







ACM SIGIR 2020是由国际计算机学会ACM主办的信息检索方向的国际顶会。会议每年召开一次,专注于信息检索领域,涉及理论基础、算法、应用和评估分析等方向。今年是第43届,于7月25日-30日举行,受疫情影响原定于西安召开的SIGIR2020转到了线上召开。
北京时间7月29日上午,美团在SIGIR2020会议中举办了自己的Workshop,同时邀请到美团AI平台的王金刚、到店广告平台技术部的胡可以及外卖技术部的胡懋地三位讲师做了精彩分享。以下系三位讲师演讲内容的总结:

王金刚
TALK1 MT-BERT: Best Practices of Pre-trained Language Models at Meituan
王金刚在报告中,主要介绍美团NLP团队基于美团业务语料训练的预训练语言模型MT-BERT以及在美团业务场景中的应用。
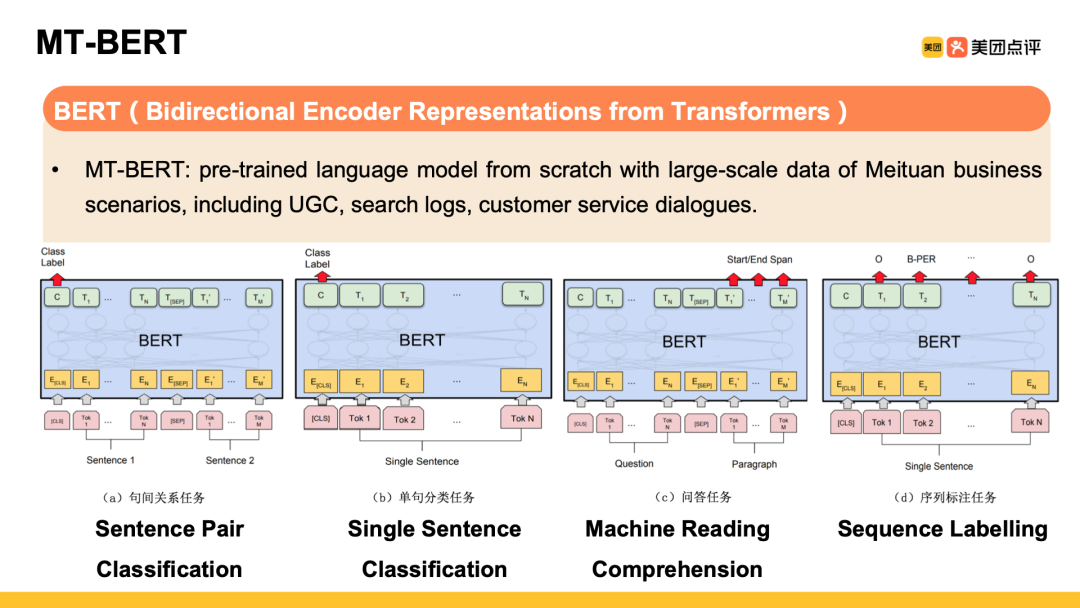
报告首先简要回顾了以BERT为代表的预训练语言模型的发展历程。2018年底以Google BERT为代表的预训练语言模型刷新了多项NLP任务的最好水平,开创了NLP研究的新范式:即先基于大量无监督语料进行语言模型预训练(Pre-training),再使用少量标注语料进行微调(Fine-tuning)来完成下游NLP任务(文本分类、序列标注、句间关系判断和机器阅读理解等)。
2019年底,Google在其官方博客上宣布基于BERT可以更好地理解用户搜索需求,改善了10%的英文搜索结果。国内外主流互联网公司也都基于各自业务场景开展预训练工作并应用到不同业务场景中。美团AI平台搜索与NLP部算法团队基于美团海量业务语料训练了MT-BERT模型,已经将MT-BERT应用到搜索意图识别、细粒度情感分析、文本分类、相关性排序等业务场景中。
MT-BERT
搜索与NLP部使用了美团内部开发的AFO框架进行MT-BERT预训练。AFO框架基于YARN实现数千张GPU卡的灵活调度,同时提供基于Horovod的分布式训练方案,以及作业弹性伸缩与容错等能力。相比于TensorFlow分布式框架,Horovod在数百张卡的规模上依然可以保证稳定的加速比,具备非常好的扩展性。
为了加快预训练速度,搜索与NLP部采用了混合精度训练方式。混合精度训练指的是FP32和FP16混合的训练方式,使用混合精度训练可以减少显存开销,加大Batchsize从而加速训练过程。开启混合精度的训练方式带来了2.2倍的训练加速。
