用于重命名
source还可以做夸表查询source='director.name'
'''
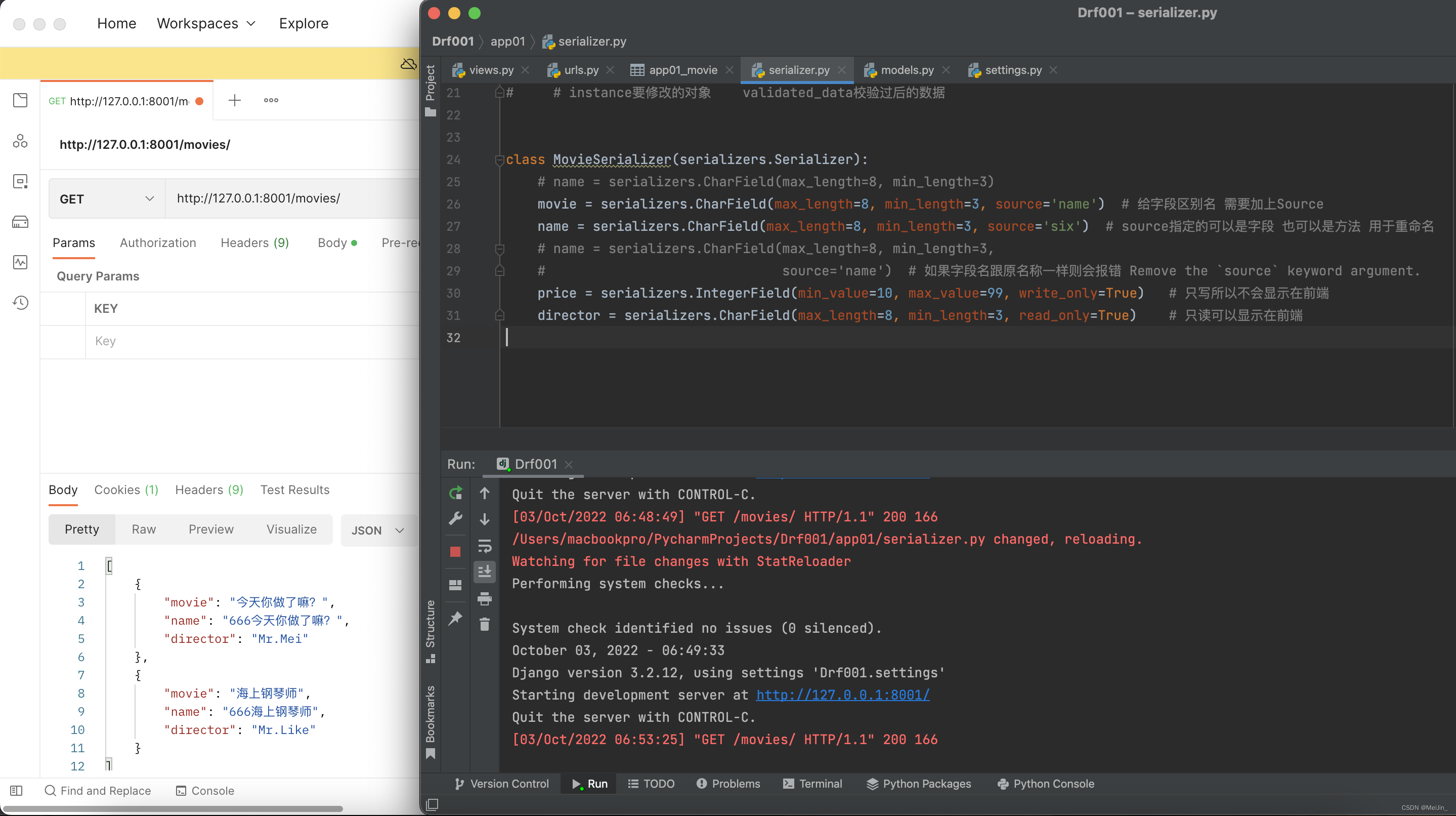
二、定制序列化字段
我们想要序列化的字段前端显示形式是这个样子怎么做呢?
