






概要:通常,对于文件的【存】和【取】的过程,才会涉及字符编码。对于web开发而言,主要涉及以下两个方面: 1. web资源文件(html/js/css)源文件的正确存储、传输、解码。 2. js脚本对字符串进行解码、编码、匹配。
我们会在哪里涉及到字符编码
通常,对于文件的【存】和【取】的过程,才会涉及字符编码。对于web开发而言,主要涉及以下两个方面:
- web资源文件(html/js/css)源文件的正确存储、传输、解码。
- js脚本对字符串进行解码、编码、匹配。
谈及文件的存储和传输,就会涉及到两个概念:大端序(BE)、小端序(LE)和BOM(Byte Order Mark)。
大端序(Big Endian)和小(Little Endian)端序
受较早的时期的cpu影响,cpu在处理存储时存在了两种不同的方案。一种方案是将二进制数据的最高位字节,存储在内存的低地址位置,依次存储——这就是大端序。相反的,低地址位置以数据的低位字节起始,按序存储的方式被成为小端序。
这种由cpu控制的存储顺序机制,一般称为【本机字节序】。另外,在网络传输过程中,约定由网卡处理并发送的二进制数据流,都是大端序——也就是先发送二进制数据的高位字节——我们称之为【网络字节序】。大小端序的存在,由早期不同的加法器等基础硬件的技术实现方案决定,并因为不同的历史原因沿袭下来。目前intel的cpu基本都是LE的,而网络传输过程基本都是BE。
如何确定本机字节序
如果本机具备C语言等可直接访问内存的开发环境,可以定义一串数字,然后直接取内存查看字节数据,验证是否数字的末尾(高位字节数据)处于首地址存储位置。当然,对于web开发而言,也有更简单的办法。
办法1,使用文件确定存储。
- 首先准备一个编辑器(除windows记事本),编辑一份文件,内容可以是连续数字,比如1234567890,然后不添加任何后缀保存。
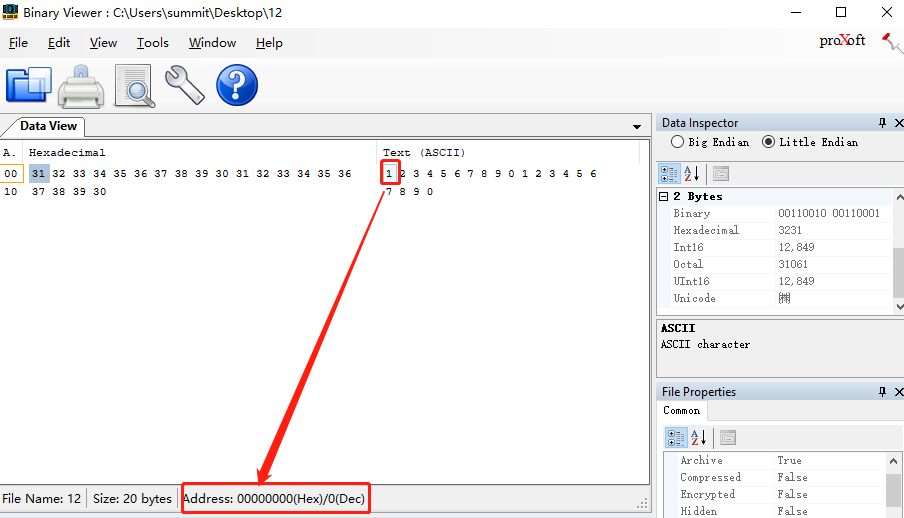
- 使用二进制文件查看器(如Binary Viewer)打开保存的文件并查看。可以看到地址和对应的数据字节所在的位置。如低字节的1处于低地址位置,就是LE类型,如下图:
办法2,在js运行环境下使用DataView对象检查。
var littleEndian = (function() {
var buffer = new ArrayBuffer(2);
new DataView(buffer).setInt16(0, 256, true /* 设置值时,使用小端字节序 */);
// Int16Array 使用系统字节序(由此可以判断系统字节序是否为小端字节序)
return new Int16Array(buffer)[0] === 256;
})();
console.log(littleEndian); // 返回 true 或 false
ArrayBuffer二进制缓冲区对象代表一段申请的连续的存储地址,用来作为二进制数据的缓存器,不允许直接操作。只能通过DataView或TypedArray类对象操作,而TypedArray类对象的操作只能使用默认的本机字节序,用户无法感知字节序的差异。而DataView的set系列方法可以设置二进制数据存储到缓冲区时是否使用小端字节序。
这样通过一份相同的数据,在TypedArray(默认本机字节序)和DataView(设置小端字节序)存储下字节数据是否一致,就可判断本机字节序。
办法3,通过web资源文件的传输和解析。
具体方法在下面介绍。
BOM(Byte Order Mark)
BOM(Byte Order Mark),字节顺序标记,出现在文本文件头部。Unicode编码标准中用于标识文件是采用哪种格式的编码,windows自带记事本会添加三个隐藏字符,用于让记事本等编辑器识别这个文件是否以UTF-8编码。
UTF-8的BOM是固定值,有或者无都可以,因为UTF-8的编码特性,顺序是可以判断的(参第一篇文章中的介绍)。
UTF-16和UTF-32的因为是固定字符的字节宽度的,所以顺序难以确定,BOM有一定价值。
三者具体不同的BOM如下:
| 字节 | 编码格式 |
|---|---|
| EF BB BF | UTF-8 |
| FE FF | UTF-16, big-endian |
| FF FE | UTF-16, little-endian |
| 00 00 FE FF | UTF-32, big-endian |
| FF FE 00 00 | UTF-32, little-endian |
目前的许多文本编辑器,可以将文本文件,指定存储格式(包括指定大端小端序)。
html/js/css文件解码优先级
web资源主要三类html、css、js,这三部分涉及的编码问题是我们比较关心的。当这些文件以不同的编码格式存储、浏览器接收到二进制文件后如何解码,成了解决乱码问题的关键。
我使用了本地文件访问和构建服务器的方式,以此进行交叉比对,得出如下的表格:

对于JS和HTML,文件的编码格式需要和ContentType或charset指明编码类型一致。若使用utf-16或者utf-32,那么最好指明字节序le/be,否则浏览器会使用本机字节序解析。
