






本文章仅用于学术分享
论文标题丨 UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
论文地址丨 https://arxiv.org/abs/2310.08370
代码地址 | https://github.com/Nightmare-n/UniPAD
关注「AI前沿速递」公众号,获取更多前沿资讯
01总览
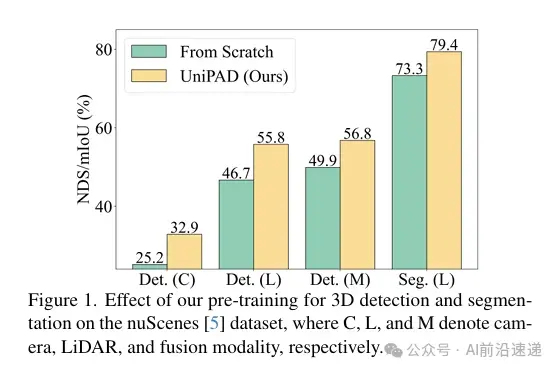
这篇文章介绍了一种名为UniPAD的新型自监督学习范式,专为自动驾驶领域设计。UniPAD利用了3D体积可微分渲染技术,通过隐式编码3D空间,实现了对连续3D形状结构及其2D投影的复杂外观特征的重建。与传统的3D自监督预训练方法相比,UniPAD不仅能够处理2D和3D框架的整合,还能更全面地理解场景。
文章首先指出了自监督学习在3D点云数据中的重要性,尤其是在利用大量未标记数据进行3D目标检测和语义分割等下游任务方面。然而,将2D图像的自监督学习方法扩展到3D点云上存在挑战,这主要是由于数据的固有稀疏性以及传感器布局和场景元素遮挡导致的点分布变化。为了解决这些问题,UniPAD 提出了一种新颖的预训练范式,它消除了复杂正负样本分配的需求,同时通过连续的监督信号隐式地学习3D形状结构。
UniPAD框架的核心在于将遮罩点云作为输入,并通过3D可微分神经渲染重建缺失的2D深度图像上的几何结构。具体来说,该方法首先使用3D编码器提取分层特征,然后将3D特征通过体素化转换到体素空间。接着,应用可微分体积渲染方法重建完整的几何表示。此外,为了在训练阶段保持效率,文章还提出了一种针对自动驾驶应用设计的内存高效光线采样策略,这可以显著降低训练成本和内存消耗。
通过在nuScenes数据集上进行的广泛实验,UniPAD证明了其方法的优越性和泛化能力。在3D目标检测和3D语义分割任务上,UniPAD分别实现了9.1和6.1 mIoU的提升,超越了基于对比和MAE的方法。值得注意的是,UniPAD在nuScenes验证集上达到了73.2 NDS的3D目标检测和79.4 mIoU的3D语义分割,取得了与先前方法相比的最先进结果。
文章还探讨了UniPAD在不同视图变换、不同模态输入以及不同骨干网络规模上的有效性。实验结果表明,无论是在2D图像还是3D点云上,UniPAD都能显著提高基线模型的性能。此外,文章还进行了消融研究,分析了遮罩比例、渲染设计、光线采样策略、特征投影和预训练组件对性能的影响。
最后,文章指出了UniPAD的一些局限性,例如需要将点和图像特征显式地转换为体积表示,这可能会随着体素分辨率的提高而增加内存使用量。尽管如此,UniPAD在自动驾驶领域的3D感知任务中展现出了巨大的潜力,并为未来的研究提供了新的方向。
02研究背景
这篇文章的研究背景集中在自动驾驶领域中3D感知任务的重要性和挑战上。随着自动驾驶技术的发展,车辆需要准确地理解和解释其周围的三维环境,这包括对周围物体的检测、分类和定位,以及对道路和交通状况的语义理解。为了实现这些功能,车辆依赖于各种传感器,如摄像头、激光雷达(LiDAR)和雷达,这些传感器能够提供丰富的数据源。