{
"name": "富婆通讯录",
"price": 666,
"publish": {
"name": "湖北出版社",
"city": "湖北武汉",
"email": "110@qq.com"
}
方式1: 在序列化类中写SerializerMethodField
# SerializerMethodField配合字段名 接收一个参数OBJ, 方法返回什么这个字段就是什么
publish = serializers.SerializerMethodField()
def get_publish(self, obj):
# obj 是当前序列化的对象 可以基于对象的夸表查询
return {'name': obj.publish.name, 'city': obj.publish.city, 'email': obj.publish.email}
练习1: 获取所有的作者信息
authors = serializers.SerializerMethodField()
def get_authors(self, obj):
res_list = []
for author in obj.authors.all():
res_list.append({'id': author.id, 'name': author.name, 'age': author.age})
return res_list
方式2: 在表模型中多写一个方法
publish_detail = serializers.DictField() # 注意DictField 如果是CharField就不会美化哦!
def publish_detail(self):
return {'name': self.publish.name, 'city': self.publish.city, 'email': self.publish.email}
练习2: 获取作者信息列表
authors_list = serializers.ListField()
def authros_list(self):
res_list = []
for author in self.authors.all():
res_list.append({'id': author.id, 'name': author.name, 'age': author.age})
return res_list
'''
在表模型中写逻辑代码的行为被称为ddd, 领域驱动模型
'''
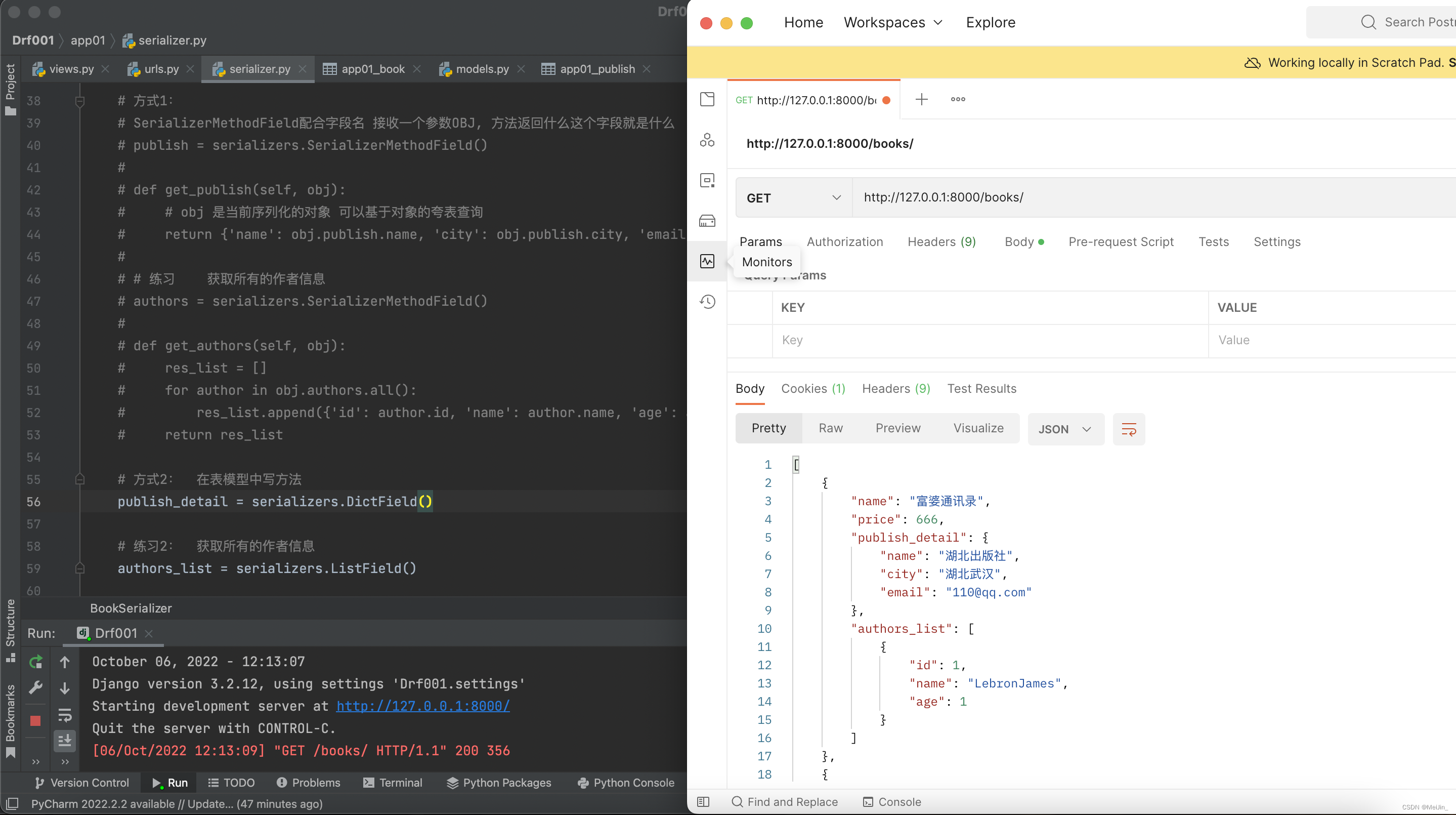
三、反序列化之数据保存
方式1: 使用BookSerializer
views.py
class BookView(APIView):
def get(self, request):
book_list = Book.objects.all()
ser = BookSerializer(instance=book_list, many=True)