为了强化MT-BERT在美团业务场景中的表现,MT-BERT预训练过程中也尝试融合知识图谱信息。知识图谱可以组织现实世界中的知识,描述客观概念、实体、关系。这种基于符号语义的计算模型,可以为BERT提供先验知识,使其具备一定的常识和推理能力。搜索与NLP部已经构建了大规模的餐饮娱乐知识图谱——“美团大脑”。团队通过Knowledge-aware Masking方法将“美团大脑”的实体知识融入到MT-BERT预训练中。融合业务知识的MT-BERT在通用Benchmark和业务Benchmark上相比原始BERT模型都带来显著的性能提升。
BERT在下游NLP任务上效果拔群,但由于其深层的网络结构和庞大的参数量,如果要部署上线,还面临很大挑战。为了减少模型响应时间,满足上线要求,团队主要尝试了两种轻量化方案:
模型裁剪,即直接裁剪BERT模型的层数,保持其他参数不变。对于短文本分类任务(如Query意图分类),直接裁剪后模型性能并没有明显的损失,但能减少不必要的参数运算,推理时间可以大幅提升。
模型蒸馏。在搜索场景下的Query-POI匹配任务,团队通过Prediction Distillation和Transformer Distillation等知识蒸馏方法将12层BERT模型蒸馏为3层小模型,同时对Embedding Size、Attention Head等参数也进行压缩,参数量从110M压缩到了21M,在保持98%性能的前提下,实现了推理时间4.5倍的加速。
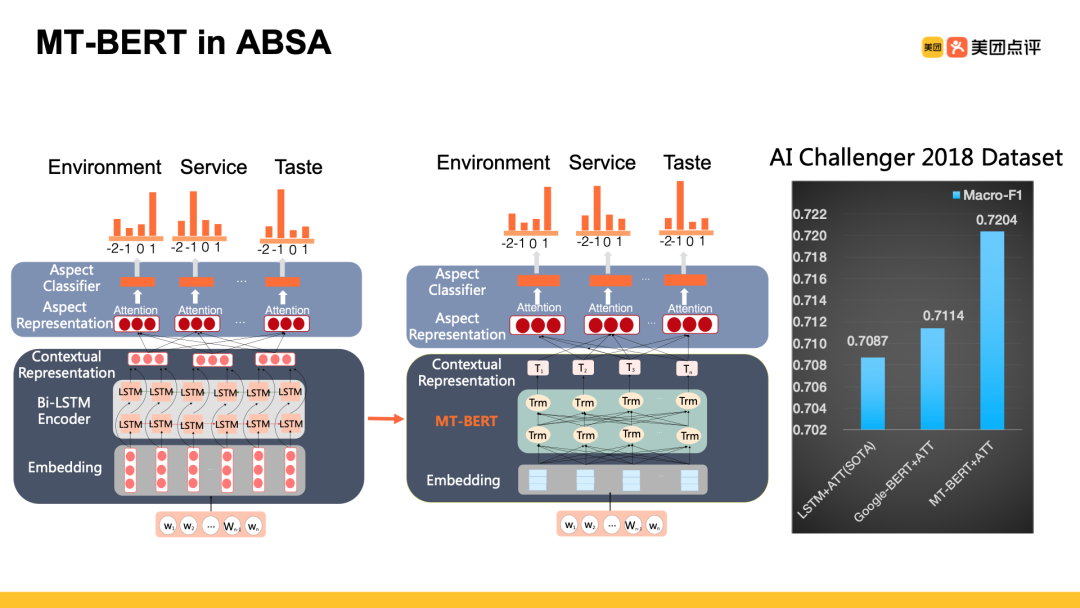
美团作为本地生活服务平台,积累了大量真实用户评论。对用户评论的细粒度情感分析在深刻理解商家和用户、挖掘用户情感等方面有至关重要的价值,并且在智能搜索、个性化推荐、业务安全等领域有着广泛应用。
针对细粒度情感分析任务,团队设计了基于MT-BERT的多任务分类模型,MT-BERT依赖其深层网络结构以及海量数据预训练,可以更好的表征上下文信息,尤其擅长提取深层次的语义信息。基于MT-BERT的多任务学习细粒度情感分析模型在AI Challenger 2018数据集上取得了SOTA结果,并在大众点评的精选评价业务中落地应用。
MT-BERT in ABSA
在美团搜索场景中,Query-POI匹配是排序模型的重要特征。为优化美团搜索排序结果的深度语义相关性,提升用户体验,团队基于MT-BERT优化美团搜索排序模型中的Query-POI匹配特征。由于美团搜索多模态的特点,在某些情况下,仅根据Query和POI文本信息很难准确判断两者之间的语义相关性。如<考研班,虹蝶教育>,Query和POI文本相关性不高,但是“虹蝶教育”三级品类信息分别是“教育-升学辅导-考研”,引入相关图谱信息有助于提高模型效果。
