









讲到B树那就不得不谈一谈查找,查找不是一种数据结构而是一种基于数据结构的对数据进行处理时经常使用的一种操作。平均查找长度ASL=∑Pi×Ci (其中Pi为查找第i个记录的概率,Ci为查找第i个记录所用的比较次数)。 查找方法有很多,分为两大类:静态查找和动态查找。
1、 静态查找:只能进行查找操作,无法进行插入和删除操作,表现为线性结构,有:顺序存储结构和链式存储结构。主要有:顺序查找、二分查找和索引查找。
2、 动态查找:既能插入和删除,又能比较高效率的实现查找操作,一般采用树形链表等非线性结构,主要有:二叉排序树、平衡二叉树、红黑树、B树、B+树、tire树。
(以下内容引用网络)
3、
红黑树:平衡二叉树,通过对任何一条从根到叶子的简单路径上各个节点的颜色进行约束,确保没有一条路径会比其他路径长2倍,因而是近似平衡的。所以相对于严格要求平衡的AVL树来说,它的旋转保持平衡次数较少。用于搜索时,插入删除次数多的情况下我们就用红黑树来取代AVL。
(现在部分场景使用跳表来替换红黑树,可搜索“为啥 redis 使用跳表(skiplist)而不是使用 red-black?”)
4、 B树,B+树:它们特点是一样的,是多路查找树,一般用于数据库系统中,为什么,因为它们分支多层数少,都知道磁盘IO是非常耗时的,而像大量数据存储在磁盘中所以我们要有效的减少磁盘IO次数避免磁盘频繁的查找。B+树是B树的变种树,有n棵子树的节点中含有n个关键字,每个关键字不保存数据,只用来索引,数据都保存在叶子节点。是为文件系统而生。
5、 Trie树:又名单词查找树,一种树形结构,常用来操作字符串。它是不同字符串的相同前缀只保存一份。相对直接保存字符串肯定是节省空间的,但是它保存大量字符串时会很耗费内存(是内存)。类似的有前缀树(prefix
tree),后缀树(suffix tree),radix tree(patricia tree, compact prefix
tree),crit-bit tree(解决耗费内存问题),以及前面说的double array trie。
用阶定义的B树(国内代表:严蔚敏版)(m阶B树):
1.树中每个节点最多m个孩子,即m满足[m/2]<=M<=m;
2.除根节点和叶子节点外,其他每个节点至少[m/2]个孩子;
3.除根节点外,(包括叶子节点)节点关键字数n需要满足:[m/2]-1<=n<=m-1;
用度数定义的B树(算法导论版)(2T阶B树):
1. B树中每一节点包含关键字数有一上界和下界,此下界可用一称作B树的最小度数T表示;
2. 非根节点孩子数满足:T到2T;
3. 非根节点关键字数满足:T-1到2T-1;
树高度:h<=logT*(n+1)/2, 时间复杂度为:O(logn).