return Response(ser.data)
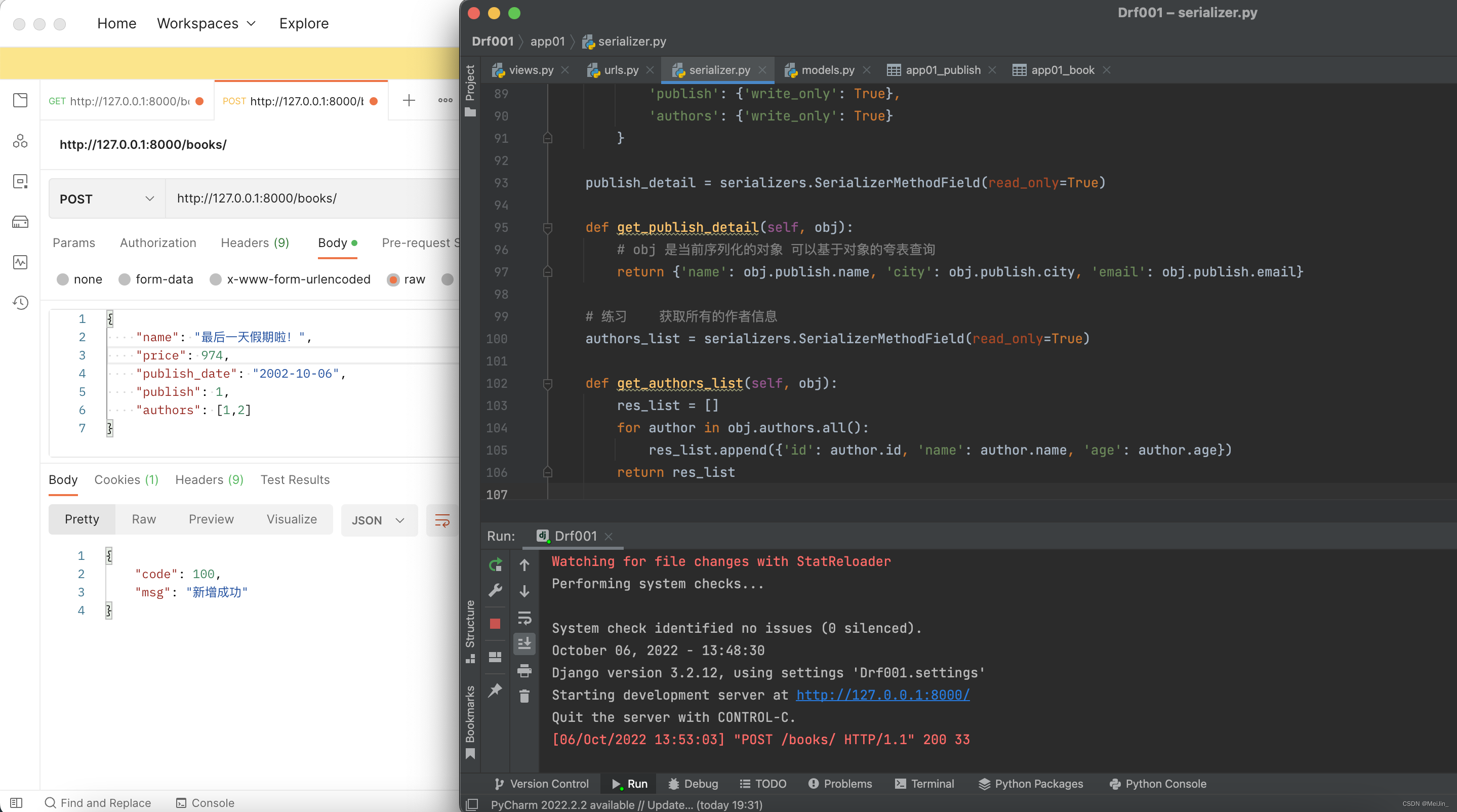
def post(self, request):
ser = BookSerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '新增成功'})
else:
return Response({'code': 101, 'msg': ser.errors})
serializer.py
class BookSerializer(serializers.Serializer):
name = serializers.CharField(max_length=8, min_length=3)
price = serializers.IntegerField(min_value=10, max_value=999)
publish_date = serializers.DateField()
# 主要用于反序列化
publish = serializers.IntegerField(write_only=True)
authors = serializers.ListField(write_only=True)
# 主要用于序列化
publish_detail = serializers.DictField(read_only=True)
authors_list = serializers.ListField(read_only=True)
# 新增或修改必须重写Create & Update
def create(self, validated_data): # validated_data 是校验过后的数据
book = Book.objects.create(
name=validated_data.get('name'),
price=validated_data.get('price'),
publish_date=validated_data.get('publish_date'),
publish_id=validated_data.get('publish')
)
authors = validated_data.get('authors')
book.authors.add(*authors)
return book
'''
但是现在写到这些都比较麻烦 每个字段都需要写 无论是新增或者是修改 解决这个可以使用ModelSerializer
'''
方式2: 使用ModelSerializer
views.py
class BookView(APIView):
def get(self, request):
book_list = Book.objects.all()
# ser = BookSerializer(instance=book_list, many=True)
ser = BookModelSerializer(instance=book_list, many=True)
