






【视觉Transformer】(Vision Transformer, ViT) 是一种革命性的技术,它将Transformer架构应用于视觉识别任务,通过自注意力机制来捕捉图像中的特征关系,显著增强了模型对视觉信息的解析力。这一领域的研究不仅打破了传统卷积神经网络(CNN)在特征提取方面的限制,还为计算机视觉带来了全新的模型设计和更强的表征能力,从而在图像分类、目标检测、语义分割等多个领域实现了性能的飞跃。此外,视觉Transformer的研究深化了我们对深度学习中注意力机制的理解,并激发了模型设计的创新,如通过局部注意力机制降低计算成本,或通过结构性重参数化提高效率。视觉Transformer的进展为处理跨模态任务和大规模视觉识别挑战提供了新的工具,推动了人工智能在视觉识别领域的快速发展。
为了促进对【视觉Transformer】技术的深入理解和创新,我们精心汇总了近两年内该领域在顶级会议和期刊上发表的15篇重要研究成果。这些论文涵盖了最新的理论进展、实验方法和应用案例,同时提供了相应的代码资源,以期为研究人员和实践者提供丰富的学术参考和灵感启发。希望通过这份精心整理的资料,能够帮助大家在视觉Transformer的研究和应用上取得新的突破。

三篇论文解析
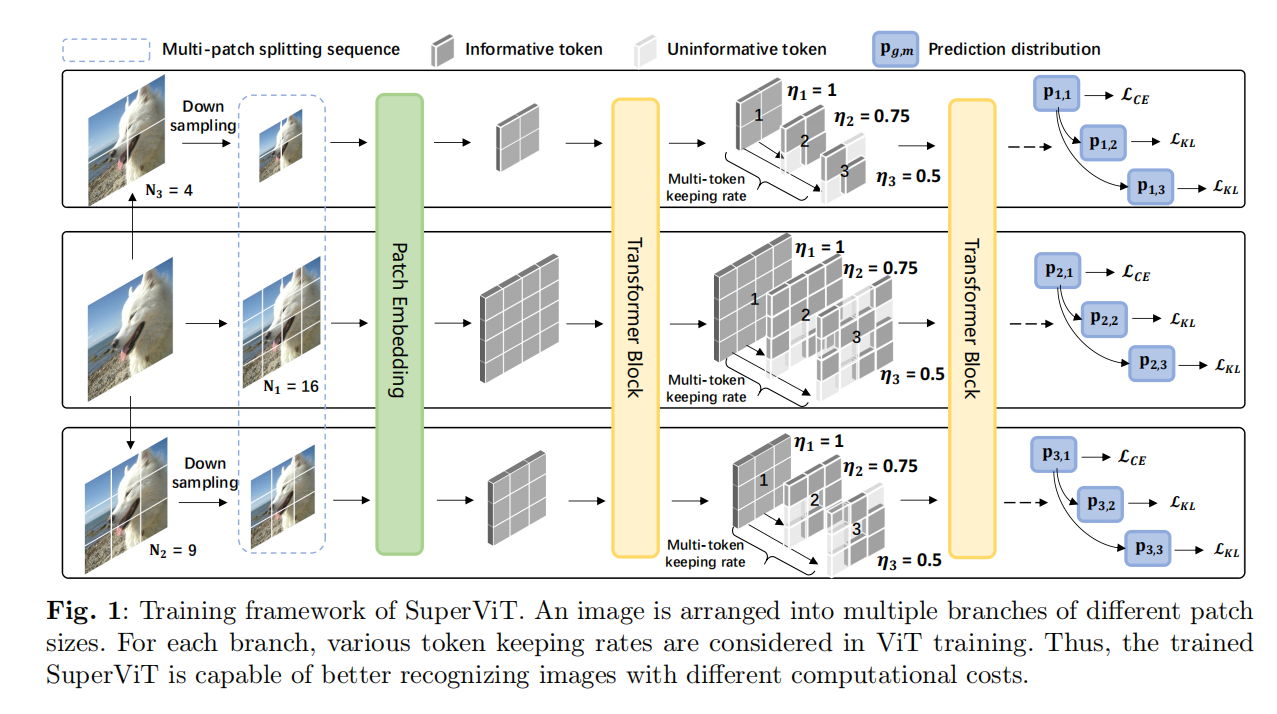
1、Super Vision Transformer: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer
方法
-
SuperViT (Super Vision Transformer): 提出了一种新的训练范式,通过训练一个能够处理不同尺寸输入图像并且能够在多种计算成本下提供改进图像识别性能的ViT模型。
-
多尺寸补丁分割: 将输入图像复制到多个并行分支中,每个分支负责特定尺寸的局部补丁分割,以注入不同尺寸补丁的信息。
-
多令牌保持率: 在训练过程中考虑多种令牌保持率,以挖掘图像中的冗余区域并减少计算成本。
-
硬件效率: SuperViT能够在不同硬件资源条件下动态适应,通过调整输入图像的补丁大小和令牌保持率来实现快速的准确性-效率权衡。
-
训练目标: 使用交叉熵损失和Kullback-Leibler散度来训练SuperViT,以处理不同尺寸的补丁和不同的令牌保持率。
创新点
-
激活稀疏性的重新审视: 提出了一种新的训练范式,使得一个ViT模型能够在保持高分辨率信息的同时,根据当前可用的硬件资源动态调整其复杂性。