预训练任务也做了变化,将BERT中原有的Next Sentence Prediction(NSP)任务改进为Query-POI点击预测任务,充分利用大量的搜索点击日志。基于BERT的句间关系判断属于二分类任务,本质上是Pointwise训练方式。Pointwise Fine-tuning方法可以学习到很好的全局相关性,但忽略了不同样本之前的偏序关系。如对于同一个Query的两个相关结果DocA和DocB,Pointwise模型只能判断出两者都与Query相关,无法区分DocA和DocB相关性程度。为了使得相关性特征对于排序结果更有区分度,团队借鉴排序学习中Pairwise训练方式来优化BERT Fine-tuning任务。
值得一提的是,团队提出一种两阶段自适应的Listwise BERT模型TABLE(A Task-Adaptive BERT-based ListwisE Ranking Model for Document Retrieval),在微软MARCO文档排序任务中排名第一,是首个在MRR指标上突破0.4的团队,介绍该模型的论文已经被CIKM 2020接收,欢迎大家关注。
TALK1 视频链接
https://www.bilibili.com/video/BV1MK4y1v7KK

胡可
TALK2 KDD Cup 2020 Winning Solution and Its Applications in Meituan Search Ads
胡可的报告主要介绍了数据偏差优化、图学习、多模态学习在美团搜索广告中的应用经验;并呈现了基于这三方面技术积累,广告平台最终在国际顶级数据挖掘竞赛KDD Cup中获得两项冠军、一项季军的技术方案。
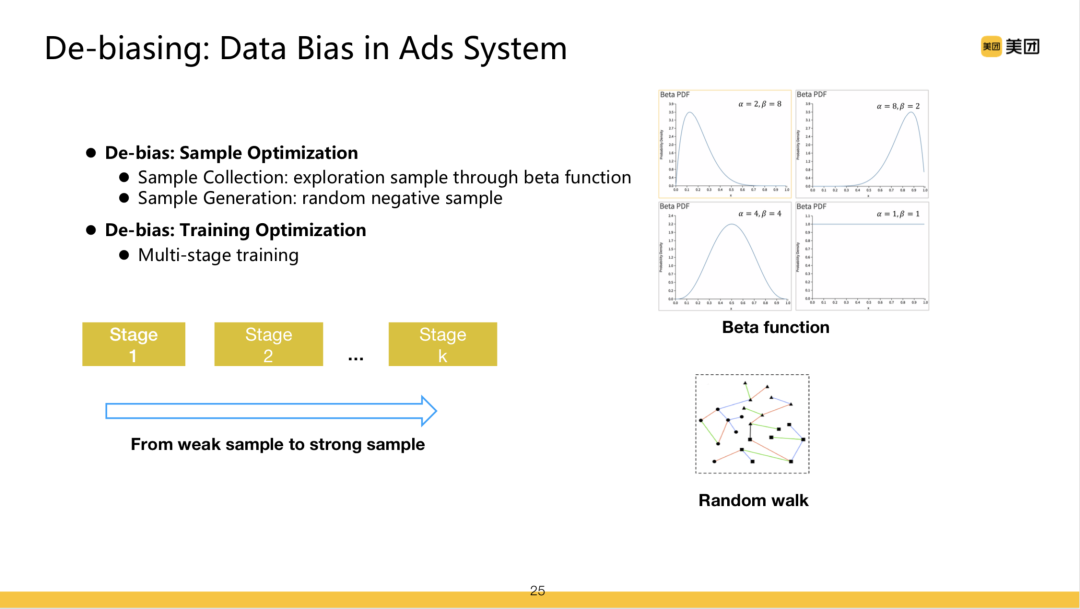
在报告中,胡可主要介绍了到店广告平台部的搜索广告业务及数据偏差优化、图学习、多模态学习三方面前沿技术在业务中的算法研究与应用,并介绍业务沉淀下的技术在KDD Cup中的三道相应赛题的经验。报告介绍了广告系统中两个重要的数据Bias,Position Bias和Selection Bias。其中Selection Bias主要聚焦广告系统中训练与预测数据分布不一致的问题——搜索广告CTR模型基于模型挑选出的曝光数据,同线上真实候选分布不一致。