return Response(ser.data)
def post(self, request):
# ser = BookSerializer(data=request.data)
ser = BookModelSerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '新增成功'})
else:
return Response({'code': 101, 'msg': ser.errors})
serializer.py
class BookModelSerializer(serializers.ModelSerializer):
# 不用写字段了 字段都是从表模型中映射出来
class Meta: # 内部类
model = Book # 必须model 这个序列化类与表模型建立了映射关系
# fields = '__all__' # 序列化那些字段 all全部
fields = ['name', 'price', 'publish_date', 'publish', 'authors', 'publish_detail',
'authors_list'] # 列表中有什么 就是序列化的字段
extra_kwargs = { # 给字段authors和publish添加write_only属性参数
'publish': {'write_only': True},
'authors': {'write_only': True}
}
publish_detail = serializers.SerializerMethodField(read_only=True)
def get_publish_detail(self, obj):
# obj 是当前序列化的对象 可以基于对象的夸表查询
return {'name': obj.publish.name, 'city': obj.publish.city, 'email': obj.publish.email}
# 练习 获取所有的作者信息
authors_list = serializers.SerializerMethodField(read_only=True)
def get_authors_list(self, obj):
res_list = []
for author in obj.authors.all():
res_list.append({'id': author.id, 'name': author.name, 'age': author.age})
return res_list
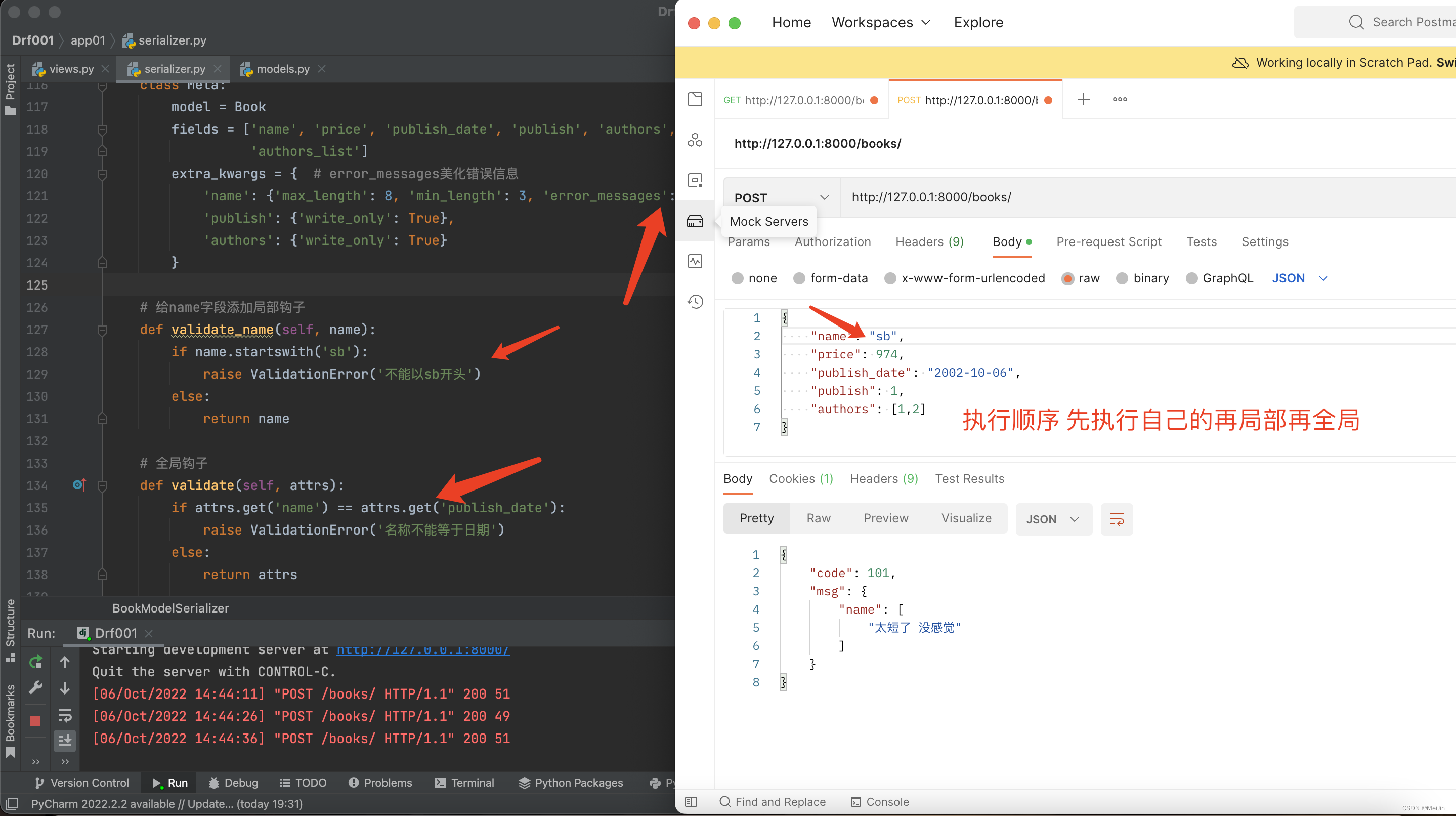
四、反序列化之数据校验
from rest_framework.exceptions import ValidationError