B树节点定义如下:
Typedef struct BTNode{
Int n; //关键字个数
Bool isleaf; //是否为叶子节点
Int *keys; //关键字数组
Struct BTNode **child; //节点的孩子们
Struct BTNode *p;}BTNode,*p_BTNode; //节点的父节点B树查找:
B树查找类似于二叉树查找但是B树是进行N+1路分支的判断,所以有所区别,具体代码如下:
BTNode*search(BTNode*curnode,int k,int &index)
{
int i=0;
While(i<=curnod->n&&k>curnode->keys[i])
I++;
If(i<curnode->n&&k==curnod->keys[i])
{
Index=i;
Return curnod;}
If (curnode->isleaf)
Return NULL;
Search(curnode->child[i],k,index)}B树插入(涉及分裂)
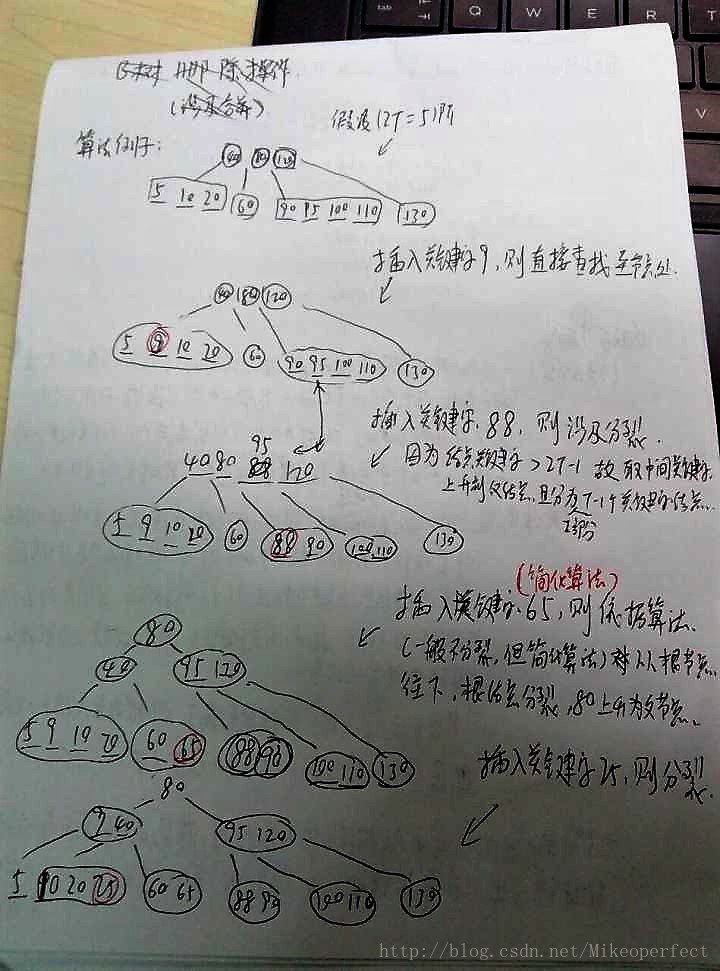
B树插入操作是将关键字插入已存在的叶节点上,沿着根节点一直向下查找,找到合适节点插入,若插入后节点已经满了,即(2T阶树节点最多2T-1个关键字),故将n=2T-1分裂为两个T-1个关键子的子节点,同时中间元素被提升至父节点,若父节点满了,则进行迭代。
具体步骤:
1、 插入若树空,则在叶子节点直接插入,否则非叶子节点,若该节点关键字数小于2T-1则插在该节点左边或者右边;
2、 若该节点关键字数为2T-1,则插入后分裂为2个T-1个关键字的子节点,且中间关键字上移至父节点(当然相应的指针也要发生改变)
3、 若2中使得父节点或根节点满了,则根节点(父节点)也要分裂重复2使得各节点关键字满足(T到2T-1)
(为了简化算法,采用从根节点往下查找时,遇见关键字满的节点,就进行分裂,这样就保证了再次插入后,若节点分裂则父节点一定不为满)
插入示例:
B树的删除(涉及合并)(引用)
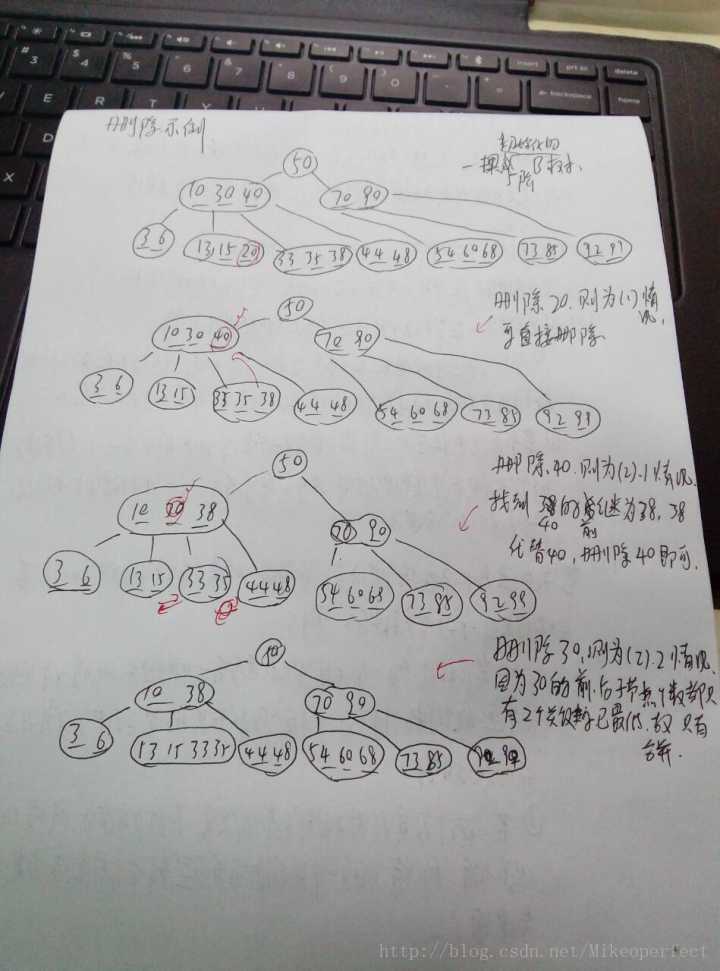
B树的删除操作比插入稍微复杂一些,因为关键词 可以从任意节点中删除
(包括内节点),删除会导致节点含关键词数目过少(小于t-1),所以可能需要进行合并。 B树中从根节点至下删除关键词主要包括以下几种情况(
最小度数为t )。 1) 若关键词k在节点x中且x为叶节点,则从x中删除k; 2) 若关键词k在节点x中且x为内节点,做以下操作:
a) 节点x中位于k之前或之后的子节点y至少有t个关键词,则找出k在以y为根的子树中的前驱或后继k,递归删除k并在x中用k`代替k;
b)
若节点x中位于k之前或之后的子节点y和z都只有t-1个关键词,则将k和z中所有关键词合并进y(使y有2t-1个关键词),再删除z节点,删除k关键词。
3) 若关键词k不在内节点x中,并确定必包含k的子树的根cx[i],若cx[i]只有t-1个关键词,则做以下操作: a)
若cx[i]的一个相邻兄弟至少有t个关键词,则将x中某关键词降至cx[i]中,将cx[i]的相邻兄弟节点的某关键词提升至x,并修改指针;
b) 若cx[i]及其所有相邻兄弟都只有t-1个关键词,则将ci[x]与一个兄弟合并,即将x的一个关键词移至新合并节点成为其中间关键词。
一个包含以上情况的B树删除关键词过程如下所示(最小度数t=2):
删除示例:
使用说明