在本次分享中,胡可介绍了基于Beta分布的Exploration算法与负例生成算法、及基于数据分布差异性进行多阶段训练的算法。此外,报告介绍了图学习在团队中触发与预估两个模块的应用——基于Session共现解决语义关联与行为关联问题。无论是创意优选还是CTR预估,均涉及Query同广告的图像信息匹配的问题,报告中也分享了多模表达学习的网络设计,以及通过知识蒸馏进行联合训练的算法。
De-biasing
在KDD Cup比赛中,搜索广告算法团队基于这三个领域的技术积累,选择了三道相应赛题进行算法深入优化。Debiasing赛题贴近于广告系统中的数据Bias实际问题,团队针对Selection Bias问题,进行了排序模型的框架优化,通过多跳点击共现进行样本生成,解决曝光样本同真实系统候选不一致的问题。并且将user同候选item的关系(u-i)建模问题转化成u-i-i的建模问题,缓解了u-i建模本身由于用户的数据稀疏造成的Bias问题。
AutoGraph比赛中,团队从拓扑结构出发对数据进行组织和建模,设计了结合谱域和空域图神经网络的自动化融合框架,并基于该框架进行了GCN、TAGC、GraphSage、GAT等网络结构与图卷积的深度广度平衡的自动化搜索。比赛中应用了业务中图学习的技术积累,并在自动化图学习这一前沿领域(AutoML和图学习结合)设计了算法框架。在Multimodalities Recall比赛中,介绍了基于Fusion Layer的多模态匹配网络,并基于点击与人工标注数据,进行基于数据置信度的知识蒸馏优化,形成多阶段训练框架,有效的运用了业务中多模态学习与知识蒸馏的技术沉淀。
在报告中,基于数据偏差,图学习,多模态学习的技术介绍,传播了将前沿技术应用于实际问题的经验。讲解后,在技术交流群听众同学也有较大反响并基于上述技术细节提出多个针对性问题。
TALK2 视频链接
https://www.bilibili.com/video/BV1C5411a79N

胡懋地
TALK3 Knowledge Graph and Its Applications in Meituan Waimai
本次胡懋地分享的内容分为背景、构建、应用三个部分,分别介绍为什么要构建知识图谱,建设企业级知识图谱的基本思路是什么,知识图谱在外卖有哪些落地实践。
首先是背景部分,跟其他电商平台类似,美团外卖以商品作为媒介,连接形成了商家和用户的供需关系。在外卖平台上,商家可以发布他们的商品供给,并提供价格和特点的描述。用户在这些商品中进行浏览或搜索,在比较后完成交易和履约。问题在于,外卖商品供给大多不是标品,并且商家提供的信息有限,这对用户形成交易决策带来了一些困难。