class BookModelSerializer(serializers.ModelSerializer):
如果继承的是Serializer 写法如下
# name = serializers.CharField(max_length=8, min_length=3, 'error_messages'={'min_length': '太短了 没感觉'})
如果是ModelSerializer 写法如下
class Meta:
model = Book
fields = ['name', 'price', 'publish_date', 'publish', 'authors', 'publish_detail',
'authors_list']
extra_kwargs = { # error_messages美化错误信息
'name': {'max_length': 8, 'min_length': 3, 'error_messages': {'min_length': '太短了 没感觉'}},
'publish': {'write_only': True},
'authors': {'write_only': True}
}
给name字段添加局部钩子
def validate_name(self, name):
if name.startswith('sb'):
raise ValidationError('不能以sb开头')
else:
return name
全局钩子
def validate(self, attrs):
if attrs.get('name') == attrs.get('publish_date'):
raise ValidationError('名称不能等于日期')
else:
return attrs
五、模型类序列化器的使用
'''其实就是我们上面知识点3中的第二种方法就是模型类序列化器的使用'''
class BookModelSerializer(serializers.ModelSerializer):
# 不用写字段了 字段都是从表模型中映射出来
class Meta: # 内部类
model = Book # 必须model 这个序列化类与表模型建立了映射关系
# fields = '__all__' # 序列化那些字段 all全部
fields = ['name', 'price', 'publish_date', 'publish', 'authors', 'publish_detail',
'authors_list'] # 列表中有什么 就是序列化的字段
extra_kwargs = { # 给字段authors和publish添加write_only属性参数
'publish': {'write_only': True},
'authors': {'write_only': True}
}
publish_detail = serializers.SerializerMethodField(read_only=True)
