







第三方调用控制
背景介绍
我的系统对可用性要求非常高,为此我综合使用了熔断、限流、降级、超时控制等措施。并且,我这个系统还有一个特别之处,就是它需要和很多第三方平台打交道。所以要想保证系统的可用性,我就需要保证和第三方打交道是高可用的。
我在刚接手这个项目的时候,这一块的设计和实现不太行。总体来说可扩展性、可用性、可观测性和可测试性都非常差。为了解决这个问题,全方位提高系统的可扩展性、可用性、可观测性和可测试性,我做了比较大的重构。
我重新设计了接口,提供了一个一致性抽象。(这里你可以补充你设计了哪些接口,然后强调一下效果)重构之后,研发效率提高了 30%,并且接入一个全新的第三方,也能对业务方做到完全没感知。
我引入客户端治理措施,主要是限流和重试,并且针对一些特殊的第三方接口,我还设计了一些特殊的容错方案。
我全方面接入了可观测性平台,包括 Prometheus 和 Skywalking,并且配置了告警。和原来比起来,现在能够做到快速响应故障了。
我还进一步提供了测试工具,可以按照业务方的预期返回响应,比如说成功响应、失败响应以及模拟接口超时。针对压测,我也做了一些改进。
一致性抽象
提供一个一致性抽象,屏蔽不同第三方平台 API 之间的差异。
这算是你这个模块或者服务最基本的目标。举个例子,如果你调用的是第三方支付平台,你们公司支持多种接入方式,包括微信支付、支付宝支付。
在这种情况下,业务方只希望调用你的某个接口,然后告诉你支付所需要的基本信息,比如说金额和方式。你这个接口的实现就能根据具体的支付方式发起调用,业务方完全不需要关心其中的任何细节。
这种一致性抽象会统一解决很多细节问题。比如不同的通信协议、不同的加密解密算法、不同的请求和响应格式、不同的身份认证和鉴权机制、不同的回调机制等等。这会带来两个好处。
-
研发效率大幅提高,对于业务方来说他们不需要了解第三方的任何细节,所以他们接入一个第三方会是一件很简单的事情。
-
高可扩展性,你可以通过扩展接口的方式轻松接入新的第三方,而已有的业务完全不会受到影响。
同步转异步
同步转异步在一些不需要立刻拿到响应的场景,如果你发现第三方已经崩溃了,你可以将业务方的请求临时存储起来。等后面第三方恢复了再继续调用第三方处理。这种方案一般用于对时效性要求不高的业务。比如业务方只是要求你上报数据,不要求你立刻成功,那么你就可以采用这种方案。
我们这种容错机制其实完全可以做成利用消息队列来彻底解耦的形式。在这种解耦的架构下,业务方不再是同步调用一个接口,而是把消息丢到消息队列里面。然后我们的服务不断消费消息,调用第三方接口处理业务。等处理完毕再将响应通过消息队列通知业务方。
