







Abstract(摘要)
翻译
石榴是一种重要的果树作物,通常依靠经验进行人工管理,石榴园智能化管理系统可以提高产量并解决劳动力短缺的问题,快速精准的石榴检测是石榴园智能化管理系统的关键技术之一,对保证产量和科学管理至关重要。目前大部分方案都是利用深度学习来实现石榴的检测,但是深度学习对小目标和大参数的检测效果不佳,计算速度较慢,因此在石榴检测任务上还有很大的提升空间。基于改进的YOLOv5算法,提出了一种轻量级的石榴生长期检测算法YOLO-Granada,以轻量级的ShuffleNetv2网络为骨干提取石榴特征,使用grouped convolution减少了普通卷积的计算量,使用channel shuffle增加了不同channel之间的交互。此外,注意力机制可以帮助神经网络抑制通道或空间中不太显著的特征,而卷积块注意力模块注意力机制可以利用权重的贡献因子来提升注意力的效果,优化物体检测的准确率。 改进后的网络平均准确率达到了0.922,仅比原YOLOv5s模型(0.929)降低了不到1%,但带来了速度的提升和模型大小的压缩。 检测速度比原网络提高了17.3%,该网络的参数、浮点运算和模型大小分别压缩为原网络的54.7%、51.3%和56.3%。此外,该算法每秒检测8.66幅图像,达到了实时效果。本研究进一步利用Nihui卷积神经网络框架,开发了基于Android的石榴实时检测应用程序。该方法为石榴园智能管理设备提供了更加精准、轻量化的解决方案,可为农业应用中的神经网络设计提供参考。
精读
ShuffleNetv2
“以轻量级的ShuffleNetv2网络为骨干提取石榴特征,使用grouped convolution减少了普通卷积的计算量,使用channel shuffle增加了不同channel之间的交互”
论文解读见【轻量化网络系列(5)】ShuffleNetV2论文超详细解读(翻译 +学习笔记+代码实现)-CSDN博客
之前的问题
神经网络架构的设计目前主要由计算复杂度的间接指标(即 FLOPs)来指导。