然而,尽管传感器技术不断进步,如何有效地从这些数据中提取有用信息仍然是一个技术挑战。传统的基于2D图像的方法在自动驾驶中的应用受到限制,因为它们无法充分利用3D空间信息。为了克服这些限制,研究者们开始探索3D点云数据的自监督学习方法,这些方法可以利用未标记的数据来学习特征表示,从而提高自动驾驶系统的性能。
自监督学习是一种无监督学习方法,它尝试通过预测数据本身的某些属性来学习数据的表示,而不是依赖于外部的标注信息。在2D图像领域,自监督学习已经取得了显著的进展,但在3D点云数据上的应用却面临着更多的挑战。这些挑战包括数据的稀疏性、由于传感器布局和场景元素遮挡导致的点分布的不均匀性,以及缺乏有效的3D数据预训练方法。
文章中提到,尽管已经有一些尝试将2D自监督学习的方法扩展到3D点云,但这些方法通常需要复杂的正负样本分配,并且可能受到计算资源的限制。此外,这些方法可能无法充分捕捉3D数据的复杂几何和语义信息。为了解决这些问题,文章提出了UniPAD,这是一种新颖的自监督学习范式,它通过3D体积可微分渲染技术来隐式编码3D空间,从而实现对连续3D形状结构及其2D投影的复杂外观特征的重 建。
UniPAD的研究背景强调了在自动驾驶领域中,开发一种能够处理3D数据并从中学习有效特征表示的方法的重要性。这种方法应该能够整合来自不同传感器的数据,处理数据的稀疏性和不均匀性,并能够适应不同的自动驾驶任务,如3D目标检测和语义分割。通过在nuScenes等具有挑战性的数据集上进行广泛的实验,UniPAD展示了其在提高3D感知任务性能方面的潜力。
总的来说,这篇文章的研究背景是基于自动驾驶领域对于高效、准确的3D感知能力的需求,以及现有自监督学习方法在处理3D点云数据时面临的挑战。UniPAD的提出是为了克服这些挑战,通过创新的3D渲染技术,为自动驾驶车辆提供更加强大和灵活的3D环境理解能力。
03方法
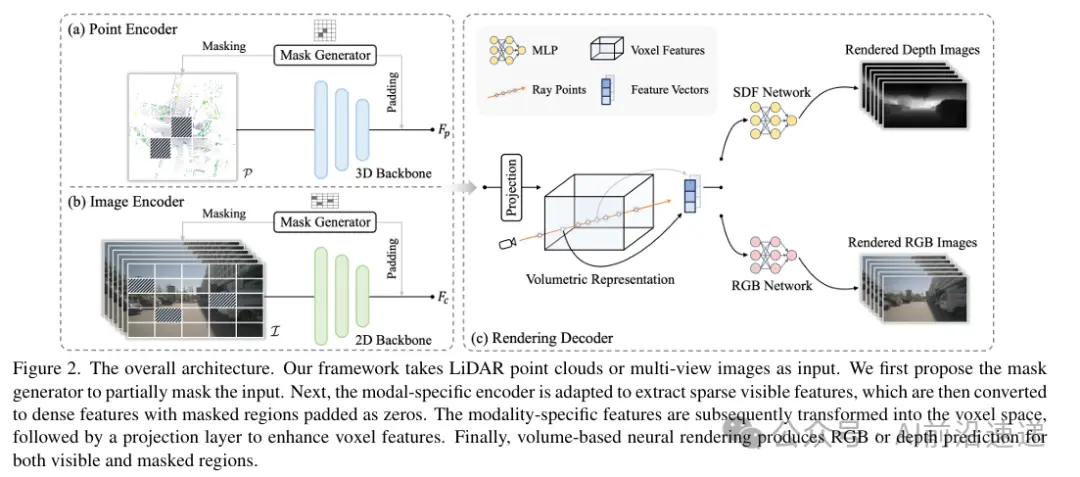
国际惯例先看图。上图展示了UniPAD框架的总体架构,它是一个能够适应不同模态输入(例如3D 激光雷达点云和多视图图像)的通用预训练范式。该框架由两部分组成:模态特定的编码器(Modal- specific Encoder)和体积渲染解码器(Volumetric Rendering Decoder)。
首先,模态特定的编码器负责处理输入数据。对于3D激光雷达点云(P),使用点编码器(如 VoxelNet)提取分层特征(Fp)。对于多视图图像(I),则利用经典的卷积网络提取图像特征(Fc)。为了捕获数据中的高级信息和细粒度细节,UniPAD还采用了多尺度特征金字塔网络(FPN),以有效地聚合多尺度特征。
接下来,文章介绍了遮罩生成器(Mask Generator),它是一种数据增强手段,通过选择性地移除输入数据的某些部分来增加训练难度。对于点云或图像,采用分块遮罩(block-wise masking)来模糊特定区域。遮罩区域根据输出特征图的大小生成,然后上采样至原始输入分辨率。对于点云,通过移除遮罩区域内的信息来获取可见区域;对于图像,则使用稀疏卷积仅在可见位置计算。编码后,被遮罩的区域用零填充,并与可见特征结合,形成规则的密集特征图。