在本次实验中,为了节省操作时间,偷了个懒,采用的是生成时间种子的方式,通过不断的生成伪随机数去构造一颗B树,所以在实验中,理论上不同的时间我们可以得到不同的B树,同时,在删除的过程中,只要相应的输入需要删除的关键字,就可以得到删除后的新的B树,有利于实验过程的完整性。运行示例:

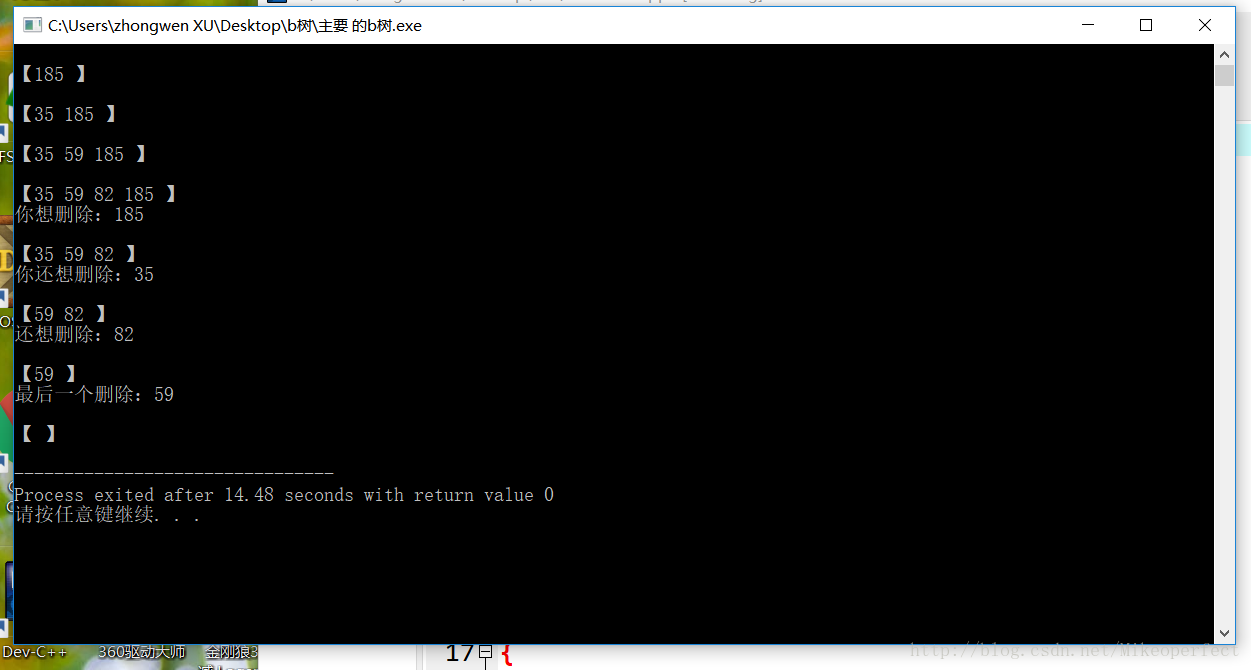
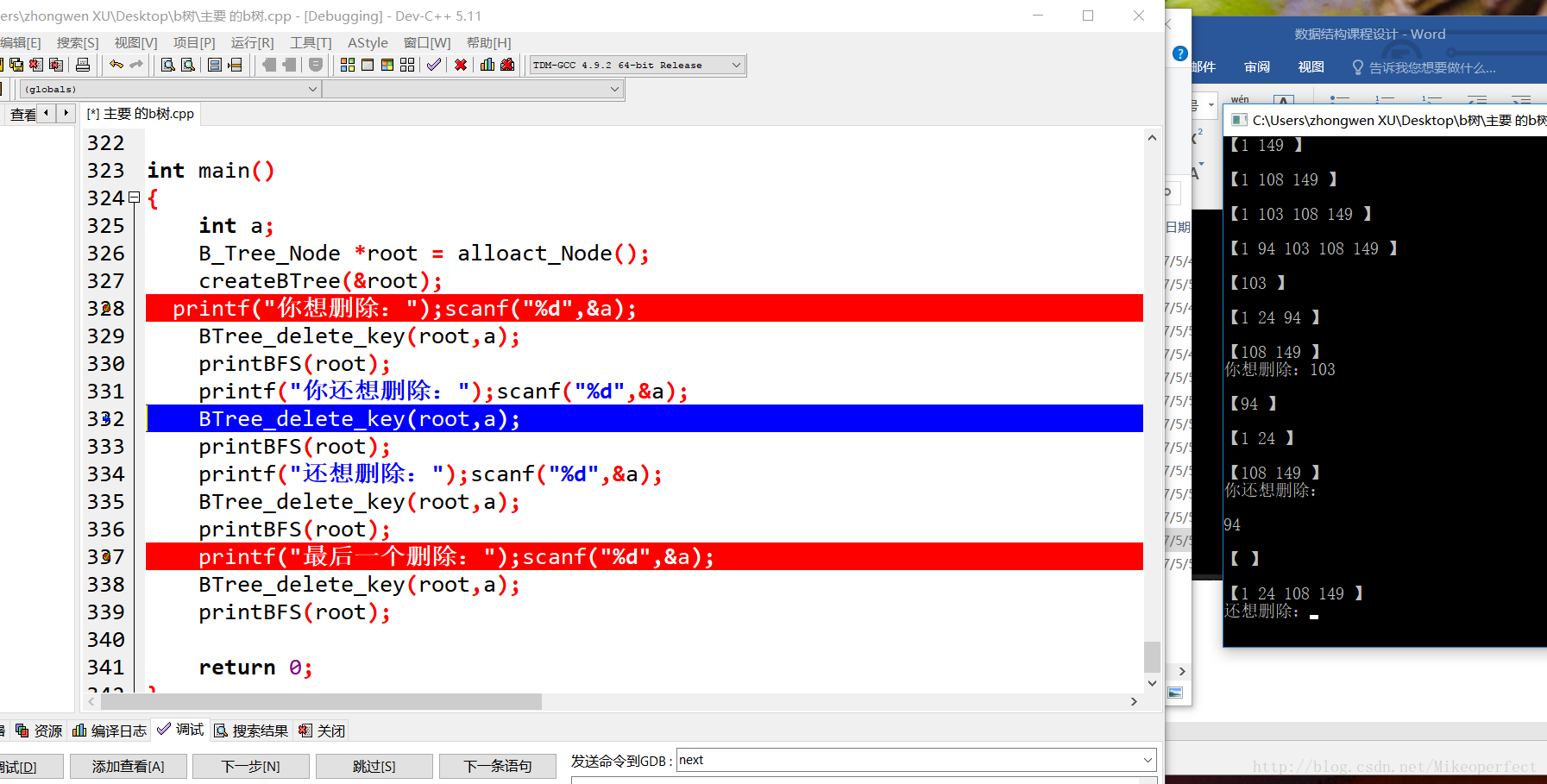
创新点:
为了能够实现每次运行都能够得到不同B树,采用生成时间种子的办法去生成伪随机数来作为B树的关键字来进行插入,同时,为了简化在插入后遇到分裂操作需要反复的调整父节点的关键字的个数,采用了一种简化算法,即从根节点往下查找时,遇见关键字满的节点,就先进行分裂,这样就能够保证再次插入关键字后,若遇见叶节点关键字满而分裂时,父节点一定不为满。
有待改进:
本次实验的B树查找相对简单,插入涉及到的分裂也还好,但是在删除的过程中,因为涉及到的合并操作并不能够完全符合要求,所以结论就是查找和插入没问题,删除只适合低阶B树,鉴于精力有限,只能够日后有时间再仔细的研究了。
(引用)实验代码:(部分参考)
#include <stdio.h>
#include<time.h>
#include<stdlib.h>
#include <iostream>
#define T 3
using namespace std;
typedef struct B_Tree_Node //b树节点定义
{
int n;
int *keys;
bool isLeaf;
struct B_Tree_Node **child ;
struct B_Tree_Node *p;
}B_Tree_Node, *p_B_Tree_Node;
B_Tree_Node *alloact_Node() //b树的初始化
{
B_Tree_Node *newNode = new B_Tree_Node;
newNode->n = 0;
newNode->isLeaf = true;
newNode->keys = new int[2*T-1];
newNode->child = new p_B_Tree_Node[2*T];
newNode->p = NULL;
for(int i=0;i<2*T;i++)
newNode->child[i] = NULL;
return newNode;
}
B_Tree_Node * searchNode(B_Tree_Node *curNode, int k, int &index) //关键字k的查找,返回查找信息
{
int i = 0;
while(i<=curNode->n && k >curNode->keys[i])
i++;
if(i<curNode->n && k == curNode->keys[i]) //找到了k
{
index = i;
return curNode;
}
if(curNode->isLeaf) //如果该结点是叶子结点,则k不存在
return NULL;
searchNode(curNode->child[i],k,index);
}
void BTree_Child_Split(B_Tree_Node *splitNode_p, int index_child) //节点关键字满了的情况,进行分裂
{
B_Tree_Node *newChild = alloact_Node();