但是,直接指标(如速度)还依赖于其他因素。
本文主要工作
(1)提出了新的网络结构ShuffleNet V2
(2)指出过去在网络架构设计上仅注重间接指标 FLOPs 的不足,并提出两个基本原则和四个实用准则来指导网络架构设计
FLOPS和FLOPs:
FLOPS: 全大写,指每秒浮点运算次数,可以理解为计算的速度,是衡量硬件性能的一个指标 (硬件)
FLOPs: s小写,指浮点运算数,理解为计算量,可以用来衡量算法/模型的复杂度,(模型)在论文中常用GFLOPs(1 GFLOPs = 10^9FLOPs)
高效网络设计的实用准则
G1)相同通道宽度能够最小化MAC(内存访问成本)
原因:现代网络通常采用深度可分离卷积 ,其中逐点卷积(即1 × 1卷积)占了复杂性的大部分。
1×1卷积核的参数由两个量决定:
1.输入通道数C1
2.输出通道数C2
假设一个1×1卷积层的输入特征通道数是c1,输出特征尺寸是h和w,输出特征通道数是c2,那么这样一个1×1卷积层的FLOPs就是右侧式子所示 :![]()
(更具体的写法是B=1×1×c1×c2×h×w,这里省略了1×1)
假设计算设备的内存足够大能够储存整个计算图和参数,那么:
![]()
由中值不等式得:![]()
因此理论上MAC的下界由FLOPs决定,当且仅当C1 = C2 时取得最小值
G2) 过度的组卷积会增加 MAC(内存访问成本)
组卷积是ResNext提出的结构,使用了稀疏的平行拓扑结构来减少计算复杂度:
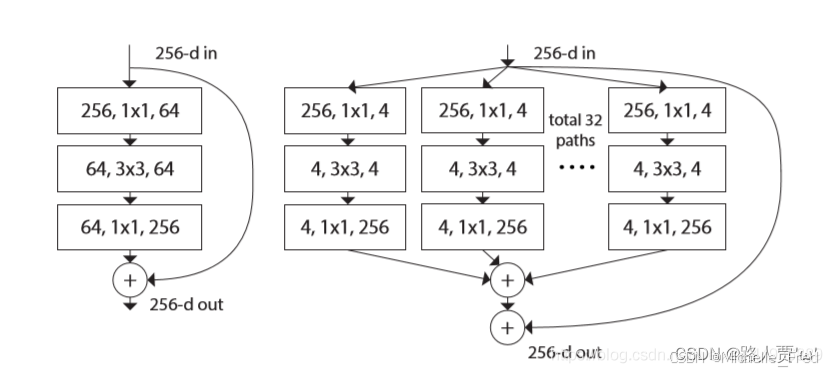
作者发现,虽然使用组卷积在相同计算复杂度的情况下拓展了通道数,但是通道数的增加也使得MAC大大增加。
假设 g 是1x1组卷积的组数,则有:
即
可以看到,对于固定的输入大小 (h,w,ci) 和计算复杂度FLOPS (B),MAC随着 g 的增大而增加。
G3) 网络碎片化会降低并行程度