表中JS本身使用utf-16le存储时,浏览器读取到Content-Type为utf-16头部字段值,会使用默认本机字节序配合utf-16解析,所以不会出问题。但是当JS文件本身是utf-16be时,Content-Type就必须为utf-16be,否则不可。
html/js/css具体的解析凭据和优先级如下介绍。
html的编码解析优先级
- 判断是否有BOM,使用BOM判断字符编码。
- 使用Content-Type响应中配置的charset,若为utf-16/32可配置le/be,未配置使用本机字节序。
- 使用默认编码utf-8解析。
js的编码解析优先级
- 判断是否有BOM,使用BOM判断字符编码。
- 使用Content-Type响应中配置的charset,若为utf-16/32可配置le/be,未配置使用本机字节序。
- 使用script标签的charset配置解读,若为utf-16/32可配置le/be,未配置使用本机字节序。
- 使用默认编码utf-8解析。
css的编码解析优先级
- 判断是否有BOM,使用BOM判断字符编码。
- 使用Content-Type响应中配置的charset,若为utf-16/32可配置le/be,未配置使用本机字节序。
- CSS @规则 @charset,若为utf-16/32可配置le/be,未配置使用本机字节序。
- 使用link元素的 charset 属性,若为utf-16/32可配置le/be,未配置使用本机字节序(Html5标准中已废除)。
- 使用默认编码utf-8解析。
补充
http请求/响应头中会有几个容易混淆的概念,如下:
- 请求头 Accept-Encoding 接受的文件压缩格式,比如gzip。
- 请求头 Accept-Charset 接受的字符编码格式,可配置多个并设置权重。
- 响应头 Content-Type 响应返回的字符编码格式。
html中可使用meta标签配置html解析的元数据(不起作用),可以直接配置 charset 属性(HTML5新属性)
<meta charset="utf-8">
替换了原本的
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
二者都可以,使用新方法可以减少代码量。
正则和字符匹配的重要注意事项
我们在使用过程中,常用的方法中涉及编解码的不多。除了业务、技术方案确实涉及操作二进制数据,比如处理二进制音视频流、自定义加密信息编解码等。我们常用的基本就是使用正则,对于字符串中的字符进行匹配和处理,用的最多的无非正则。
unicode 中对于部分单字节字符,也分配了双字节形式字符的码位,也就是我们常说的半角、全角之分。当然,对于中文而言都是双字节,也就是都是全角,没有半角一说。在unicode范围u+FF00—u+FFEF的240字符中,就包含了ASCII字符的全角形式:
0. 未定义 (1个 u+FF00)
1. ASCII字符的全角形式(94个 u+FF01-u+FF5E)
2. 全角括号 (2个 u+FF5F/u+FF60)
3. 半角CJK标点全角形式(4个 u+FF61-u+FF64)
4. 半角片假名的全角形式(59个 u+FF65-u+FF9F)
5. 半角韩文字符的全角形式(64个 FFA0-FFDF)
6. 全角符号变体(8个 u+FFE0-u+FFE7)
7. 半角符号变体(8个 u+FFE8-u+FFEF)
以ASCII字符a为例,在unicode字符集中,半角形式对应的码位是u+0061,全角形式对应的码位是u+FF41。我们在使用部分输入法输入时感知不到,但是使用正则匹配时就需要注意。
对于字符a而言,正则/\u0061/和/\x61/都能匹配到半角a。正则/\uFF41/则能匹配到全角a。
另外需要注意的是,在js正则中,使用\x加两位16进制数字表示采用ASCII字符集来映射字符——也仅能使用两位16进制。使用\u加四位16进制数字表示采用unicode字符集映射字符——也仅能使用4位。注意二者的含义、范围、使用上区别!
我们在使用正则时,网上有很多说法说匹配什么单字节字符、双字节字符,这些都是错误的说法。这些个说法实际特别不严谨,因为我们使用正则处理字符时,关注的唯一特征是具体什么字符,而非是单字节或者双字节的。因为哪怕某些人所谓的ASCII字符a也有着双字节的存储方式(utf-16),所以某个字节是否是双字节存储的,仅在存储层面有意义——即和使用的字符集编码方式相关。反而和正则匹配无关,所以以下匹配我们说的单字节、双字节,全都是以utf-8编码为条件来谈——因为utf-8是可变字节,对于单双字节有着范围的划分。
字符范围匹配示例
ASCII字符: [\x00-\xff] 或 [\u0000-\u00ff]
utf-8下的单字节(半角)字符。
非ASCII字符:[^\x00-\xff] 或 [^\u0000-\u00ff]
utf-8下的非单字节字符(包括汉字在内),包括启用输入法的全角模式,输入的ASCII字符。
全角字符: [\uff00-\uffef]
实际是部分半角字符对应的全角形式,如上所述。
中文字符: [\u4e00-\u9fa5]
若采用的字符集支持这些unicode字符,就可以展示且正常传输。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









