







 本文分享了一次线上 Hive on Spark 作业执行超时问题的排查和解决过程。问题出现在高并发场景下,由于资源不足导致作业失败。解决方案包括减少资源需求、增加资源供给和调整超时参数。具体措施涉及调整作业并发度、优化 Spark 配置、增加 YARN 队列资源以及修改超时时间等。
本文分享了一次线上 Hive on Spark 作业执行超时问题的排查和解决过程。问题出现在高并发场景下,由于资源不足导致作业失败。解决方案包括减少资源需求、增加资源供给和调整超时参数。具体措施涉及调整作业并发度、优化 Spark 配置、增加 YARN 队列资源以及修改超时时间等。
线上 hive on spark 作业执行超时问题排查案例分享
大家好,在此分享一个某业务系统的线上 hive on spark 作业在高并发下频现作业失败问题的原因分析和解决方法,希望对大家有所帮助。
1 问题现象
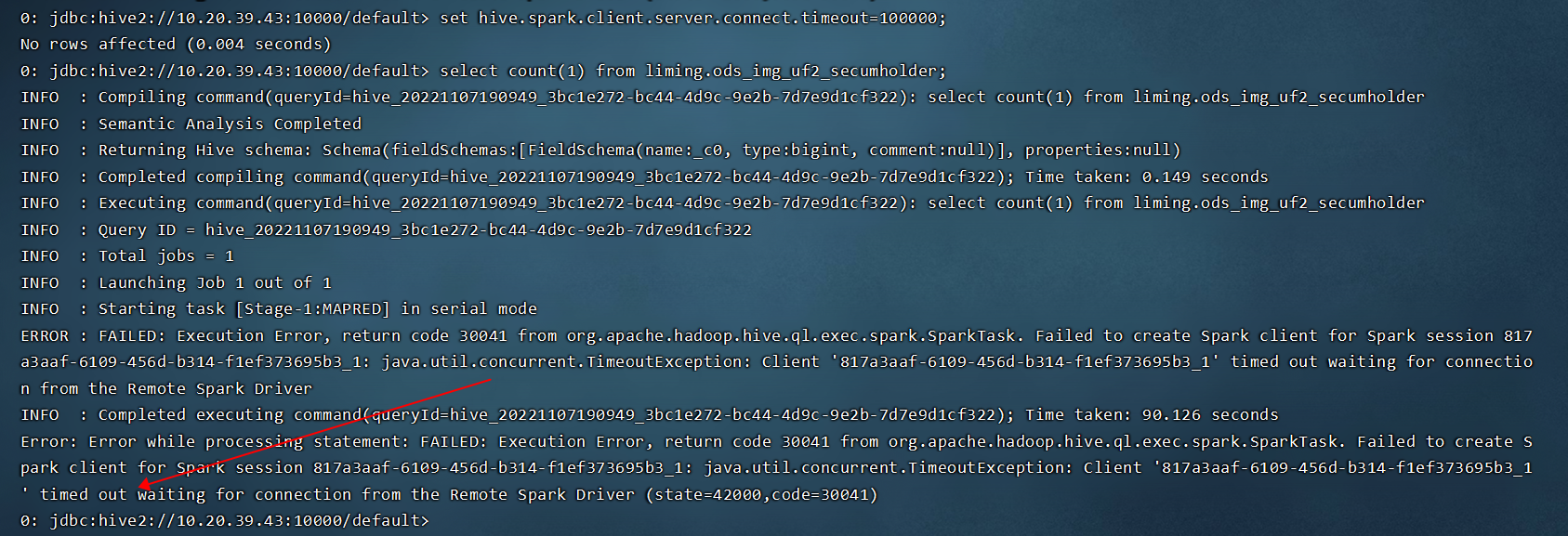
某业务系统中,HIVE SQL 以 hive on spark 模式运行在 yarn上指定的资源队列下,在业务高峰期发现部分 SQL 会报错,但重试有时又能够成功。作业具体报错信息,和示例截图如下:
SQL
failed to create spark client for spark session xx: java.util.concurrent.TimeoutException: client xx timed out waiting for connection from the remote spark driver
备注:
