









【人工智能项目】深度学习实现汉字书法识别

背景介绍
竞赛数据提供100个汉字书法单字,包括碑帖,手写书法,古汉字等。图片全部为单通道宽度jpg,宽高不定。
数据集介绍
-
训练集:每个汉字400张图片,共计40000张图片,训练集是标注好的数据,图片按照图片上的文字分类到不同的文件夹中,也就是生活文件夹的名字就是文件夹里面所有图片的标签。
-
测试集:
- 第一部分:每汉字100张图片共计10000张图片,供参赛人员测试算法模型
- 第二部分:每汉子50张以上图片共1643张图片,用来评测。
-
提交csv文件
- 文件第一列是测试集中图片文件的文件名,第二列是推断出来的图片上文字可能的五个汉字。
思路
- 提取数据集
- 定义fine-tune模型
- VGG16模型
- ResNet50模型
- Xception模型
- InceptionV3模型
具体流程
提取数据集
# 导入所需的模块
import os
import cv2
import numpy as np
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
# 获取标签的编码器
train_path = "/content/train"
label_char = os.listdir(train_path)
label_char.sort()
encode_label = LabelBinarizer()
encode_label.fit(label_char)
LabelBinarizer(neg_label=0, pos_label=1, sparse_output=False)
# 定义读取图片函数
def get_img(file_path,img_rows,img_cols):
image = cv2.imread(file_path,0)
image = cv2.cvtColor(image, cv2.COLOR_GRAY2RGB)
image = cv2.resize(image,(img_rows,img_cols))
feature = np.array(image,dtype=np.uint8)
return feature
# 定义加载训练集的函数
def load_train_data(train_path,img_rows,img_cols):
x_train = []
y_train = []
dirs = os.listdir(train_path)
for dir_name in dirs:
path = train_path + "/" + dir_name
for img_name in os.listdir(path):
feature = get_img(os.path.join(path,img_name),img_rows,img_cols)
label = dir_name
x_train.append(feature)
y_train.append(label)
# 对y_train进行one-hot编码
y_train = np.array(encode_label.transform(y_train),dtype=np.uint8)
# 对x_train进行转换
x_train = np.array(x_train, dtype=np.uint8)
# 对训练集进行随机打乱,并划分训练集和验证集
x_train,x_valid,y_train,y_valid = train_test_split(x_train,y_train,test_size=0.2,random_state=2019)
return x_train,x_valid,y_train,y_valid
# 定义加载测试集的函数
def load_test_data(test_path,img_rows,img_cols):
x_test_id = []
x_test = []
img_names = os.listdir(test_path)
for img_name in img_names:
feature = get_img(os.path.join(test_path,img_name),img_rows,img_cols)
id = img_name
x_test_id.append(id)
x_test.append(feature)
#对x_test进行转换
x_test = np.array(x_test,dtype=np.uint8)
return x_test,x_test_id
# 加载训练和验证数据和标签
img_rows,img_cols = 224,224
x_train,x_valid,y_train,y_valid = load_train_data(train_path,img_rows,img_cols)
# 加载待预测的数据和标签
test_path = "/content/test2"
x_test,x_test_id = load_test_data(test_path,img_rows,img_cols)
# 查看一下数据和标签
print(x_train.shape)
print(y_train.shape)
print(x_valid.shape)
print(y_valid.shape)
print(x_test.shape)
print(x_test_id[:5])