为了使预训练方法适用于不同的模态,文章提出了将两种模态都转换为3D体积空间的统一3D体积表示方法。对于多视图图像,采用视图变换将2D特征转换到3D自我车辆坐标系中,以获得体积特征。对于3D点模态,直接保留点编码器中的高维度信息。
最后,文章描述了神经渲染解码器(Neural Rendering Decoder),它使用不同的可微分体积渲染技术来渲染每个射线的颜色或深度。这种灵活性进一步促进了3D先验信息的整合,通过额外的深度渲染监督实现。文章展示了基于渲染解码器的渲染RGB图像和深度图像,利用隐式符号距离函数(SDF)场来表示高质量的几何细节。
此外,为了解决自主驾驶场景中计算资源的限制,文章设计了三种内存友好的光线采样策略:膨胀采样(Dilation Sampling)、随机采样(Random Sampling)和深度感知采样(Depth-aware Sampling)。这些策略通过仅渲染一部分光线来减少内存使用和计算成本,同时通过专注于场景中最相关的部分来增强学习到的表示。
下面是分节的方法详述。
1、模态特定的编码器 (Modal-specific Encoder)
UniPAD框架接受3D激光雷达点云或多视图图像作为输入。输入数据首先通过遮罩生成器进行部分遮罩,然后送入模态特定的编码器。对于点云数据,采用点编码器(例如VoxelNet)提取分层特征;对于图像数据,则使用经典的卷积网络提取特征。为了捕获数据中的多尺度信息,UniPAD还采用了特征金字塔网络(FPN)。
2、统一3D体积表示 (Unified 3D Volumetric Representation)
为了使预训练方法适用于不同的数据模态,UniPAD将点云和图像数据转换为3D体积空间,以保留尽可能多的原始视图信息。对于多视图图像,通过视图变换将2D特征映射到3D自我车辆坐标系中,形成体积特征。对于3D点模态,直接在点编码器中保留高度维度。该过程计算如下式:
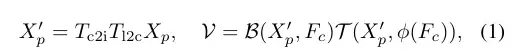
3、神经渲染解码器 (Neural Rendering Decoder)
UniPAD利用神经渲染技术将3D体积特征转换为2D图像。这一过程包括从多视图图像或点云中采样射线,然后使用可微分体积渲染技术为每个射线渲染颜色或深度。这种方法的灵活性允许将3D先验信息整合到获取的图像特征中,通过额外的深度渲染监督实现。最终渲染的RGB值如下计算:
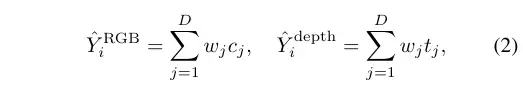
其中不透明度如下计算:
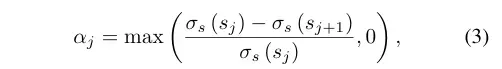
4、可微分渲染 (Differentiable Rendering)
UniPAD使用隐式符号距离函数(SDF)来表示3D场景,这允许表示高质量的几何细节。对于每个射线,通过采样点并使用三线性插值从体积表示中提取特征嵌入,然后预测SDF值和颜色值。
