







先创建一个数据库myhive2019
create database if not exists myhive2019;
在myhive2019数据库下创建内部表 student:
create table student(id int,name string,gender string,age int,department string) row format delimited fields terminated by “,”;
导入数据:
load data local inpath “/home/hadoopUser/students.txt” into table student;

1.分区表
分区是在该表的目录下创建多个文件夹分别存储数据。
关键语法:partitioned by
1.1静态分区
-
创建分区表 student_ptn:
create table student_ptn(id int,name string,age int,department string)
partitioned by(gender string)
row format delimited fields terminated by “,”;注意:分区字段不能与表字段重复。
-
创建分区表后,可以通过show partitions student_ptn;查看是否有分区定义,刚创建出来一般是没有的。

-
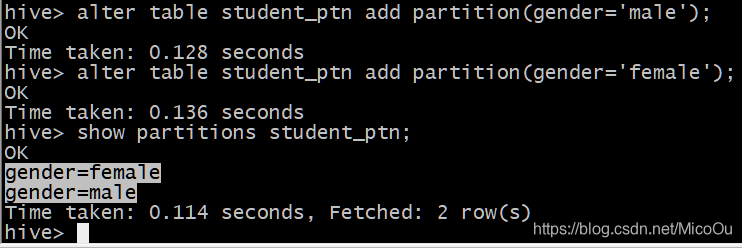
通过alter语法添加一个或多个分区定义(该例子以性别作为分区):
alter table student_ptn add partition(gender=‘male’);
alter table student_ptn add partition(gender=‘female’);
对应地,在HDFS上也能看见创建的分区文件夹,d代表文件夹。

-
往分区表中的分区文件夹下导入数据:
导入数据的方式可查看这篇文章:hive数据导入的6种方式这里主要介绍2种插入方法:
1)insert…values… (一般是用作测试)
insert into table student_ptn partition(gender=‘male’) values(1,“小明”,18,“MA”);2)//单重或多重插入
from 数据表
insert…select…//单重插入
from student
insert into table student_ptn partition(gender=“male”) select id,name,age,department where gender = “男”;//多重插入,insert之间不用逗号分隔
from student
insert into table student_ptn partition(gender=‘male’) select id,name,age,department where gender=“男”
insert into table student_ptn partition(gender=‘female’) select id,name,age,department where gender=“女”;//查询是否
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1893
1893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









