







Hive基于HADOOP来执行分布式程序的,和普通单机程序不同的一个特点就是最终的数据会产生多个子文件,每个reducer节点都会处理partition给自己的那份数据产生结果文件( 通过该命令可以将reduce生成的文件整合到一起:hdfs dfs –getmerge hdfs://<host_name>:8020/user/dayongd/output /tmp/test ),这导致了在HADOOP环境下很难对数据进行全局排序,如果在HADOOP上进行order by全排序,会导致所有的数据集中在一台reducer节点上,然后进行排序,这样很可能会超过单个节点的磁盘和内存存储能力导致任务失败。
一种替代的方案则是放弃全局有序,而是分组有序,比如不求全百度最高的点击词排序,而是求每种产品线的最高点击词排序。
使用order by会引发全局排序,
select * from baidu_click order by click desc;
使用distribute和sort进行分组排序
select * from baidu_click distribute by product_line sort by click desc;
Hive 管理数据的另一种方式就是对数据集进行排序 & 分类,以便于业务查询。在 Hive 中有以下关键词来执行排序 & 分类:
1. ORDER BY (ASC|DESC): 它类似于 RDBMS 中的 Order by 语句,用来确保从每个 Reducer 处理的数据都是排过序的。在 Hive 中,Order by会使用一个 Reducer 进行全局排序(多个 Reducer 之间是无法保证全局有序的)。仅仅使用一个 reducer 也会导致消耗很长的时间,因此,在使用Order by 时可以通过
LIMIT 来限制输出数据。
hive.mapred.mode = strict (默认值是 hive.mapred.mode = nonstrict) 已经设置的时候,我们就不需要指定 LIMIT 。当然也会有例外,具体如下所示:
<span style="font-size:14px;">jdbc:hive2://> SELECT name FROM employee ORDER BY NAME DESC; +----------+ | name | +----------+ | Will | | Shelley | | Michael | | Lucy | +----------+ 4 rows selected (57.057 seconds)</span>
2. SORT BY (ASC|DESC)
: 它用来指示在对 reducer 输入数据进行排序的时候需要对哪个字段进行 order。这样意味着它在数据进入 reducer 前已经完成排序。Sort by 语句不执行全局排序,仅仅是确保每个 reducer 数据都是本地排序过的。我们也可以通过设置 mapred.reduce.tasks=1 来替代 ORDER BY 操作。如下所示:
--使用多个 reducer
--使用 1 个 reducer<span style="font-size:14px;">jdbc:hive2://> <span style="color:#ff0000;">SET mapred.reduce.tasks = 2;</span> No rows affected (0.001 seconds) jdbc:hive2://> SELECT name FROM employee SORT BY NAME DESC; +----------+ | name | +----------+ | Shelley | | Michael | | Lucy | | Will | +----------+ 4 rows selected (54.386 seconds)</span>
<span style="font-size:14px;">jdbc:hive2://> <span style="color:#ff0000;">SET mapred.reduce.tasks = 1;</span> No rows affected (0.002 seconds) jdbc:hive2://> SELECT name FROM employee SORT BY NAME DESC; +----------+ | name | +----------+ | Will | | Shelley | | Michael | | Lucy | +----------+ 4 rows selected (46.03 seconds)</span>
3. DISTRIBUTE BY:
注意:SORT BY & DISTRIBUTE BY 使用场景<span style="font-size:12px;">jdbc:hive2://> SELECT name . . . . . . .> FROM employee_hr DISTRIBUTE BY employee_id; Error: Error while compiling statement: FAILED: SemanticException [Error 10004]: Line 1:44 Invalid table alias or column reference 'employee_id': (possible column names are: name) (state=42000,code=10004) jdbc:hive2://> SELECT name, employee_id . . . . . . .> FROM employee_hr DISTRIBUTE BY employee_id; +----------+--------------+ | name | employee_id | +----------+--------------+ | Lucy | 103 | | Steven | 102 | | Will | 101 | | Michael | 100 | +----------+--------------+ 4 rows selected (38.92 seconds) --使用 Sort By jdbc:hive2://> SELECT name, employee_id . . . . . . .> FROM employee_hr . . . . . . .> DISTRIBUTE BY employee_id SORT BY name; +----------+--------------+ | name | employee_id | +----------+--------------+ | Lucy | 103 | | Michael | 100 | | Steven | 102 | | Will | 101 | +----------+--------------+ 4 rows selected (38.01 seconds)</span>
- Map 输出文件大小不均匀
- Reduce 输出文件大小不均匀
- 小文件过多
- 文件超大
4. CLUSTER BY
: 它是一个用来在相同列族上执行
DISTRIBUTE BY 和 SORT BY 的速记符。CLUSTER BY 语句不支持 ASC / DESC ,只能是默认的倒序排序。与全局排序的 ORDER BY 相比,CLUSTER BY 操作是针对每个分布的组(发送到 reduce 的分区)进行排序的。在做全局排序的时候为了充分利用可用的 reducers,可用先使用CLUSTER BY,再使用 ORDER BY<span style="font-size:14px;">jdbc:hive2://> SELECT name, employee_id . . . . . . .> FROM employee_hr CLUSTER BY name; +----------+--------------+ | name | employee_id | +----------+--------------+ | Lucy | 103 | | Michael | 100 | | Steven | 102 | | Will | 101 | +----------+--------------+ 4 rows selected (39.791 seconds)</span>
从下面这张图可用清晰的发现 ORDER BY 和 CLUSTER BY之间的区别:http://www.crazyant.net/1456.html
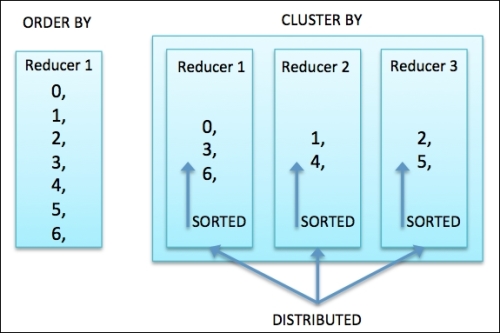
Order by是全局排序,Distirbute + Sort 是分组排序
distribute+sort 的结果是按组有序而全局无序的,输入数据经过了以下两个步骤的处理:
2) 对每个组内部做排序
由于每组数据是按KEY进行HASH后的存储并且组内有序,其还可以有两种用途:
- 直接作为HBASE的输入源,导入到HBASE;
- 在distribute+sort后再进行order by阶段,实现间接的全局排序;
不过即使是先distribute by然后sort by这样的操作,如果某个分组数据太大也会超出reduce节点的存储限制,常常会出现137内存溢出的错误,对大数据量的排序都是应该避免的。
Hive Strict 模式: http://blog.csdn.net/lzm1340458776/article/details/43233639
Hive 中Order by,sort by,distribute by , cluster by 的区别: http://blog.csdn.net/lzm1340458776/article/details/43306115
Hive Order by操作: http://blog.csdn.net/lzm1340458776/article/details/4323051
Hive Group by操作: http://blog.csdn.net/lzm1340458776/article/details/43231707















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