-
多尺寸和多保持率的训练: 通过在训练过程中考虑多种补丁尺寸和令牌保持率,SuperViT能够在测试阶段适应不同的计算成本,从而提高性能。
-
硬件效率的优化: SuperViT能够在各种硬件平台上实现高效的部署,甚至在相同工作站上的硬件资源(如电池条件或工作负载)发生变化时,也能够通过简单地调整输入图像的补丁大小和令牌保持率来实现即时和自适应的准确性-效率权衡。
-
提高ViT模型的计算效率: 通过减少令牌数量和在训练过程中注入多尺寸补丁的信息,SuperViT在减少计算成本的同时,甚至能够提高模型的性能。
-
一种新的训练目标: 通过结合交叉熵损失和Kullback-Leibler散度,SuperViT能够在训练过程中同时考虑不同尺寸的补丁和不同的令牌保持率,从而实现更好的性能。
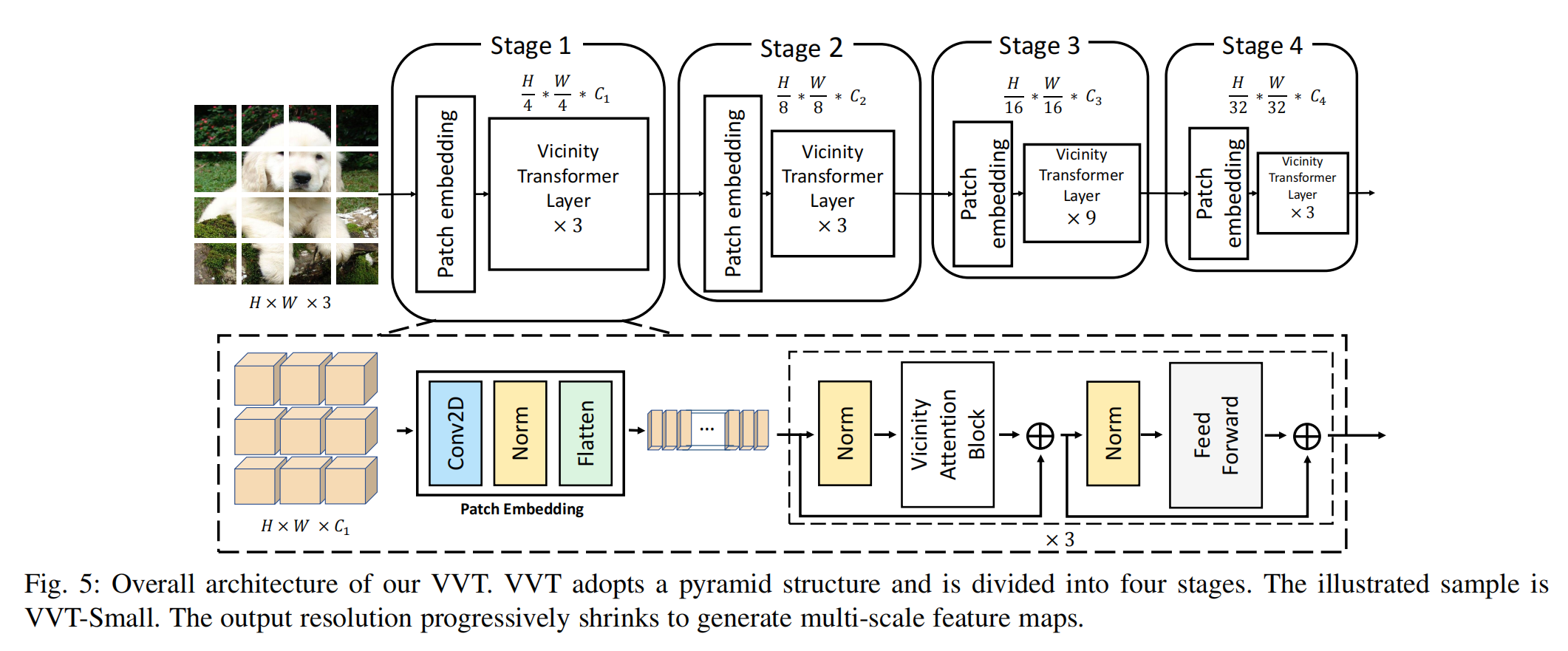
2、Vicinity Vision Transformer
方法
Vicinity Vision Transformer (VVT) 是一种新型的视觉Transformer骨干网络,它通过以下方法来提高视觉任务的性能和计算效率:
-
Vicinity Attention:提出了一种新型的线性注意力机制,称为Vicinity Attention,它通过2D曼哈顿距离来调整图像块之间的注意力权重,从而使相邻的图像块获得更强的注意力。
-
Feature Reduction Attention (FRA):为了解决线性注意力在特征维度上的二次方计算复杂度问题,提出了FRA,它通过减少输入特征维度来降低计算复杂度。
-
Feature Preserving Connection (FPC):为了弥补FRA可能带来的特征信息损失,引入了FPC,它通过额外的跳跃连接来保留原始特征分布,增强特征提取能力。
-
金字塔结构:VVT采用金字塔结构,从高分辨率的图像块开始,逐步缩小尺寸以适应不同视觉任务的多尺度输出需求。
创新点
-
2D局部性引入:VVT首次在视觉Transformer的线性自注意力中引入了2D局部性偏置,这有助于模型更好地理解和处理图像中的局部特征。
-
线性复杂度的自注意力:通过Vicinity Attention,VVT实现了线性复杂度的自注意力计算,这使得模型能够处理更高分辨率的图像,同时保持计算效率。
-
