







一、获取小程序码
与 createQRCode 总共生成的码数量限制为 100,000,请谨慎调用
调用方式
HTTPS 调用
POST https://api.weixin.qq.com/wxa/getwxacode?access_token=ACCESS_TOKEN二、获取小程序二维码
与 wxacode.get 总共生成的码数量限制为 100,000,请谨慎调用
调用方式
HTTPS 调用
POST https://api.weixin.qq.com/cgi-bin/wxaapp/createwxaqrcode?access_token=ACCESS_TOKEN获取不限制的小程序码 getUnlimitedQRCode
接口应在服务器端调用,详细说明参见服务端API。
本接口支持云调用。需开发者工具版本 >=
1.02.1904090(最新稳定版下载),wx-server-sdk>=0.4.0
接口说明
接口英文名
getUnlimitedQRCode
功能描述
该接口用于获取小程序码,适用于需要的码数量极多的业务场景。通过该接口生成的小程序码,永久有效,数量暂无限制。 更多用法详见 获取小程序码。
注意事项
- 如果调用成功,会直接返回图片二进制内容,如果请求失败,会返回 JSON 格式的数据。
- POST 参数需要转成 JSON 字符串,不支持 form 表单提交。
- 调用分钟频率受限(5000次/分钟),如需大量小程序码,建议预生成
获取 scene 值
- scene 字段的值会作为 query 参数传递给小程序/小游戏。用户扫描该码进入小程序/小游戏后,开发者可以获取到二维码中的 scene 值,再做处理逻辑。
- 调试阶段可以使用开发工具的条件编译自定义参数 scene=xxxx 进行模拟,开发工具模拟时的 scene 的参数值需要进行 encodeURIComponent
小程序
Page({
onLoad (query) {
// scene 需要使用 decodeURIComponent 才能获取到生成二维码时传入的 scene
const scene = decodeURIComponent(query.scene)
}
})
小游戏
// 在首次启动时通过 wx.getLaunchOptionsSync 接口获取
const {query} = wx.getLaunchOptionsSync()
const scene = decodeURIComponent(query.scene)
// 或者在 wx.onShow 事件中获取
wx.onShow(function ({query}) {
// scene 需要使用 decodeURIComponent 才能获取到生成二维码时传入的 scene
const scene = decodeURIComponent(query.scene)
})
调用方式
HTTPS 调用
POST https://api.weixin.qq.com/wxa/getwxacodeunlimit?access_token=ACCESS_TOKEN
云调用
-
出入参和HTTPS调用相同,调用方式可查看云调用说明文档
-
接口方法为: openapi.wxacode.getUnlimited
第三方调用
-
调用方式以及出入参和HTTPS相同,仅是调用的token不同
-
该接口所属的权限集id为:17、58
-
服务商获得其中之一权限集授权后,可通过使用authorizer_access_token代商家进行调用
请求参数
| 属性 | 类型 | 必填 | 说明 | |
|---|---|---|---|---|
| access_token | string | 是 | 接口调用凭证,该参数为 URL 参数,非 Body 参数。使用getAccessToken 或者 authorizer_access_token | |
| scene | string | 是 | 最大32个可见字符,只支持数字,大小写英文以及部分特殊字符:!#$&'()*+,/:;=?@-._~,其它字符请自行编码为合法字符(因不支持%,中文无法使用 urlencode 处理,请使用其他编码方式) | |