# 查看一下数据和标签
import matplotlib.pyplot as plt
%matplotlib inline
print(label_char[y_train[0].argmax()])
plt.imshow(x_train[0])
fine-tune模型
选择keras中预训练好的模型,进行fine-tune。
# 导入开发需要的库
from keras import optimizers, Input
from keras.applications import imagenet_utils
from keras.models import *
from keras.layers import *
from keras.optimizers import *
from keras.callbacks import *
from keras.applications import *
from sklearn.preprocessing import *
from sklearn.model_selection import *
from sklearn.metrics import *
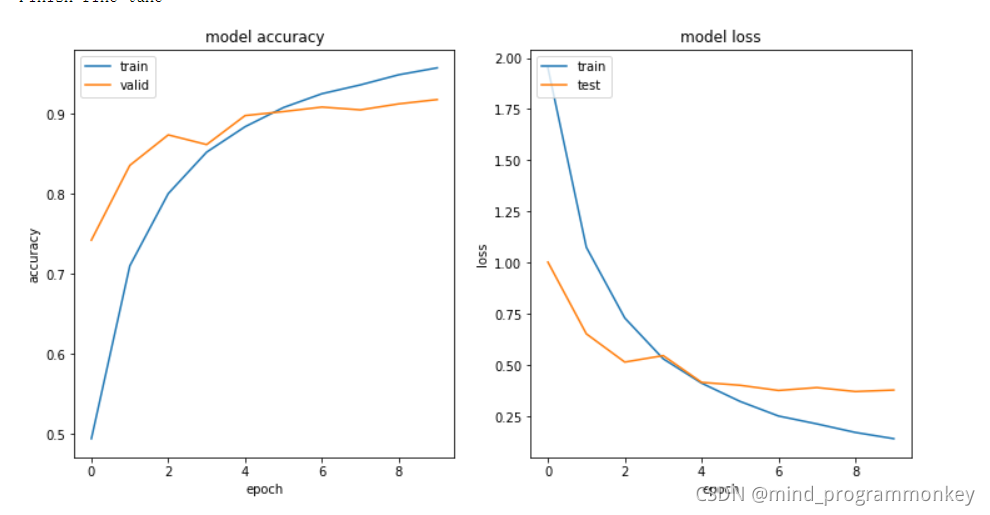
# 绘制训练过程中的 loss 和 acc 变化曲线
import matplotlib.pyplot as plt
%matplotlib inline
def history_plot(history_fit):
plt.figure(figsize=(12,6))
# summarize history for accuracy
plt.subplot(121)
plt.plot(history_fit.history["acc"])
plt.plot(history_fit.history["val_acc"])
plt.title("model accuracy")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(["train", "valid"], loc="upper left")
# summarize history for loss
plt.subplot(122)
plt.plot(history_fit.history["loss"])
plt.plot(history_fit.history["val_loss"])
plt.title("model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
# fine-tune 模型
def fine_tune_model(model, optimizer, batch_size, epochs, freeze_num):
'''
discription: 对指定预训练模型进行fine-tune,并保存为.hdf5格式
MODEL:传入的模型,VGG16, ResNet50, ...
optimizer: fine-tune all layers 的优化器, first part默认用adadelta
batch_size: 每一批的尺寸,建议32/64/128
epochs: fine-tune all layers的代数
freeze_num: first part冻结卷积层的数量
'''
# first: 仅训练全连接层(权重随机初始化的)
# 冻结所有卷积层
for layer in model.layers[:freeze_num]:
layer.trainable = False
model.compile(optimizer='adadelta',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(x=x_train,
y=y_train,
batch_size=batch_size,
epochs=2,
shuffle=True,
verbose=1,
validation_data=(x_valid, y_valid))
print('Finish step_1')
# second: fine-tune all layers
for layer in model.layers[:]:
layer.trainable = True
rc = ReduceLROnPlateau(monitor='val_loss',
factor=0.5,
patience=2,
verbose=1,
min_delta=1e-4,
mode='min')
model_name = model.name + '.hdf5'
mc = ModelCheckpoint(model_name,
monitor='val_loss',
save_best_only=True,
mode='min')
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
history_fit = model.fit(x=x_train,
y=y_train,
batch_size=batch_size,
epochs=epochs,
shuffle=True,
verbose=1,
validation_data=(x_valid, y_valid),
callbacks=[mc, rc])
print('Finish fine-tune')
#展示fine-tune过程中的loss和accuracy变化曲线
history_plot(history_fit)
VGG16
a.定义VGG16模型
# 定义一个VGG16的模型
def vgg16_model(img_rows, img_cols):
x = Input(shape=(img_rows, img_cols, 3))
x = Lambda(imagenet_utils.preprocess_input)(x)
base_model = VGG16(input_tensor=x, weights='imagenet',
include_top=False, pooling='avg')
x = base_model.output
x = Dense(1024, activation='relu', name='fc1')(x)
x = Dropout(0.5)(x)
predictions = Dense(100, activation='softmax', name='predictions')(x)
vgg_model = Model(inputs=base_model.input, outputs=predictions, name='vgg16')
return vgg_model
# 创建VGG16模型
img_rows, img_cols = 224, 224
vgg_model = vgg16_model(img_rows,img_cols)
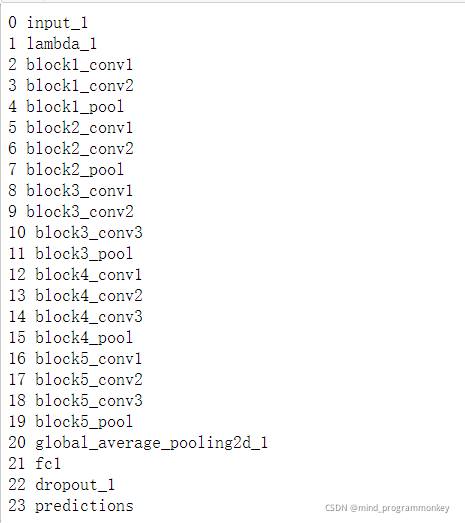
# 列出每一层的序号和名字
for i,layer in enumerate(vgg_model.layers):
print(i,layer.name)
b.VGG16模型训练
# 模型训练
optimizer = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
batch_size = 32
epochs = 10
freeze_num = 19
fine_tune_model(vgg_model, optimizer, batch_size, epochs, freeze_num)