def get_publish_detail(self, obj):
# obj 是当前序列化的对象 可以基于对象的夸表查询
return {'name': obj.publish.name, 'city': obj.publish.city, 'email': obj.publish.email}
# 练习 获取所有的作者信息
authors_list = serializers.SerializerMethodField(read_only=True)
def get_authors_list(self, obj):
res_list = []
for author in obj.authors.all():
res_list.append({'id': author.id, 'name': author.name, 'age': author.age})
return res_list
'''
# 如何使用
1 定义一个类继承ModelSerializer
2 类内部写内部内 class Meta:(必须大写)
3 在内部类中指定model(要序列化的表)
4 在内部类中指定fields(要序列化的字段,写__all__表示所有,不包含方法,写[一个个字段])
5 在内部类中指定extra_kwargs,给字段添加字段参数的
6 在序列化类中,可以重写某个字段,优先使用你重写的
name = serializers.SerializerMethodField()
def get_name(self, obj):
return 'sb---' + obj.name
7 以后不需要重写create和update了
-ModelSerializer写好了,兼容性更好,任意表都可以直接存
'''
六、反序列化数据校验源码分析
# 先校验字段自己的规则(最大,最小),走局部钩子校验,走全局钩子
# 局部:validate_name,全局叫:validate 为什么?
# 入口:从哪开始看,哪个操作,执行了字段校验ser.is_valid()
-BaseSerializer内的is_valid()方法
def is_valid(self, *, raise_exception=False):
if not hasattr(self, '_validated_data'):
try:
# 真正的走校验,如果成功,返回校验过后的数据
self._validated_data = self.run_validation(self.initial_data)
except ValidationError as exc:
return not bool(self._errors)
-内部执行了:self.run_validation(self.initial_data)---》本质执行的Serializer的
-如果你按住ctrl键,鼠标点击,会从当前类中找run_validation,找不到会去父类找