newChild->n = T-1;
for(int i = 0;i<T-1;i++)
{
newChild->keys[i] = splitNode_p->child[index_child]->keys[T+i];
}
splitNode_p->child[index_child]->n = T-1;
if(splitNode_p->child[index_child]->isLeaf!=true)
{
newChild->isLeaf = false;
for(int i=0;i<T-1;i++)
newChild->child[i] = splitNode_p->child[i+T];
}
for(int i = splitNode_p->n; i>=index_child;i--)
{
splitNode_p->child[i+1] = splitNode_p->child[i];
}
splitNode_p->n++;
splitNode_p->child[index_child+1] = newChild;
for(int i = splitNode_p->n-1; i>=index_child;i--)
{
splitNode_p->keys[i+1] = splitNode_p->keys[i];
}
splitNode_p->keys[index_child] = splitNode_p->child[index_child]->keys[T-1];
}
void BTree_Insert_NonFull(B_Tree_Node *nonfull, int k) //插入节点关键字k
{
int i = nonfull->n - 1;
if(nonfull->isLeaf)
{
while(i>=0&&k<nonfull->keys[i])
{
nonfull->keys[i+1] = nonfull->keys[i];
i--;
}
i = i+1;
(nonfull->n)++;
nonfull->keys[i] = k;
}
else
{
while(i>=0&&k<nonfull->keys[i])
i--;
i = i+1;
if(nonfull->child[i]->n == 2*T-1)
{
BTree_Child_Split(nonfull,i);
if(k>nonfull->keys[i])
i = i+1;
}
BTree_Insert_NonFull(nonfull->child[i],k);
}
}
void BTree_Insert_Node(p_B_Tree_Node *root,int k) //若根节点满了,调用分裂和插入函数
{
B_Tree_Node *p = *root;
if(p->n == 2*T - 1)
{
B_Tree_Node *newRoot =alloact_Node();
newRoot->child[0] = (*root);
newRoot->isLeaf = false;
*root = newRoot;
BTree_Child_Split(newRoot,0);
BTree_Insert_NonFull(newRoot,k);
}
else
BTree_Insert_NonFull(*root,k);
}
void printBFS(B_Tree_Node *t) //打印出该节点的关键字,且递归打出所有节点关键字
{