在GoogleNet系列中,大量使用的Inception这样的multi-path结构(即存在一个lock中很多不同的小卷积或者pooling)增加了准确度:
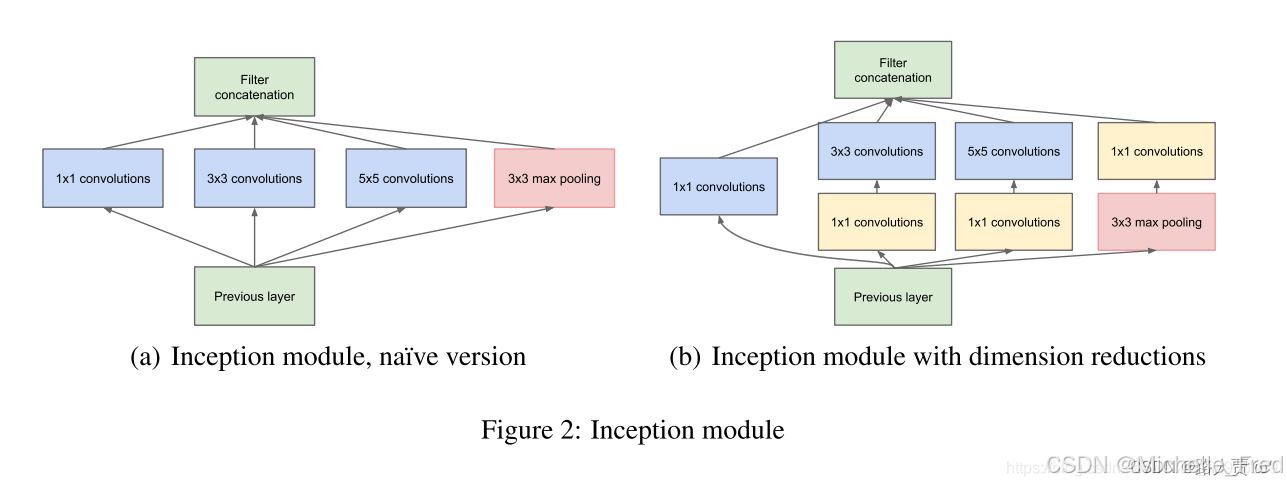
这很容易造成网络碎片化,减低模型的并行度,相应速度会慢。
G4) 操作的影响不可忽略
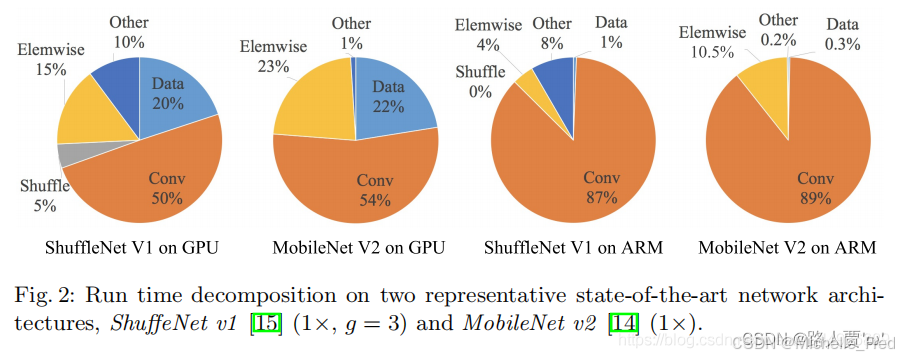
对于元素级(element-wise operators)比如ReLU和Add,虽然它们的FLOPs较小,但是却需要较大的MAC。
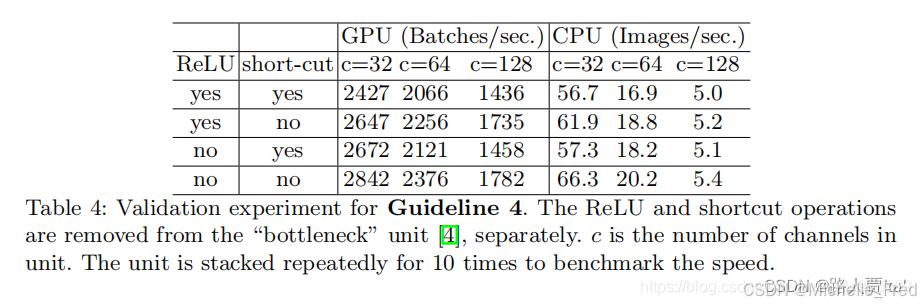
这里实验发现如果将ResNet中残差单元中的ReLU和shortcut移除的话,速度有20%的提升。
总结
1)使用「平衡」的卷积(相同的通道宽度,逐点组卷积);
2)考虑使用组卷积的成本(使用小的分组);
3)降低碎片化程度(减少并行);
4)减少元素级运算(捷径连接)。
回顾ShuffleNetV1
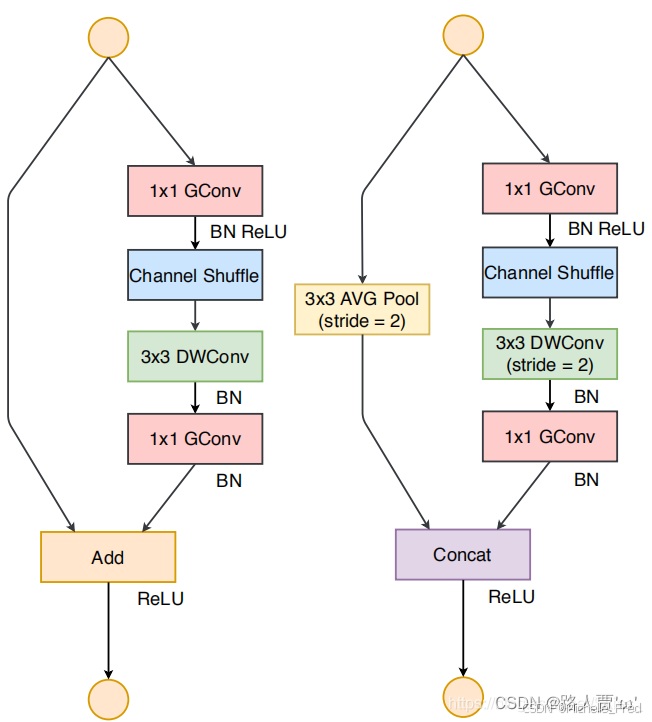
ShuffleNetV1采用的两种技术
- pointwise group convolution
- channel shuffle

不足之处
- 大量使用了1×1卷积。——违背了 G2。
- 采用了类似ResNet中的瓶颈层(bottleneck layer),输入和输出通道数不同。——违背了 G1。
- 使用太多分组。——违背了 G3。
- 短路连接中存在大量的元素级Add运算。—— 违背了G4。
ShuffleNetv2 的基本单元
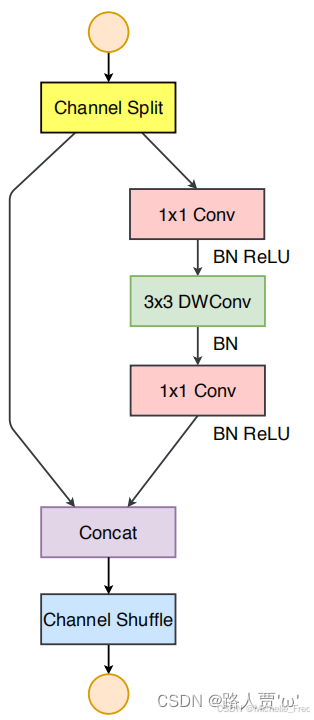
(1)增加了Channel Split操作,实际上就是把输入通道分为2个部分。
(2)根据G1&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