c.VGG16模型预测
# 加载模型权重
vgg_model.load_weights("vgg16.hdf5")
# 获取预测结果
y_preds = vgg_model.predict(x_test)
# 测试预测的结果
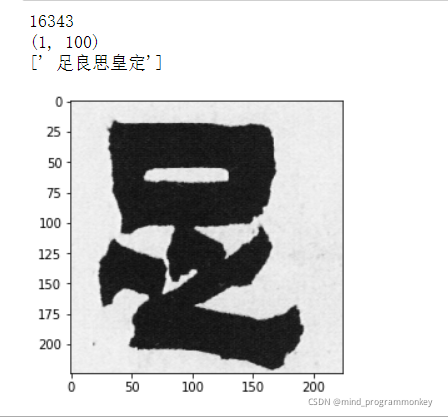
print(x_test.shape[0])
plt.imshow(x_test[2])
test_img = np.expand_dims(x_test[2],axis=0)
y_pred = vgg_model.predict(test_img)
print(y_pred.shape)
labels=[]
pred_dict = {key:value for key,value in enumerate(y_pred[0])}
pred_sorted = sorted(pred_dict.items(), key=lambda item:(-item[1]))
top_5 = " "
for j in range(5):
index = pred_sorted[j][0]
top_5 += label_char[index]
labels.append(top_5)
print(labels)
from pandas import DataFrame
# 定义创建csv文件的函数
def create_submission(y_preds,x_test_id):
labels = []
for i,_ in enumerate(x_test_id):
# key代表预测的character的序号,value代表预测概率
pred_dict = {key:value for key,value in enumerate(y_preds[i])}
pred_sorted = sorted(pred_dict.items(), key=lambda item:(-item[1]))
# pred_sorted: [(k1,v1), (k2,v2), ...]
top_5 = ''
for j in range(5):
index = pred_sorted[j][0]
top_5 += label_char[index]
labels.append(top_5)
result = DataFrame(labels,columns=["labels"])
result.insert(0,"filename",x_test_id)
result.to_csv("submit.csv",index=None)
print("create submission succesfuly")
# 生成csv文件
create_submission(y_preds,x_test_id)
import pandas as pd
# 预览一下提交文件
predict_df = pd.read_csv("submit.csv")
predict_df.head()

ResNet
a.ResNet50模型定义
# 定义一个ResNet50的模型
def restnet50_model(img_rows, img_cols):
x = Input(shape=(img_rows, img_cols, 3))
x = Lambda(imagenet_utils.preprocess_input)(x)
base_model = ResNet50(input_tensor=x, weights='imagenet',
include_top=False, pooling='avg')
x = base_model.output
x = Dense(1024, activation='relu', name='fc1')(x)
x = Dropout(0.5)(x)
predictions = Dense(100, activation='softmax', name='predictions')(x)
resnet_model = Model(inputs=base_model.input, outputs=predictions, name='resnet50')
return resnet_model
# 创建ResNet50模型
img_rows, img_cols = 224, 224
resnet_model = restnet50_model(img_rows,img_cols)
# 列出每一层的序号和名字
for i,layer in enumerate(resnet_model.layers):
print(i,layer.name)
b.ResNet50模型训练
# 模型训练
optimizer = optimizers.Adamax(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
batch_size = 32
epochs = 10
freeze_num = 175
fine_tune_model(resnet_model, optimizer, batch_size, epochs, freeze_num)