另外,随着商家、商品的不断增加,从用户侧收集的行为数据只能覆盖一部分供给,这也增加了精准推荐的难度。建设知识图谱,丰富关联信息,是解决这一问题的主流手段。知识图谱可以直接用于排序模型特征、意图识别、分类导航、搜索召回等应用。基于应用考虑,首要建设的是标准化的分类体系和多样化的属性体系。

知识图谱的典型应用
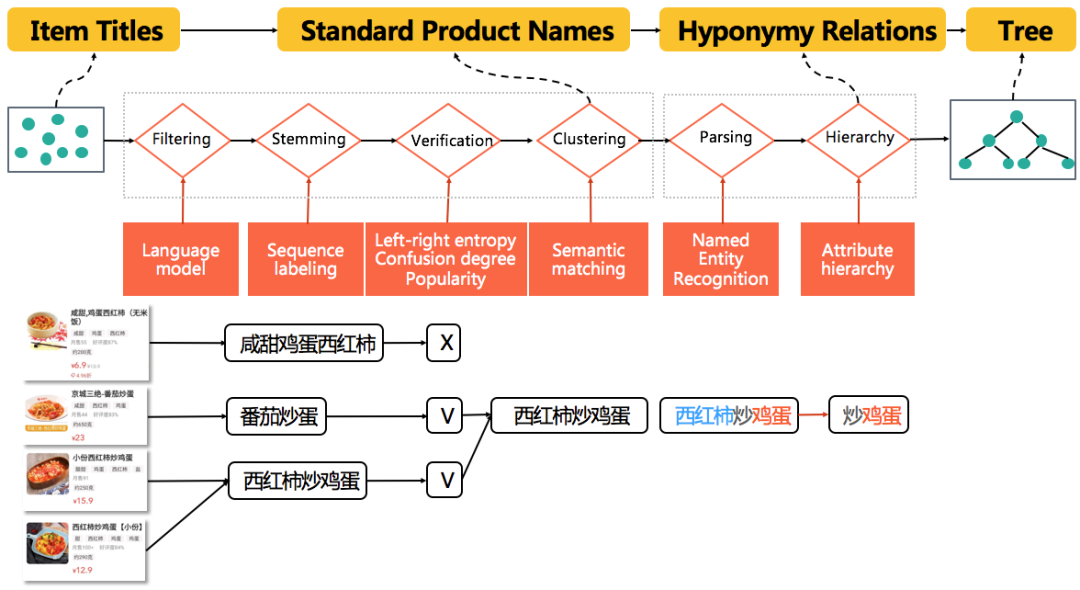
其次是知识图谱的构建部分,外卖商品的标准化分类体系包括类目和标准菜品名两大部分,是从粗到细的树形层级体系。在类目方面,人工梳理了数百个类目,并基于主题模型、多模态、预训练等技术手段增加商品特征,实现了较高准确率的类目识别。标准菜品名是类目的延伸,词表在十万级,量级远超类目。
除了需要建立商品到标准菜品名的识别模型,还需要从亿级商品名中,通过技术手段实现标准菜品名词表的提取。具体的流程包括,基于语言模型的错误过滤,基于序列标注的主干抽取,基于左右熵、混淆度、流行度等指标的质量审核等。在构建出标准菜品名的词表后,再通过命名实体识别和实体属性层级关系,推断出标准菜品名的整体层级树。
除了标准化分类体系,还定义了食材、口味、做法等餐饮属性体系,以商品名、商品描述、百科、菜谱等数据为基础,构建了对应的实体和关系抽取模型,包括多模态输入多任务输出的模型,用于解决属性冲突等问题。另外,还引入了商家端和线下收银等数据,实现了建议、校验、对齐等技术能力。
标准菜品名词表构建流程
最后是知识图谱的应用部分。知识图谱有很多比较直接的应用,比如,往用户侧加工,可产生偏好;往时空侧加工,可产生场景主题。另外,知识图谱与深度学习模型结合,可以解决更多更具体的业务问题。下面将基于套餐搭配、推荐语抽取、图谱推荐这3个问题,介绍知识图谱在美团外卖的具体业务应用。
(1)套餐搭配是餐饮行业的典型应用,外卖的大部分订单包含多个商品。推荐符合用户餐饮习惯的套餐搭配,可以使用户的挑选过程变得更加便捷。餐饮习惯可能因人而异,有些人喜欢吃米饭,有些人则喜欢吃馒头。因此,基础的方案是离线生成大量高质量的套餐供给,然后在线上用个性化的召回排序,满足套餐搭配的精准推荐需求。在离线生成阶段,高销量的商品搭配是离线供给的重要来源,可以利用知识图谱中的类目和属性做一次归纳和泛化,产生更多的搭配方式。