Vicinity Attention Block:提出了一种新的注意力结构,即Vicinity Attention Block,它结合了FRA和FPC,不仅减少了计算量,还保持了模型的准确性。
-
多尺度特征输出:VVT的金字塔结构能够生成不同尺度的特征图,这使得它能够适应各种视觉任务,如图像分类和语义分割。
-
参数和计算效率:在保持或提高性能的同时,VVT在参数数量和计算量上都比现有的Transformer和卷积网络更高效,尤其是在处理高分辨率输入时。
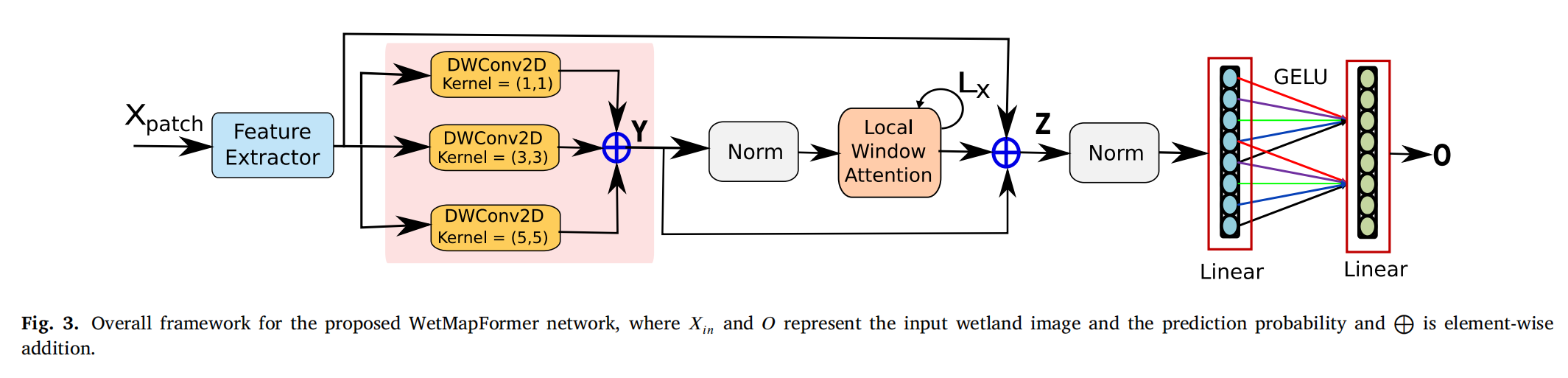
3、WetMapFormer: A unified deep CNN and vision transformer for complex wetland mapping
方法
WetMapFormer 是一种结合了深度卷积神经网络(CNN)和视觉变换器(ViT)的深度学习算法,用于精确映射复杂湿地。具体方法包括:
-
特征提取器:使用3D和2D卷积操作来提取光学和SAR数据的特征。
-
深度可分离卷积块:采用轻量级的CNN架构,通过并行的深度可分离卷积来提取多尺度特征。
-
局部窗口注意力(Local Window Attention, LWA):代替传统的自注意力机制,通过限制每个查询令牌的感受野到其邻域区域,以提高局部特征泛化能力,同时显著降低计算成本。
-
编码器-解码器架构:采用编码器-解码器网络来进一步提取和细化特征。
-
前馈网络(Feed-Forward Network, FFN):使用密集层对特征进行进一步的处理,以生成类别概率。
创新点
-
CNN与ViT的融合:提出了一种新的深度学习框架,有效结合了CNN和视觉变换器架构,以提高湿地分类的准确性。
-
局部窗口注意力(LWA):开发了一种新的注意力机制,与常规的自注意力相比,能够减少计算成本,同时保持特征提取的有效性。
-
计算效率:与原始ViT相比,WetMapFormer通过LWA显著降低了计算成本,使得模型更适合于大规模湿地制图。
-
特征提取的改进:通过3D和2D卷积的结合,以及深度可分离卷积的使用,提高了特征提取的能力,尤其是在处理光学和SAR数据时。
-
数据集和实验验证:在加拿大新不伦瑞克省的三个试点地区使用Sentinel-1和Sentinel-2卫星数据进行了广泛的实验验证,并与多种CNN和视觉变换器模型进行了比较,证明了WetMapFormer的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









