






1.确定目标网站
-
目标网站的URL为:https://www.lagou.com/zhaopin/python/filterOption=3&sid=99132d4b071a4952a73374db9065626f
-
在谷歌浏览器的地址栏中输入URL后看到如图4-1所示的关于互联网板块的招聘信息页面:

- 确定爬取页面信息的字段为:公司名称、公司简称、城市、公司规模、学历要求、工作经验、薪资、融资阶段、工作性质、职位诱惑、职位名称、公司福利,一共12个字段的信息
2.静态网页的爬取
因为拉钩网的反爬虫策略,这里采用静态网页的爬取,爬取数据下来后再进行数据的分析,这里模拟了浏览器的请求,来进行攻破拉钩网的反爬虫策略。
3.源数据的获取
这里先将2中的静态网页读取进来,然后分析网页结构后发现,可以使用正则进行数据的获取。

4.数据的持久化存储
这里使用csv库来存储获取好的数据,首先写入表头,然后将正则获取的数据进行循环,来保存想要的数据放到csv文件中



将数据存入到mongodb中,如图4-7所示。
1.导入数据爬虫爬取的数据是不能够直接使用,进行可视化的,因为各种原因,爬取到的数据会有缺失值和异常值,这里就需要来进一步处理数据,将的数据进行清洗 ,这里使用numpy,pandas库等进行数据的清洗。


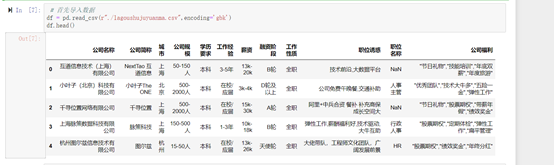
2.缺失值的处理

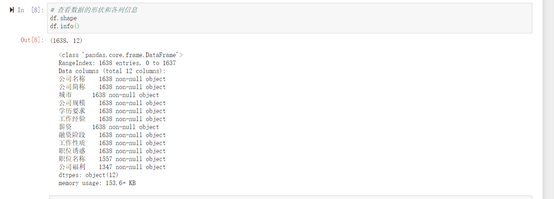
删除后缺失值后重新查看源数据,如图5-5可以看出数据从1638条变成了1282条,查看各列数据可以看出已无缺失值。

因为删除了缺失的数据,但是在源数据中的索引也空出来了,中间会有断层,为了下面数据的可视化在这里进行重置索引。

查看所获取的数据中有多少个城市如图5-7所示。
在薪资的后面新增列名为:平均薪资,并通过循环写入到源数据中。


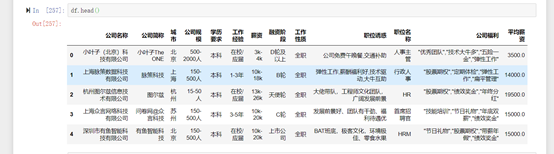
按照城市进行分组, 查看平均薪资的平均值和标准差。

通过图5-9可以看出个别城市的标准差有缺失,经过分析得出原来是因为个别城市的数据数量太少达不到计算标准差的要求,这里将缺失的数据进行删除。


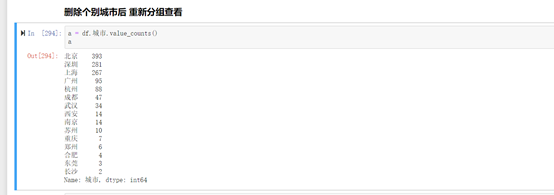
删除个别城市的数据后,重置索引,重新查看城市如图5-11所示,并重新进行城市的分组,并持久化存储清洗后的数据。


根据图5-12把城市进行分组及计算平均薪资,可得出直方图,如图6-1所示,从图中可以看出北京、上海、广州、深圳这四个城市的平均工资在全国来说是屈指可数的。

从图6-2中可以看出,绩效奖金、带薪年假、岗位晋升、五险一金等词语出现频繁是互联网企业招聘中的热词。
从图6-3中可以看出,pyhon开发工程师、大数据开发工程师、HR等职位出现频繁是互联网企业招聘中比较热门的职位。


从图6-4中可以看出HR、PYTHON、php、数据挖掘、机器学习、算法、node。Js这是研究方向相对来说需求较大,如果想去找单位工作,可以考虑从这些职位的要求上着手考虑和准备。

从图6-5中可以发现,上千条数据中招聘的学历要求主要还是集中在本科生中,对于高学历要求的公司相对较少,虽然这里没有细分,但是有一个好的学历绝对是有力的敲门砖。但是也可以看到硕士、博士的要求量并不多,或许只是某些特殊要求的岗位才会有需求。
有一个本科学历,一般的招聘都能足够了。当然大专、不限在这里也可以看到需求量也是很大的,在这里猜想一下,或许现在的很多公司都以能力作为了一个重要的指标,但坚信有能力的人不怕没有好工作。

从图6-6中可以看出HR、python开发工程师、大数据开发工程师等岗位相对来说需求较大,如果想去找单位工作,可以考虑从这些职位的要求上着手考虑和准备。

对于找工作来说最重要的就是各个城市对于岗位的需求量。需求量越大的城市必然经济越发达,机遇也越多,对于自身的发展空间相对越有利,也就是日后的发展方向。
从图6-7中可以看出,招聘人数最多的地方,主要分布在深圳市和北京市和上海市,由此可以看出北京、上海、广东互联网普及率全国最高,中国互联网行业的格局还是在北上广这些综合实力很强的城市。虽然后续的几个城市的需求量处于中等,但也能提供一个比较好的起步阶段。

最后把所有的可视化数据放到一个页面中,进行可视化大屏的展示,至此,数据可视化的工作已全部完成。
















 5173
5173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









