







 本文介绍了如何基于深度学习的CNN网络构建手写汉字识别系统,包括数据集的准备、预处理、模型构建、训练与测试,以及使用PyQt实现的用户界面。提供了训练数据集和详细代码示例。
本文介绍了如何基于深度学习的CNN网络构建手写汉字识别系统,包括数据集的准备、预处理、模型构建、训练与测试,以及使用PyQt实现的用户界面。提供了训练数据集和详细代码示例。
基于深度学习的手写汉字识别系统(含PyQt+代码+训练数据集)
前言
本项目是基于深度学习网络模型的人脸表情识别系统,核心采用CNN卷积神经网络搭建,详述了数据集处理、模型构建、训练代码、以及基于PyQt5的应用界面设计。在应用中可以支持手写汉字图像的识别。本文附带了完整的应用界面设计、深度学习模型代码和训练数据集的下载链接。
完整资源下载链接:博主在面包多网站上的完整资源下载页
项目演示视频:
【项目分享】基于深度学习的手写汉字识别系统(含PyQt+代码+训练数据集)
一、数据集
1.1 数据集介绍
本项目的数据集在下载后的data文件夹下,主要分为训练数据集train和测试数据集test,如下图所示。

以训练集为例,如下图所示。其中训练集包含零、一、计、算、机等20个中文手写汉字,图像共计4757张。可以自己添加相应的手写汉字,可获取的 手写中文数据集链接。
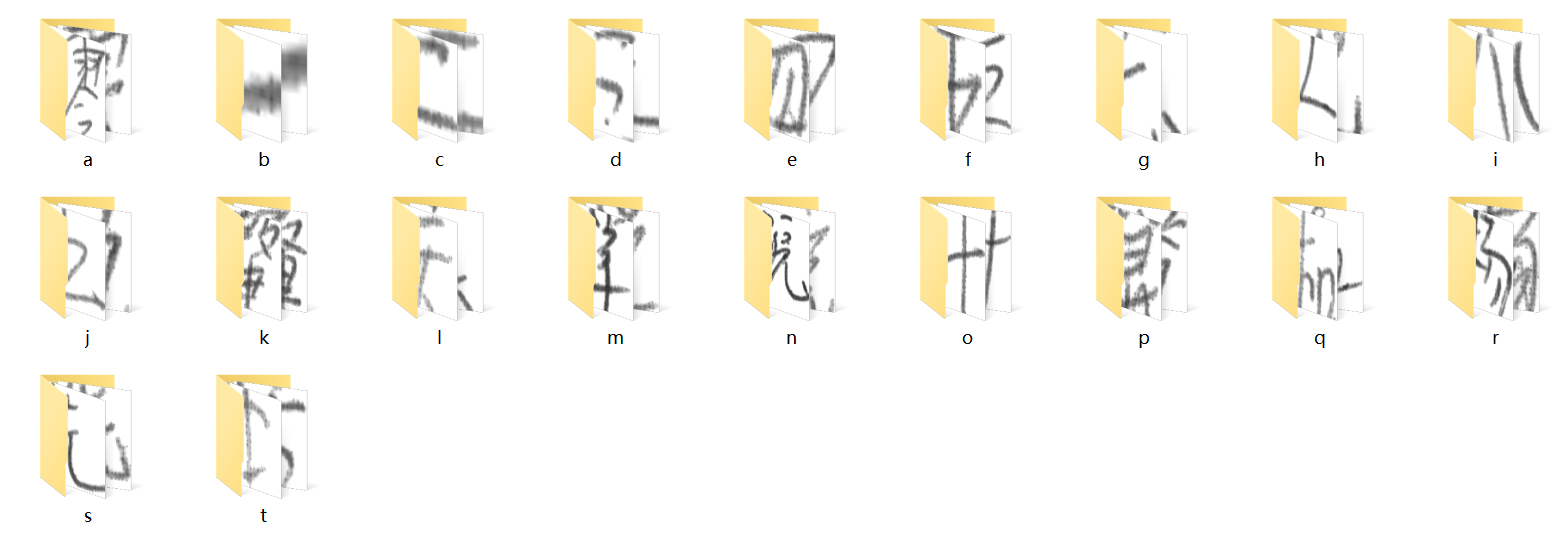
1.2 数据预处理
首先,加载数据集中的图像文件,并将它们调整为相同的大小(64x64)。然后,根据文件所在的目录结构,为每个图像文件分配一个标签(label),标签是根据文件所在的子目录来确定的。最后,使用 train_test_split 函数将数据集划分为训练集和验证集,以便后续模型训练和评估。
def load_data(filepath):
# 遍历filepath下所有文件,包括子目录
files = os.listdir(filepath)
for fi in files:
fi_d = os.path.join(filepath, fi+'/')
if os.path.isdir(fi_d):
global label
load_data(fi_d)
label += 1
else:
labels.append(label)
img = mi.imread(fi_d[:-1])
img2 = cv2.resize(img, (64, 64))
dataset.append(img2)
# 在训练集中取一部分作为验证集
train_image, val_image, train_label, val_label = train_test_split(
np.array(dataset), np.array(labels), random_state=7)
return train_image, val_image, train_label, val_label
二、模型搭建
CNN(卷积神经网络)主要包括卷积层、池化层和全连接层。输入数据经过多个卷积层和池化层提取图片信息后,最后经过若干个全连接层获得最终的输出。CNN的实现主要包括以下步骤:数据加载与预处理、模型搭建、定义损失函数和优化器、模型训练、模型测试。想了解更多关于CNN卷积神经网络的请自行百度。本项目基于tensorflow实现的,并搭建如下图所示的CNN网络模型。

具体代码:
def get_model():
k.clear_session()
# 创建一个新模型
model = Sequential()
model.add(Conv2D(32, 3, padding='same', activation='relu', input_shape=(64, 64, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, 3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, 3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dropout(0.2))
model.add(Dense(512, activation= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6098
6098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









