







py", line 160, in <dictcomp> return elem_type({key: default_collate([d[key] for d in batch]) for key in elem}) File "C:\ProgramData\Anaconda3\envs\untitled\lib\site-packages\torch\utils\data\_utils\collate.py", line 141, in default_collate return torch.stack(batch, 0, out=out) RuntimeError: stack expects each tensor to be equal size, but got [224, 224] at entry 0 and [448, 448] at entry 1
以及
RuntimeError: CUDA error: device-side assert triggered CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
<nclass之类的统统都是标签不对应问题,例如我做两分类问题,加上背景nclass应该为3,标签就应该在[0 1 2]之间,如果不设置则会报错,怎么设置标签查看label的像素值,调试中看label
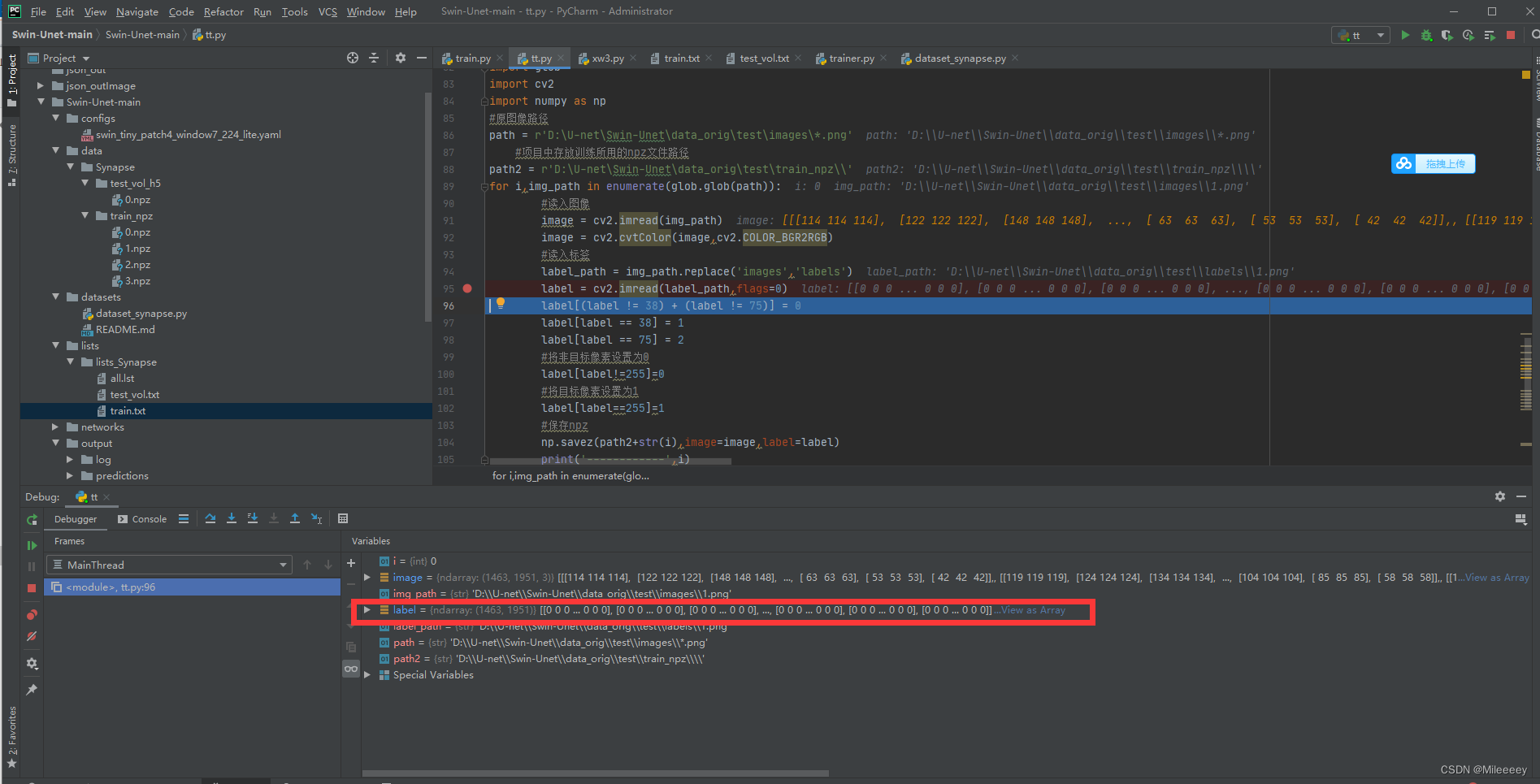
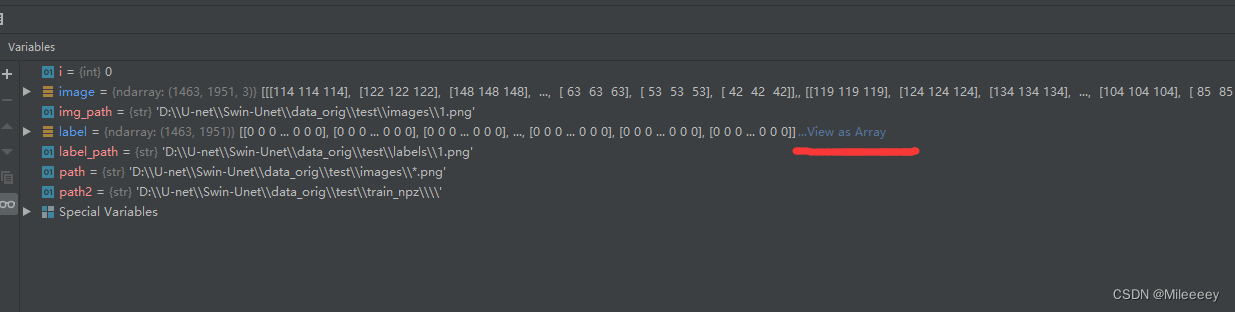
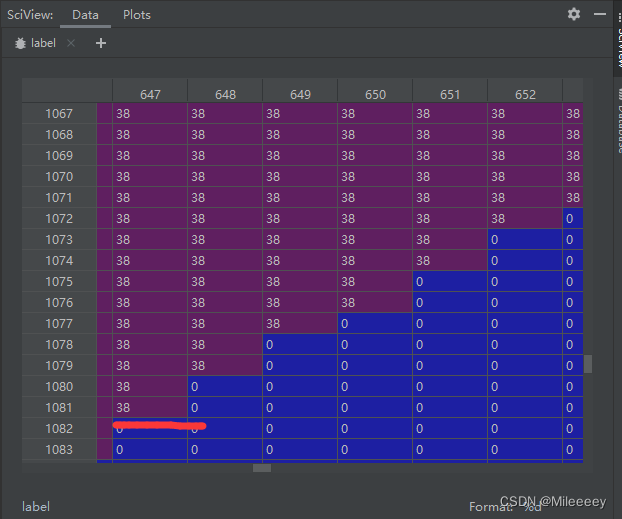
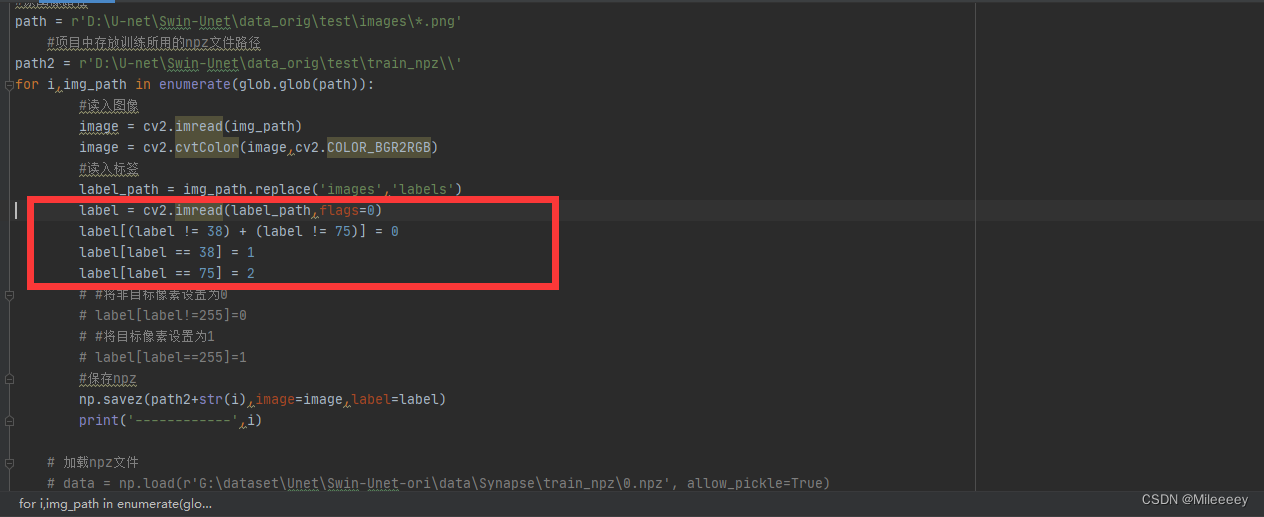 标签设置一定要和像素对应否则无法生成正确的数据集格式。
标签设置一定要和像素对应否则无法生成正确的数据集格式。
数据集制作如果遇到以下这种这种情况无法识别.npz,自己真是找了好久这个问题,是因为train.txt中没错就是写数据集名称的txt文档中多了一个空格!删除最后一行的空格。















 5996
5996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