if(NULL == t)
return;
cout << "\n【";
for(int i = 0;i < t->n;++i)
{
cout << t->keys[i];
if(t->n - 1 != i)
cout << " ";
}
cout << " 】" << endl;
for(int i = 0;i <= t->n;++i)
printBFS(t->child[i]);
}
void BTree_delete_key(B_Tree_Node *subNode, int k) //删除关键字k,涉及合并
{
int index = 0;
B_Tree_Node *deleteNode = NULL;
if((deleteNode = searchNode(subNode,k,index)) == NULL)
return;
int keyIndex = -1;
for(int i=0;i<subNode->n;i++)
{
if(k == subNode->keys[i])
{
keyIndex = i;
break;
}
}
if(keyIndex != -1 && subNode->isLeaf) //如果在当前结点,且当前结点为叶子结点,则直接删除
{
for(int i=keyIndex;i<subNode->n-1;i++)
{
subNode->keys[i] = subNode->keys[i+1];
}
(subNode->n)--;
}
else if(keyIndex != -1 && subNode->isLeaf!= true) //如果在当前结点中,且当前结点不为叶子结点
{
B_Tree_Node *processorNode = subNode->child[keyIndex];
B_Tree_Node *succssorNode = subNode->child[keyIndex+1];
if(processorNode->n >= T) //如果小于k的孩子结点关键字数大于T
{
int k1 = processorNode->keys[processorNode->n-1];
subNode->keys[keyIndex] = k1;
BTree_delete_key(processorNode,k1);
}
else if(succssorNode->n >=T) //如果大于k的孩子结点关键字数大于T
{
int k1 = succssorNode->keys[0];
subNode->keys[keyIndex] = k1;
BTree_delete_key(succssorNode,k1);
}
else //如果两个孩子结点关键字数均不大于T,则将k与右孩子结点的关键字归并到左孩子中
{
for(int j=0;j<T-1;j++)
{
processorNode->keys[processorNode->n] = k;
processorNode->keys[processorNode->n+1+j] = succssorNode->keys[j];
}
processorNode->n = 2*T -1 ;
if(!processorNode->isLeaf)
{
for(int j=0;j<T;j++)
{
processorNode->child[T+j] = succssorNode->child[j];
}
}
for(int j = keyIndex;j<subNode->n-1;j++) //修改subNode中的key值