- hive 作业的执行引擎通过参数 hive.execution.engine 指定,可选值为 mr/spark/tez;
- CDP/HIVE3.0等新版本不再支持 hive on mr/spark, 只支持 hive on tez;
- HIVE 作业在 YARN 上的队列使用参数mapreduce.job.queuename/mapred.job.queue.name 指定;
2 问题原因
HIVE ON SPARK 作业在高并发下运行失败报超时错误,但是重试有时又能够成功,绝大多数都是因为 yarn 中对应的资源队列上没有足够的资源以启动 spark集群,所以客户端连无可连报了超时错误。
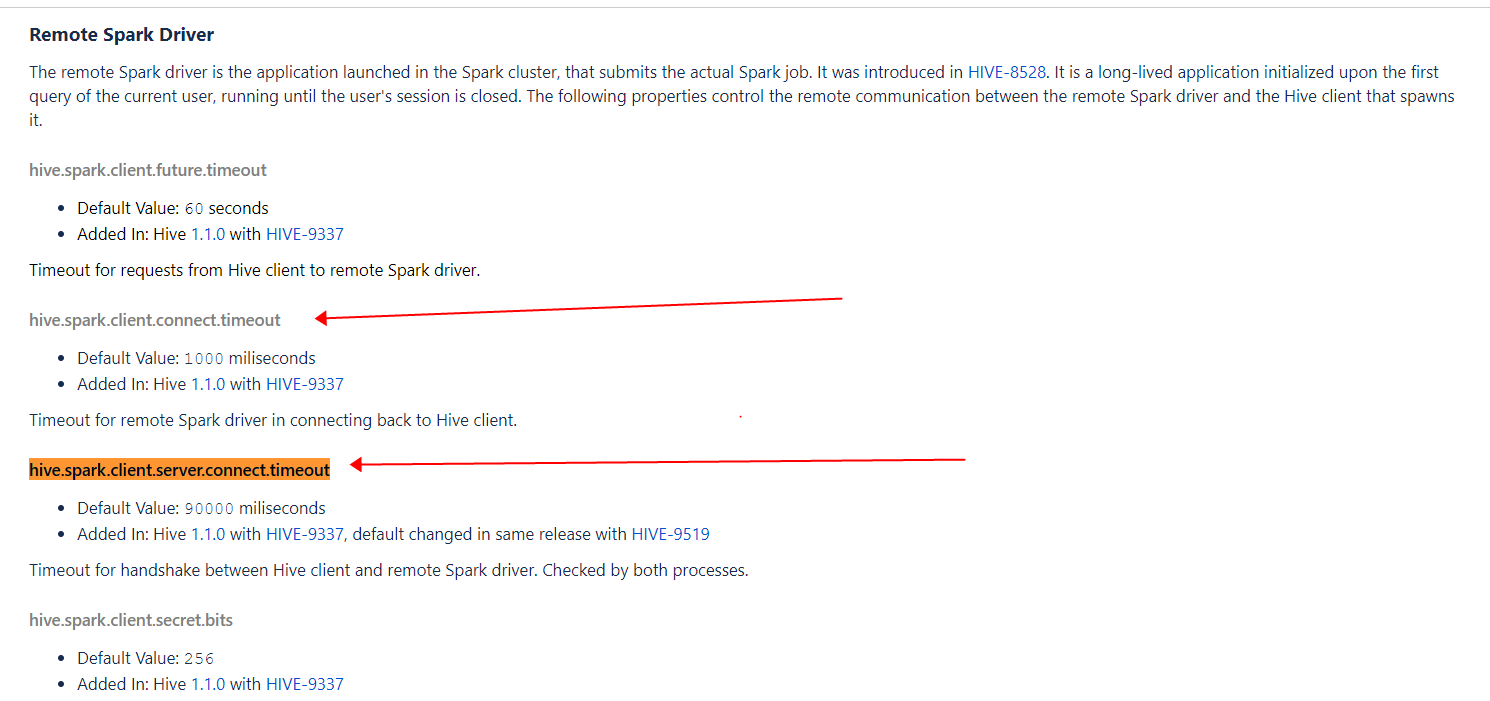
具体的超时时间,有两个相关参数进行控制:
- hive.spark.client.server.connect.timeout:该参数是服务端配置,用来控制 hive 客户端跟远程 spark 集群中的 spark driver 建立连接的超时时间,默认90秒(这里的 hive客户端是启动 spark 集群的客户端,个人认为其实就是 hs2);
- hive.spark.client.connect.timeout: 该参数是客户端配置,用来控制远程 spark 集群中的 spark driver 跟 hive 客户端建立连接的时间,默认1秒;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3706
3706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