-这不是代码的执行,代码执行要从头开始找,从自己身上再往上找
def run_validation(self, data=empty):
#局部钩子的执行
value = self.to_internal_value(data)
try:
# 全局钩子的执行,从根上开始找着执行,优先执行自己定义的序列化类中得全局钩子
value = self.validate(value)
except (ValidationError, DjangoValidationError) as exc:
raise ValidationError(detail=as_serializer_error(exc))
return value
-全局钩子看完了,局部钩子---》 self.to_internal_value---》从根上找----》本质执行的Serializer的
def to_internal_value(self, data):
for field in fields: # fields:序列化类中所有的字段,for循环每次取一个字段对象
# 反射:去self:序列化类的对象中,反射 validate_字段名 的方法
validate_method = getattr(self, 'validate_' + field.field_name, None)
try:
# 这句话是字段自己的校验规则(最大最小长度)
validated_value = field.run_validation(primitive_value)
# 局部钩子
if validate_method is not None:
validated_value = validate_method(validated_value)
except ValidationError as exc:
errors[field.field_name] = exc.detail
return ret
# 你自己写的序列化类---》继承了ModelSerializer---》继承了Serializer---》BaseSerializer---》Field
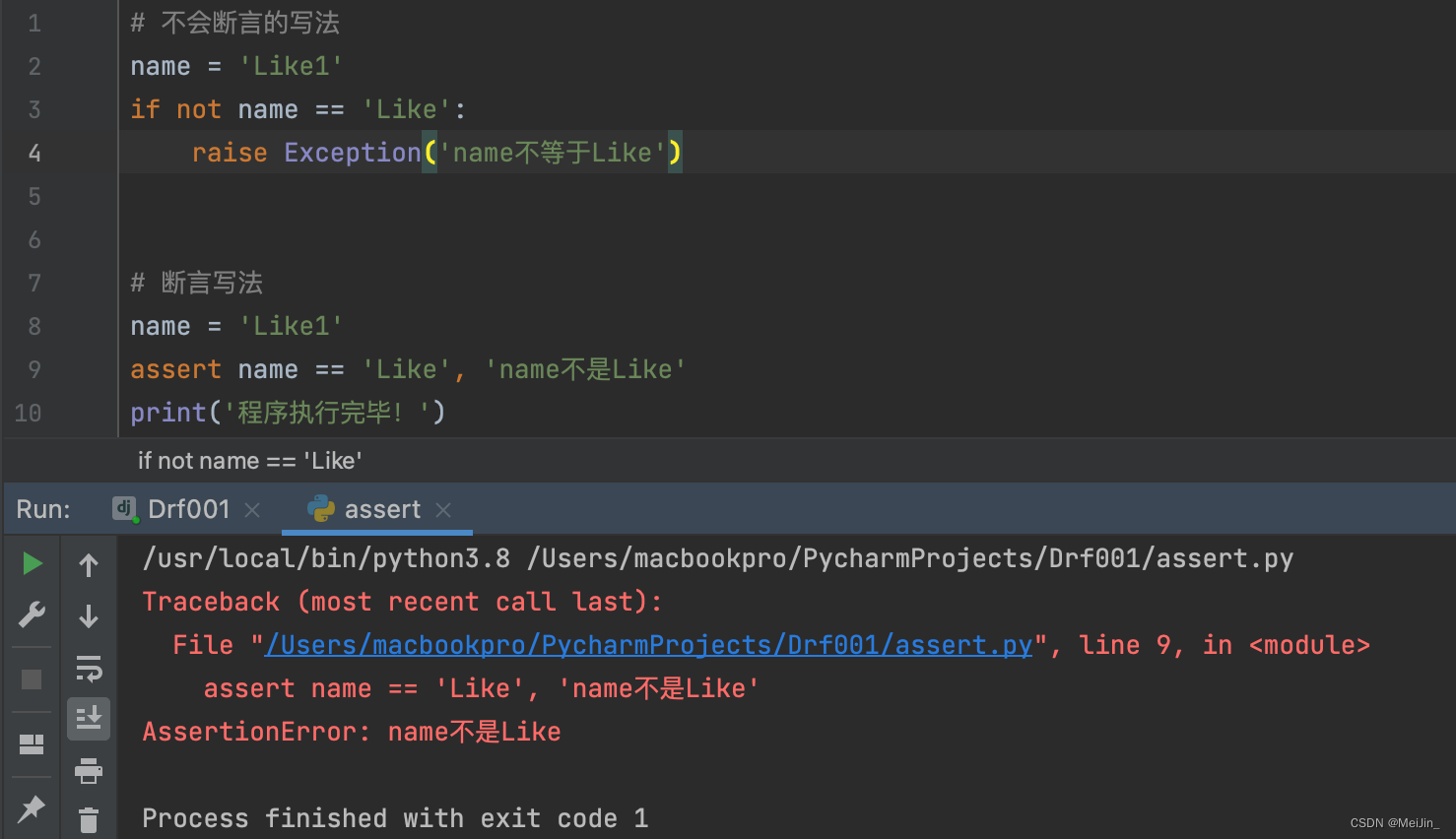
七、断言Assert
# 不会断言的写法
name = 'Like1'
if not name == 'Like':
raise Exception('name不等于Like')
# 断言写法
name = 'Like1'
assert name == 'Like', 'name不是Like'
print('程序执行完毕!')
技术小白记录学习过程,有错误或不解的地方请指出,如果这篇文章对你有所帮助请
点点赞收藏+关注谢谢支持 !!!
















 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