5、内存友好的光线采样策略 (Memory-friendly Ray Sampling)
为了减轻计算负担,UniPAD设计了三种光线采样策略:膨胀采样、随机采样和深度感知采样。这些策略通过仅渲染一部分光线来减少内存使用和计算成本,同时专注于场景中最相关的部分。
6、预训练损失 (Pre-training Loss)
UniPAD的预训练损失由颜色损失和深度损失组成,通过最小化渲染的2D投影与输入数据之间的差异来鼓励模型学习输入数据的连续表示。具体损失如下所示:
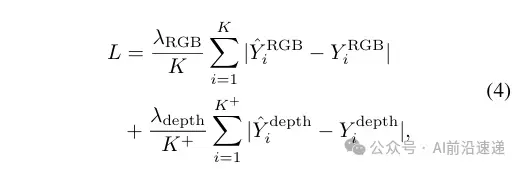
04实验
1、数据集和评估指标
实验在nuScenes数据集上进行,这是一个具有挑战性的自动驾驶数据集,包含700个训练场景、 150个验证场景和150个测试场景。每个场景通过六个不同的摄像头捕获,提供周围视图的图像,并伴有激光雷达点云。数据集具有多样化的注释,支持3D目标检测和3D语义分割任务。对于检测评估,使用 nuScenes检测分数(NDS)和平均精度均值(mAP);对于分割评估,使用平均交并比(mIoU)。
2、实现细节
实验基于MMDetection3D工具包,所有模型在4个NVIDIA A100 GPU上训练。输入图像配置为 1600×900像素,点云体素化为[0.075, 0.075, 0.2]的尺寸。在预训练阶段,实现了数据增强策略,如随机缩放和旋转,以及部分输入遮罩,仅关注特征提取的可见区域。
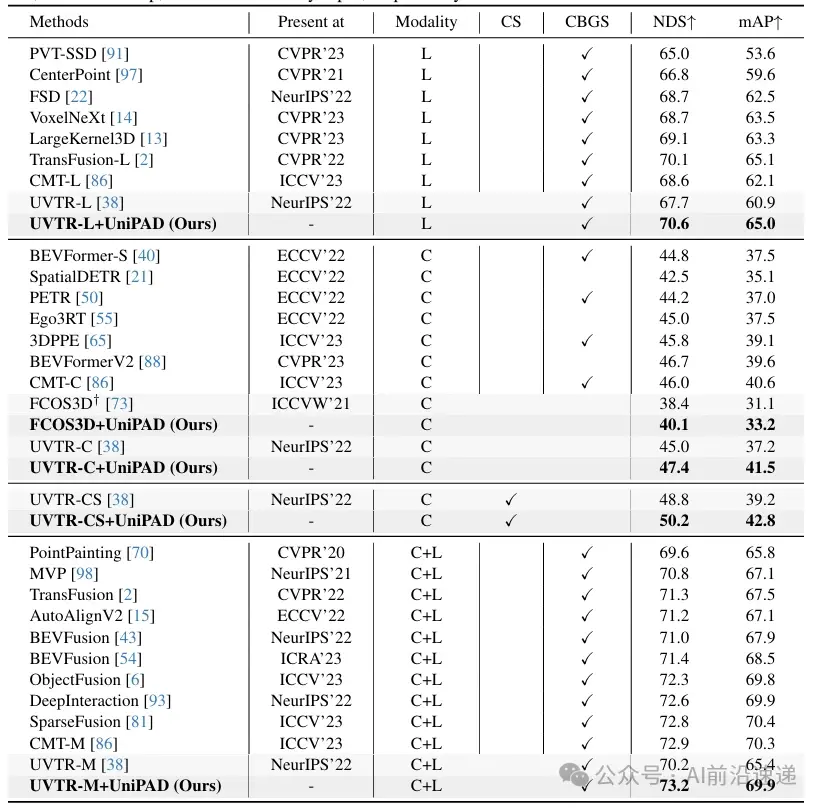
3、与最先进方法的比较
在3D目标检测方面,UniPAD与激光雷达模态(UVTR-L)、相机模态(UVTR-C)、相机扫描模态 (UVTR-CS)和融合模态(UVTR-M)的基线进行了比较。UniPAD通过有效的预训练一致性地提高了基线性能,分别提高了2.9、2.4和3.0 NDS。当使用多帧相机作为输入时,UniPAD-CS在NDS和mAP上分别比UVTR-CS提高了1.4和3.6。预训练技术还在单目基线FCOS3D上实现了1.7 NDS和2.1 mAP的提升。
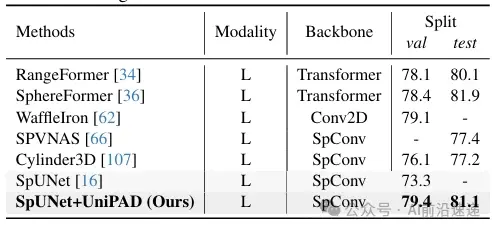
在3D语义分割方面,UniPAD与nuScenes Lidar-Seg数据集上的先前点云语义分割方法进行了比较。UniPAD通过有效的预训练,将基线提高了6.1 mIoU,在验证集上实现了最先进的性能。同时,在测试集上达到了81.1 mIoU,与现有最先进方法相当。
4、预训练方法的比较
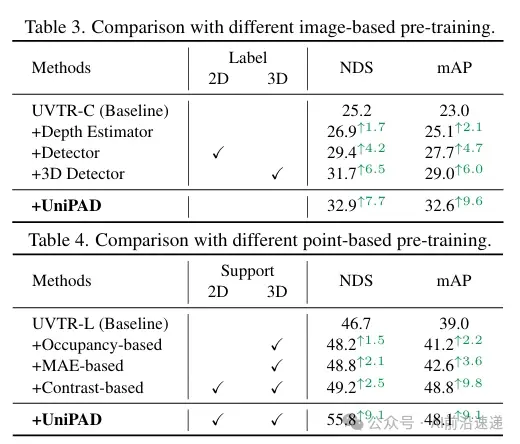
UniPAD与其他基于图像的预训练方法进行了比较,包括深度估计器、基于nuImages数据集的MaskRCNN预训练权重的检测器,以及广泛使用的单目3D检测器的权重。UniPAD展示了比以往无监督或监督预训练方法更优越的知识转移能力。
对于点云模态,UniPAD与最近提出的自监督方法进行了比较,包括基于占用的 ALSO 方法、基于MAE的方法和基于对比的方法。UniPAD在NDS性能上取得了最佳表现。