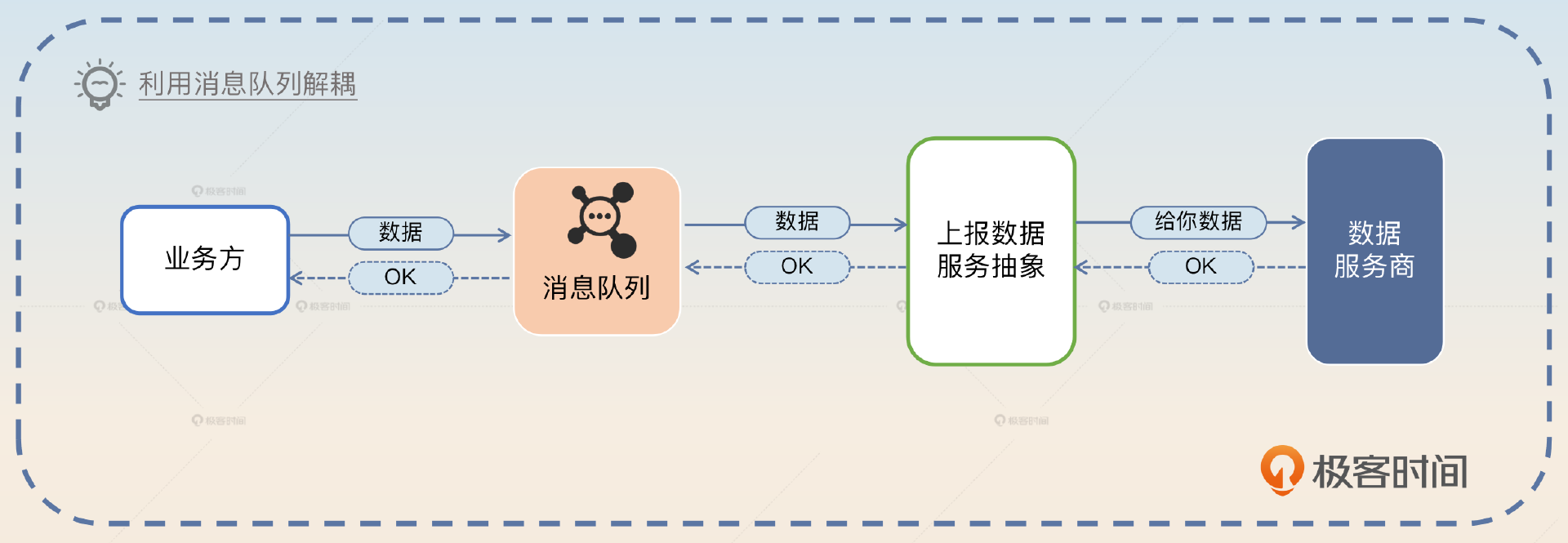
自动替换第三方
这种策略和我在负载均衡里面提到的有些类似,即调用一个第三方的接口失败的时候,你可以考虑换一个第三方。
这里一些可能会追问的点。
-
你怎么知道第三方出问题了?这个问题可以参考我们前面讲过多次的判断服务健康与否的方式,比如说用响应时间、错误率、超时率。那么自然可以将话题引导到熔断、降级、限流那边。
-
如果全部可用的第三方都崩溃了怎么办?这种问题直接认怂就可以。因为一家出故障是小概率,多家同时出故障那就更是小概率事件了,在这种情况下你除了告警也没有别的办法了。也就是所谓的尽人事,听天命。
压测支持
压测支持每当你想搞压测的时候,你就会发现,所有的第三方接口都是压测路上的拦路虎。
正常来说,你不能指望第三方会配合你的压测。你可以设想,类似于微信之类的开放平台是不可能配合你搞什么压力测试的。甚至即便你是非常强硬的甲方,你想让乙方配合你做压力测试,也是不现实的。所以你只能考虑通过 mock 来提供压测支持。和正常的测试支持比起来,压测你需要做到三件事。
- 模拟第三方的响应时间。
- 模拟触发你的容错机制。如果你采用了同步转异步这种容错机制,那么你需要确保在流量很大的情况下,你确实转异步了;如果你采用的是自动切换第三方,那你也要确保真的如同你设想的那样真的切换了新的第三方。
- 流量分发。如果是在全链路压测的情况下,压测流量你会分发到 mock 逻辑,而真实业务请求你是真的调用第三方。
超时控制
目标
超时控制有两个目标,
一是确保客户端能在预期的时间内拿到响应。这其实是用户体验一个重要理念“坏响应也比没响应好”的体现。

二是及时释放资源。这其中影响最大的是线程和连接两种资源。
释放线程:在超时的情况下,客户端收到了超时响应之后就可以继续往后执行,等执行完毕,这个线程就可以被用于执行别的业务。而如果没有超时控制,那么这个线程就会被一直占有。而像 Go 这种语言,协程会被一直占有。
释放连接:连接可以是 RPC 连接,也可以是数据库连接。类似的道理,如果没有拿到响应,客户端会一直占据这个连接。及时释放资源是提高系统可用性的有效做法,现实中经常遇到的一类事故就是因为缺乏超时控制引起了连接泄露、线程泄露。

确定超时时间