{
subNode->keys[j] = subNode->keys[j+1];
}
subNode->n = subNode->n - 1;
delete succssorNode;
BTree_delete_key(processorNode,k);
}
}
else if(keyIndex == -1) //不在当前结点中
{
int childIndex = 0;
B_Tree_Node *deleteNode = NULL;
for(int j = 0;j<subNode->n;j++) //寻找合适的子孩子,以该子孩子为根的树包含k
{
if(k<subNode->keys[j])
{
childIndex = j;
deleteNode = subNode->child[j];
break;
}
}
if(deleteNode->n <= T-1) //如果该子孩子的关键字数小于T,考虑那两种情况
{
B_Tree_Node *LeftNode = subNode->child[childIndex-1]; //deleteNode的左兄弟结点
B_Tree_Node *RightNode = subNode->child[childIndex+1]; //deleteNode的右兄弟结点
if(childIndex>=1 && LeftNode->n >= T) //如果左兄弟结点关键字数大于T,将父结点中的第childIndex-1个元素送给deleteNode,将Left中的最大元素送给父结点,
{
for(int i = deleteNode->n;i>0;i--)
{
deleteNode->keys[i] = deleteNode->keys[i-1];
}
deleteNode->keys[0] = subNode->keys[childIndex];
subNode->keys[childIndex] = LeftNode->keys[LeftNode->n - 1];
(LeftNode->n)--;
(deleteNode->n)++;
BTree_delete_key(deleteNode,k);
}
else if(childIndex<subNode->n && RightNode->n >= T) //如果右兄弟关键字大于T,将父结点中的第childIndex个元素送给deleteNode,将Right中的最小元素送给父结点,
{
deleteNode->keys[deleteNode->n] = subNode->keys[childIndex];
subNode->keys[childIndex] = RightNode->keys[0];
for(int i=0;i<RightNode->n-1;i++)
RightNode[i] = RightNode[i+1];
(RightNode->n)--;
(deleteNode->n)++;
BTree_delete_key(deleteNode,k);
}
//如果左兄弟和右兄弟的关键字数均不在于T,则将左兄弟或右兄弟与其合并
else
{
if(childIndex>=1)//左兄弟存在,合并
{
//将keys合并
for(int i=0;i<deleteNode->n;i++)
{
LeftNode->keys[LeftNode->n+i] = deleteNode->keys[i];