但是,基于规则的归纳和泛化很难平衡泛化的质量和数量。从菜单到套餐搭配的选择问题,类似于文本摘要。于是我们选择了带指针网络的Seq2Seq框架,其中,Coverage机制用于降低重复率,商家内所有商品的搭配组合的概率树用作拟合目标,基于Mask的硬约束和基于特征的软约束用于适配实时条件,比如价格范围。商品的标题和价格会持续变化,所以删除商品、微调价格等数据增强方式用于稳定模型表现。由于输入输出都是无序组合,我们用没有位置表示的Transformer作为基础模型,并用Q*K代替Q*K*V来建立指针结构。
在生成质量的评估方面,除了评估对测试商家生成的套餐搭配对这些商家高销量套餐搭配的命中率,还将这这些数据混合在一起,人工评估各套餐搭配的质量分。这两种套餐最终获得了类似的评估结果,即人工无法分辨哪些是模型生成的,哪些是高销量的。但是,离线生成无法满足用户的实时长尾需求,比如用户已经有一些商品在购物车中,想要再选购一些商品。
此时,需要一个实时生成模型来满足长尾需求。通过在Decoder中增加个性化层,引入用户特征和上下文特征、分离可预计算的模型部分,将拟合目标改为当前订单对应的搭配等改进,训练得到了一个可显著提升订单命中率的实时套餐搭配生成模型。
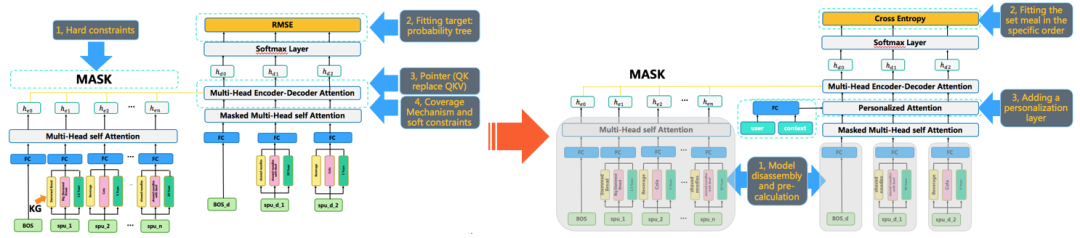
生成模型
(2)推荐语抽取的目标是从评论中抽取适合作为推荐语的片段,具体涉及片段抽取、情感极性识别、文本合成、质量控制、吸引力评分等技术模块。本部分主要讲一下片段抽取模型。评论的描述对象涵盖商家、商品、配送等类型,首先需要识别出描述对象的类型,如果描述对象的类型是商品,需要进一步识别描述的实体是订单中的哪个商品,以及具体的主题角度等等。片段抽取模型以基于评论数据训练的bert作为基础,采用TextQA框架,通过聚合对象类型、实体、实体对应的图谱知识等信息,加工产生搜索词,用模型预测BIO标签,同时处理对象分类、实体链接、主题分类、片段抽取等问题。
(3)图谱推荐的常见方式是融合实体的属性及关系,通过图结构建立向量表示,用于个性化的召回和排序。异质信息网络可引入多种类型的节点和边,例如,同一类目的商品或同一口味的商品,可作为Meta-Path形成图中的兴趣传播路径,汇聚来自不同节点和边的多跳信息,但是这种方式产生的向量一般是单峰的。MIND等方案可以用于发现用户行为序列体现出的多峰兴趣,但不便于融入知识图谱的信息。
通过融合行为图谱和知识图谱,对齐其中的实体节点,得到统一的信息网络,用AC等强化学习方法。从用户出发游走到订单商品,可以产生解释性较好且多样性较高的推荐结果。该技术借助图数据库的索引能力,在外卖商品推荐应用上线实验,点击率和访购率都有明显提升。
TALK3 视频链接
https://www.bilibili.com/video/BV1iD4y1U7R7
美团招聘
美团AI平台搜索与NLP部