5、在不同骨干网络上的有效性
UniPAD在不同的视图变换策略上进行了测试,包括BEVDet、BEVDepth和BEVformer。通过将这些方法集成到框架中,将2D特征转换为体积表示,观察到一致的性能提升。
UniPAD还证明了其在不同模态输入上的适用性,包括激光雷达、相机和融合模态。在所有情况下,UniPAD都显著提高了基线性能。

6、扩展到不同骨干网络规模
UniPAD在不同规模的ConvNeXt模型上进行了测试,证明了其在提升各种最先进网络方面的潜力。
7、消融实验
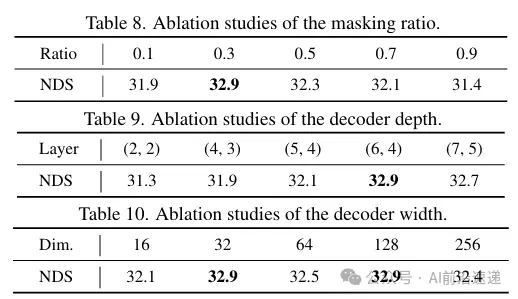
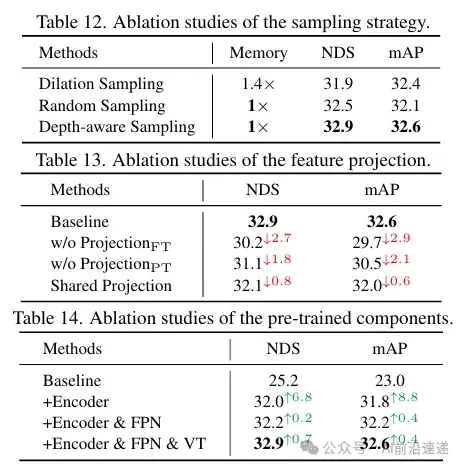
实验部分还包括消融研究,分析了遮罩比例、解码器深度和宽度、渲染技术、光线采样策略、特征投影和预训练组件对性能的影响。这些研究提供了对UniPAD设计选择的深入理解,并证明了各个组件对最终性能的贡献。
05总结
这篇文章提出的UniPAD方法在自动驾驶领域的3D感知任务中展现了多个创新点:
1. 3D体积可微分渲染:
UniPAD采用了新颖的3D体积可微分渲染技术,这允许模型隐式地编码3D空间并重建连续的3D形状结构及其2D投影的复杂外观特征。
2. 自监督学习范式:
文章提出了一种自监督学习范式,专门针对3D数据,无需依赖外部标注信息即可学习有效的特征表示。
3. 统一的3D体积表示:
UniPAD能够将不同模态的数据(如激光雷达点云和多视图图像)转换为统一的3D体积空间,这有助于保持原始数据的深度信息和细节。
4. 灵活性和兼容性:
该方法设计灵活,能够无缝集成到2D和3D框架中,使得它可以在多种自动驾驶任务中应用。
5. 内存高效的光线采样策略:
为了应对自动驾驶场景中的计算挑战,UniPAD引入了内存友好的光线采样策略,减少了训练成本和内存消耗。
6. 显著的性能提升:
在nuScenes数据集上的广泛实验表明,UniPAD在3D目标检测和3D语义分割任务上取得了显著的性能提升,超越了现有的对比和MAE基础方法。
7. 消融研究:
文章通过消融研究深入分析了不同组件对模型性能的影响,提供了对UniPAD设计选择的深入理解。
8. 跨模态和跨骨干网络的适用性:
UniPAD证明了其在不同视图变换、不同模态输入以及不同骨干网络规模上的有效性,显示了其强大的泛化能力。
9. 无复杂正负样本分配:
与需要复杂正负样本选择的对比学习方法不同,UniPAD避免了这种复杂性,同时保持了高效的特征学习能力。
10. 先进的神经网络结构:
UniPAD利用了先进的神经网络结构,如特征金字塔网络(FPN)和隐式符号距离函数(SDF),以增强模型的表征能力。
这些创新点共同构成了UniPAD的核心优势,使其成为自动驾驶领域中一个有前途的自监督学习框架。
关注「AI前沿速递」公众号,获取更多前沿资讯

















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