| page | string | 否 | 默认是主页,页面 page,例如 pages/index/index,根路径前不要填加 /,不能携带参数(参数请放在scene字段里),如果不填写这个字段,默认跳主页面。 | |
| check_path | bool | 否 | 默认是true,检查page 是否存在,为 true 时 page 必须是已经发布的小程序存在的页面(否则报错);为 false 时允许小程序未发布或者 page 不存在, 但page 有数量上限(60000个)请勿滥用。 | |
| env_version | string | 否 | 要打开的小程序版本。正式版为 "release",体验版为 "trial",开发版为 "develop"。默认是正式版。 | |
| width | number | 否 | 默认430,二维码的宽度,单位 px,最小 280px,最大 1280px | |
| auto_color | bool | 否 | 自动配置线条颜色,如果颜色依然是黑色,则说明不建议配置主色调,默认 false | |
| line_color | object | 否 | 默认是{"r":0,"g":0,"b":0} 。auto_color 为 false 时生效,使用 rgb 设置颜色 例如 {"r":"xxx","g":"xxx","b":"xxx"} 十进制表示 | |
| is_hyaline | bool | 否 | 默认是false,是否需要透明底色,为 true 时,生成透明底色的小程序 | |
返回参数
| 属性 | 类型 | 说明 |
|---|---|---|
| buffer | buffer | 图片 Buffer |
| errcode | number | 错误码 |
| errmsg | string | 错误信息 |
调用示例
示例说明: HTTPS调用
请求数据示例
{
"page": "pages/index/index",
"scene": "a=1",
"check_path": true,
"env_version": "release"
}
返回数据示例
{
"errcode": 0,
"errmsg": "ok",
"contentType": "image/jpeg",
"buffer": Buffer
}
示例说明: 云函数调用
请求数据示例
const cloud = require('wx-server-sdk')
cloud.init({
env: cloud.DYNAMIC_CURRENT_ENV,
})
exports.main = async (event, context) => {
try {
const result = await cloud.openapi.wxacode.getUnlimited({
"page": 'pages/index/index',
"scene": 'a=1',
"checkPath": true,
"envVersion": 'release'
})
return result
} catch (err) {
return err
}
}
返回数据示例
{
"errcode": 0,
"errmsg": "ok",
"contentType": "image/jpeg",
"buffer": Buffer
}
三、遇到问题踩坑
1、获取小程序二维码getwxacodeunlimit出现41030
{"errcode":41030,"errmsg":"invalid page rid: 60ed0729-6826af96-2768e17d"}原因:
check_path:默认是true,检查page 是否存在,为 true 时 page 必须是已经发布的小程序存在的页面(否则报错);为 false 时允许小程序未发布或者 page 不存在, 但page 有数量上限(60000个)请勿滥用