在这里,我们打造了高性能高扩展的搜索引擎,来高效地支撑形态各样的生活服务搜索。
在这里,我们用自然语言处理、机器学习、知识图谱等技术,不断加深对用户、场景、查询和服务的理解,以能更好地连接用户和服务。
在这里,我们和产品一起,精细打磨点滴的搜索体验,为亿万用户提供更智能的生活服务搜索体验。
搜索产品、NLP产品、搜索算法、NLP算法,C++/Java/Android/iOS/Web前端/数据研发、产品运营/数据标注等职位正在热招。
美团广告平台技术部
搜索广告算法专家/高级专家
广告平台搜索广告算法团队立足搜索广告场景,探索深度学习、强化学习、人工智能、大数据、知识图谱、NLP和计算机视觉最前沿的技术发展,探索本地生活服务电商的价值。主要工作方向包括:
触发策略:用户意图识别、广告商家数据理解、Query改写、深度匹配,相关性建模。
质量预估:广告质量度建模。点击率、转化率、客单价、交易额预估。
机制设计:广告排序机制、竞价机制、出价建议、流量预估、预算分配。
创意优化:智能创意设计。广告图片、文字、团单、优惠信息等展示创意的优化。
岗位要求
基本要求:
有三年以上相关工作经验,对CTR/CVR预估、NLP、图像理解、机制设计至少一方面有应用经验。
熟悉常用的机器学习、深度学习、强化学习模型。
具有优秀的逻辑思维能力,对解决挑战性问题充满热情,对数据敏感,善于分析/解决问题。
计算机、数学相关专业硕士及以上学历。
具备以下条件的同学优先:
有广告/搜索/推荐等相关业务经验。
有大规模机器学习相关经验。
美团外卖技术部
在这里,我们以海量商品信息和UGC等数据为基础,构建了完整的知识图谱体系。在此基础上,利用序列建模、多目标学习、图神经网络、强化学习等技术,结合端智能,实现了个性化的推荐、搜索、营销等服务,支撑了超过3000万的日交易订单,影响上亿人的生活。另外我们还依托自然语言、计算机视觉等人工智能技术,搭建了智能海报及动图设计、推荐理由生成等图文内容的创意生产能力,大幅提升了产品体验。
目前,美团外卖技术部正在热招知识图谱、智能搜索、个性化推荐、精准营销、自然语言处理、计算机视觉、大数据开发等方向的算法和工程人才。欢迎大家自荐或者推荐身边的优秀人才。
同学们可直接扫描下方二维码投递简历:

也可通过邮件形式投递简历:tech@meituan.com(邮件主题注明:SIGIR2020)



















 9
9

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