}
//如果非叶子结点,则将叶子也合并
if(!deleteNode->isLeaf)
{
for(int i=0;i<deleteNode->n+1;i++)
{
LeftNode->child[LeftNode->n+1+i] = deleteNode->child[i];
}
}
LeftNode->n = LeftNode->n + deleteNode->n;
//调整subNode的子节点
for(int i = childIndex;i<subNode->n;i++)
{
subNode->child[i] = subNode->child[i+1];
}
BTree_delete_key(LeftNode,k);
}
else //合并它和右兄弟
{
//将keys合并
for(int i=0;i<RightNode->n;i++)
{
deleteNode->keys[i+deleteNode->n] = RightNode->keys[i];
}
//如果非叶子结点,则将叶子合并
if(!deleteNode->isLeaf)
{
for(int i = 0;i<RightNode->n+1;i++)
{
deleteNode->child[deleteNode->n + 1 + i] = RightNode->child[i];
}
}
deleteNode->n = deleteNode->n + RightNode->n;
//调整subNode的子节点
for(int i = childIndex+1;i<subNode->n;i++)
{
subNode->child[i] = subNode->child[i+1];
}
BTree_delete_key(deleteNode,k);
}
}
}
BTree_delete_key(deleteNode,k);
}
}
void createBTree(p_B_Tree_Node *root)
{
int number;
srand((unsigned)(time(NULL)));
number=rand()%11;
int a[number];
for(int i = 0;i<number;i++)
{ a[i]=rand()%200;
BTree_Insert_Node(root,a[i]);
printBFS(*root);
}
}
int main()
{
int a;
B_Tree_Node *root = alloact_Node();
createBTree(&root);
printf("你想删除:");scanf("%d",&a);
BTree_delete_key(root,a);
printBFS(root);
printf("你还想删除:");scanf("%d",&a);
BTree_delete_key(root,a);
printBFS(root);
printf("还想删除:");scanf("%d",&a);
BTree_delete_key(root,a);
printBFS(root);
printf("最后一个删除:");scanf("%d",&a);
BTree_delete_key(root,a);
printBFS(root);
return 0;
} 














 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