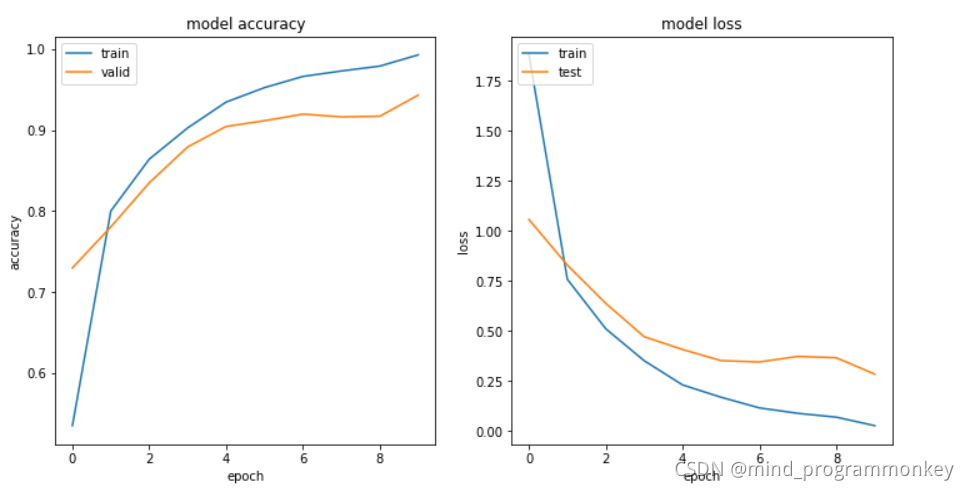
c.ResNet模型预测
# 加载模型权重
resnet_model.load_weights("resnet50.hdf5")
# 获取预测结果
y_preds = resnet_model.predict(x_test)
from pandas import DataFrame
# 定义创建csv文件的函数
def create_submission(y_preds,x_test_id):
labels = []
for i,_ in enumerate(x_test_id):
# key代表预测的character的序号,value代表预测概率
pred_dict = {key:value for key,value in enumerate(y_preds[i])}
pred_sorted = sorted(pred_dict.items(), key=lambda item:(-item[1]))
# pred_sorted: [(k1,v1), (k2,v2), ...]
top_5 = ''
for j in range(5):
index = pred_sorted[j][0]
top_5 += label_char[index]
labels.append(top_5)
result = DataFrame(labels,columns=["labels"])
result.insert(0,"filename",x_test_id)
result.to_csv("submit2.csv",index=None)
print("create submission succesfuly")
# 生成csv文件
create_submission(y_preds,x_test_id)
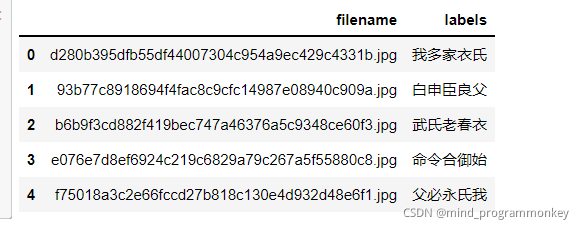
import pandas as pd
# 预览一下提交文件
predict_df = pd.read_csv("submit2.csv")
predict_df.head()
Xception
a.定义Xception模型
# 定义一个Xception的模型
def xception_model(img_rows, img_cols):
x = Input(shape=(img_rows, img_cols, 3))
x = Lambda(imagenet_utils.preprocess_input)(x)
base_model = Xception(input_tensor=x, weights='imagenet',
include_top=False, pooling='avg')
x = base_model.output
x = Dense(1024, activation='relu', name='fc1')(x)
x = Dropout(0.5)(x)
predictions = Dense(100, activation='softmax', name='predictions')(x)
xception_model = Model(inputs=base_model.input, outputs=predictions, name='xception')
return xception_model
# 创建Xception模型
img_rows, img_cols = 224, 224
xception_model = xception_model(img_rows,img_cols)
# 列出每一层的序号和名字
for i,layer in enumerate(xception_model.layers):
print(i,layer.name)
b.Xception模型训练
# 模型训练
optimizer = optimizers.Adamax(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
batch_size = 32
epochs = 15
freeze_num = 132
fine_tune_model(xception_model, optimizer, batch_size, epochs, freeze_num)
c.Xception模型预测
# 加载模型权重
xception_model.load_weights("xception.hdf5")
# 获取预测结果
y_preds = xception_model.predict(x_test)
from pandas import DataFrame
# 定义创建csv文件的函数
def create_submission(y_preds,x_test_id):
labels = []
for i,_ in enumerate(x_test_id):
# key代表预测的character的序号,value代表预测概率
pred_dict = {key:value for key,value in enumerate(y_preds[i])}
pred_sorted = sorted(pred_dict.items(), key=lambda item:(-item[1]))
# pred_sorted: [(k1,v1), (k2,v2), ...]
top_5 = ''
for j in range(5):
index = pred_sorted[j][0]
top_5 += label_char[index]
labels.append(top_5)
result = DataFrame(labels,columns=["labels"])
result.insert(0,"filename",x_test_id)
result.to_csv("submit3.csv",index=None)
print("create submission succesfuly")
# 生成csv文件
create_submission(y_preds,x_test_id)
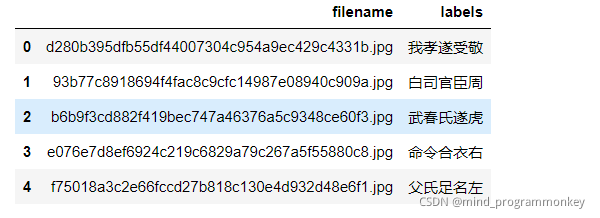
import pandas as pd
# 预览一下提交文件
predict_df = pd.read_csv("submit.csv")
predict_df.head()
InceptionV3
a.InceptionV3模型定义
# 定义一个Inception的模型
def inception_model(img_rows, img_cols):
x = Input(shape=(img_rows, img_cols, 3))
x = Lambda(imagenet_utils.preprocess_input)(x)
base_model = inception_v3.InceptionV3(input_tensor=x, weights='imagenet',
include_top=False, pooling='avg')
x = base_model.output
x = Dense(1024, activation='relu', name='fc1')(x)
x = Dropout(0.5)(x)
predictions = Dense(100, activation='softmax', name='predictions')(x)
inception_model = Model(inputs=base_model.input, outputs=predictions, name='inceptionv3')
return inception_model
# 创建Incpetion模型
img_rows, img_cols = 224, 224
inception_model = inception_model(img_rows,img_cols)
# 列出每一层的序号和名字
for i,layer in enumerate(inception_model.layers):
print(i,layer.name)
b.InceptionV3模型训练
# 模型训练
optimizer = optimizers.Adamax(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
batch_size = 32
epochs = 15
freeze_num = 311
fine_tune_model(inception_model, optimizer, batch_size, epochs, freeze_num)