比如说大厂的 App 首页接口响应时间都有硬性规定。就像某司的要求是 50ms,也就是说不管你后端多复杂,不管你后面调用多少个服务,你的响应时间都必须控制在 50ms 以内。我后面会再深入讨论这个问题,它是你刷亮点的关键。
根据用户体验
一般的做法就是根据用户体验来决定超时时间。比如说产品经理认为这个用户最多只能在这里等待 300ms,那么你的超时时间就最多设置为 300ms。但如果仅仅依靠用户体验来决定超时时间也是不现实的,比如说当你去问产品经理某个接口对性能要求的时候,他让你看着办。那么这个时候你就要选择下一种策略了。
根据响应时间
在实践中,大多数时候都是根据被调用接口的响应时间来确定超时时间。一般情况下,你可以选择使用 99 线或者 999 线来作为超时时间。所谓的 99 线是指 99% 的请求,响应时间都在这个值以内。比如说 99 线为 1s,那么意味着 99% 的请求响应时间都在 1s 以内。999 线也是类似的含义。
但是使用这种方式要求这个接口已经接入了类似 Prometheus 之类的可观测性工具,能够算出 99 线或者 999 线。如果一个接口是新接口,你要调用它,而这时候根本没有 99 线或者 999 线的数据。那么你可以考虑使用压力测试。
压力测试
简单来说,你可以通过压力测试来找到被调用接口的 99 线和 999 线。而且压力测试应该尽可能在和线上一样的环境下进行。但是就像我在限流里面提到的,很多公司其实内部没有什么压测环境,也不可能让你停下新功能开发去做压力测试。那么就无法采用压力测试来采集到响应时间数据。所以你就只剩下最后一个手段,根据代码来计算。
根据代码计算
根据代码计算和我在限流里面讲的差不多。假如说你现在有一个接口,里面有三次数据库操作,还有一次访问 Redis 的操作和一次发送消息的操作,那么你接口的响应时间就应该这样计算:
接口的响应时间=数据库响应时间×3+Redis响应时间+发送消息的响应时间
如果你觉得不保险,那么你可以在计算出来的结果上再加一点作为余量。比如说你通过分析代码认为响应时间应该在 200ms,那么你完全可以加上 100ms 作为余量。你可以告诉这个接口的调用者,将超时时间设置为 300ms。
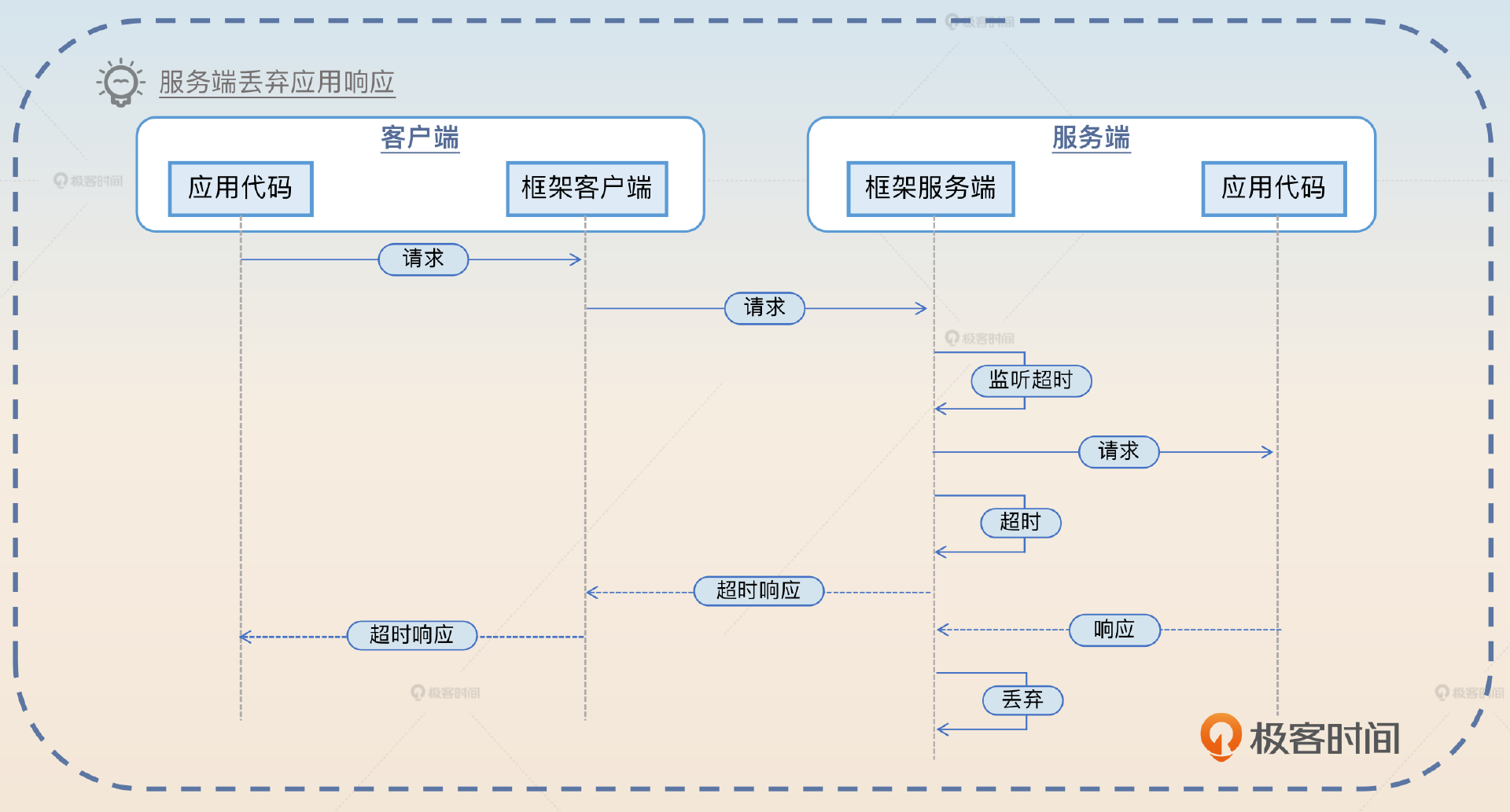
监控超时时间
在微服务框架里面,一般都是微服务框架客户端来监听超时时间。在一些特殊的微服务框架里面,框架服务端也会同步监听超时时间。















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