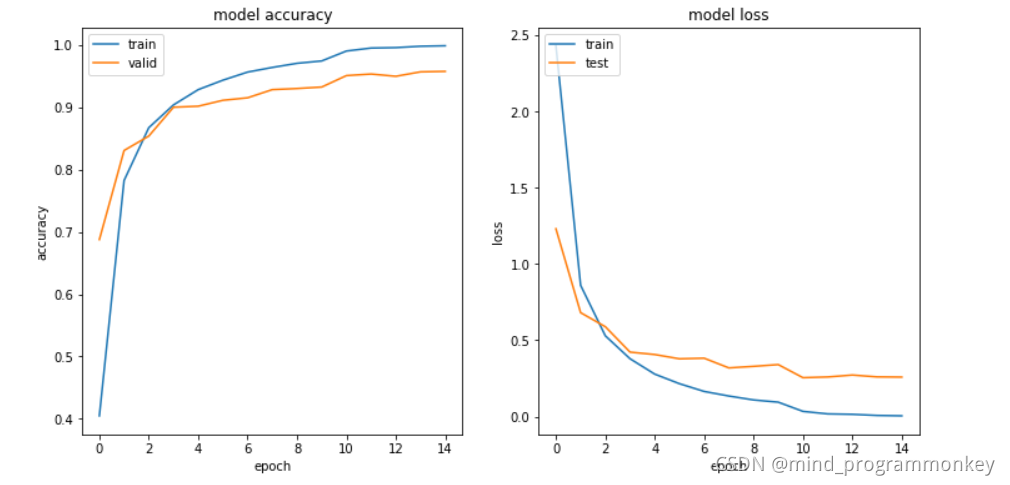
c.InceptionV3模型预测
# 加载模型权重
inception_model.load_weights("inceptionv3.hdf5")
# 获取预测结果
y_preds = inception_model.predict(x_test)
from pandas import DataFrame
# 定义创建csv文件的函数
def create_submission(y_preds,x_test_id):
labels = []
for i,_ in enumerate(x_test_id):
# key代表预测的character的序号,value代表预测概率
pred_dict = {key:value for key,value in enumerate(y_preds[i])}
pred_sorted = sorted(pred_dict.items(), key=lambda item:(-item[1]))
# pred_sorted: [(k1,v1), (k2,v2), ...]
top_5 = ''
for j in range(5):
index = pred_sorted[j][0]
top_5 += label_char[index]
labels.append(top_5)
result = DataFrame(labels,columns=["labels"])
result.insert(0,"filename",x_test_id)
result.to_csv("submit4.csv",index=None)
print("create submission succesfuly")
# 生成csv文件
create_submission(y_preds,x_test_id)
import pandas as pd
# 预览一下提交文件
predict_df = pd.read_csv("submit4.csv")
predict_df.head()

小结
那接着下一个安排走起吧!!!



















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