env_version:要打开的小程序版本。正式版为 "release",体验版为 "trial",开发版为 "develop"。默认是正式版
解决方案:
1、路径问题
传入的页面路径,pages前不可用加 " / "
正确:‘pages/index/index’
错误:‘/pages/index/index’
2、小程序参数问题
小程序的参数不能超过32个字符
3、小程序是否发布
传入page,生成指定页面的二维码的前提是,小程序必须审核并发布
审核成功并发布的小程序才能正常调用二维码生成接口
错误码
| 错误码 | 错误码取值 | 解决方案 |
|---|---|---|
| -1 | system error | 系统繁忙,此时请开发者稍候再试 |
| 40001 | invalid credential access_token isinvalid or not latest | 获取 access_token 时 AppSecret 错误,或者 access_token 无效。请开发者认真比对 AppSecret 的正确性,或查看是否正在为恰当的公众号调用接口 |
2、小程序码加载不全
博主遇到小程序码加载不全,如下

1、设置图片大小,根据参数 width 设置
2、缓存原因
在图片的路径的后面拼接 '?时间戳' 或者 '?随机数'等,让浏览器和手机认为每次加载的其实不是同一张图片
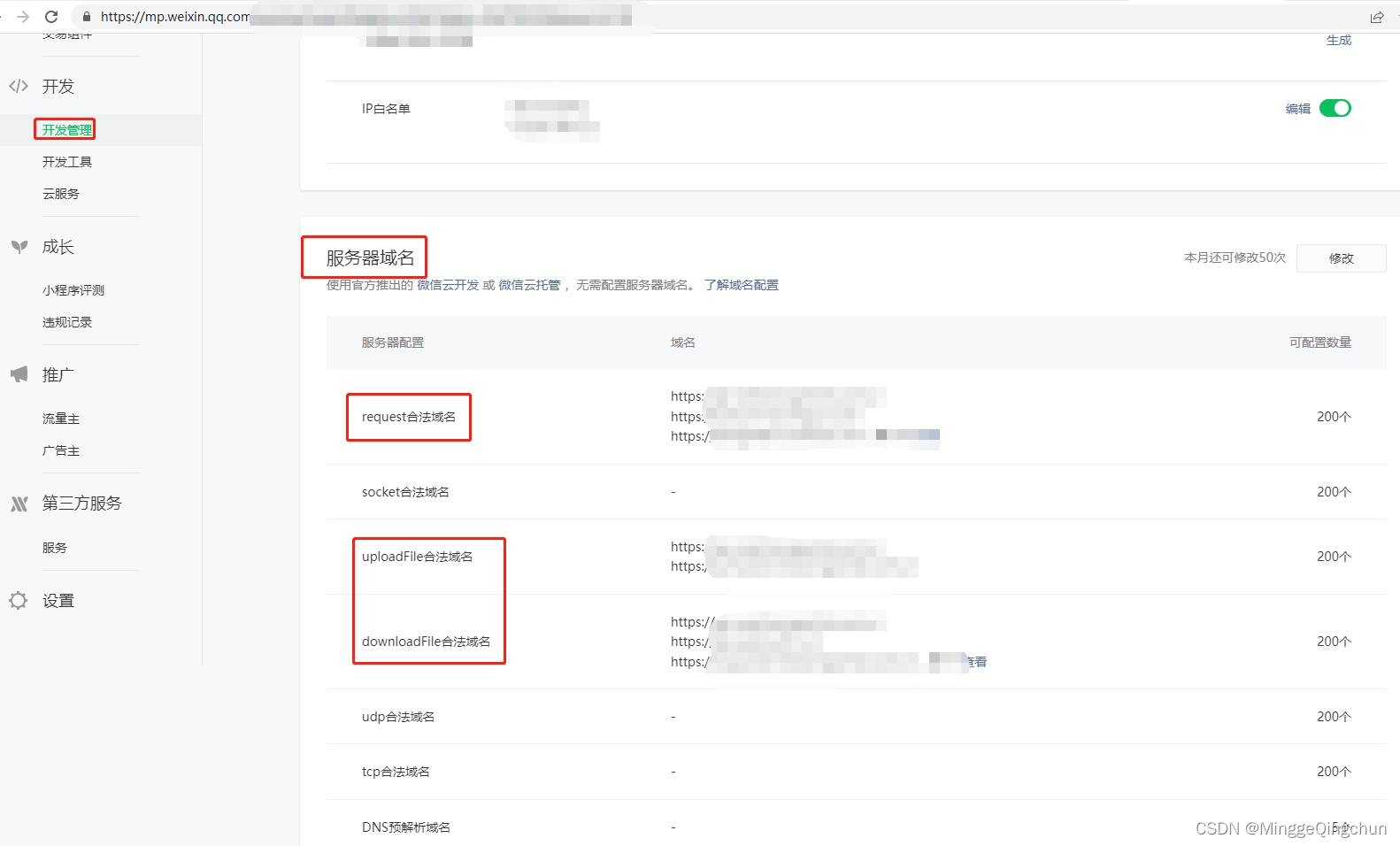
3、检查小程序download和request域名是否配置
开发管理----->开发设置
4、 CDN加载图片资源时,多台服务器中正在下载,或者图片流尚未回源
5、NFS同步图片资源延迟
如何通过Linux系统挂载NFS文件系统_文件存储NAS-阿里云帮助中心

基于文件close/open的CTO一致性
由于超时的最终一致性无法保证ECS-2可以立刻读ECS-1写入的数据。因此,为了提升性能,NFS还提供了基于文件的CTO(close-to-open)一致性保证,即当两个及以上计算节点同时读写相同的文件时,ECS-1的修改在ECS-2不一定能立即看到。但是,一旦ECS-1写入并关闭,之后在任何一个计算节点重新打开该文件都可以保证能访问到新写入的数据。
例如,生产者ECS生产了文件X,生产完毕后执行了close。然后给消息队列发一条消息说,文件X生产完毕。消费者ECS订阅消息队列,读到消息X(文件X生产完毕),此时,消费者ECS再去open这个文件,通过open返回的fd去读取这个文件,则一定能够读到文件X的所有内容。如果消费者ECS在生产者ECS生产完毕之前,就open了文件X,并且持有了fd,当收到消息后,直接用这个fd去读,是不保证能够读取到最新数据的
典型问题
文件创建“延迟”
- 问题现象:
ECS-1创建了文件abc,但是ECS-2需要过一段时间才能看到ECS-1创建的文件abc,有时会延迟1s,有时甚至会到1分钟,这是为什么?
- 问题原因:
这是Lookup Cache导致的,符合预期T时间。例如,ECS-2在ECS-1创建文件abc前进行了访问,导致ECS-2发生文件不存在,于是缓存了一条文件abc不存在的记录。在T时间内,由于FileAttr还没有过期,ECS-2再次访问时,仍会访问第一次缓存到文件abc不存在的记录。
- 解决方案:如果要保证ECS-1创建文件后,ECS-2立即就能看到它,可以使用如下方案:
- 方案一:关闭ECS-2的Nagtive Lookup Cache,不缓存不存在的文件。该方案开销最小。挂载时,添加 lookupcache=positive(默认值 lookupcache=all)字段,挂载命令如下所示:
sudo mount -t nfs -o vers=3,nolock,proto=tcp,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport,lookupcache=positive file-system-id.region.nas.aliyuncs.com:/ /mnt- 方案二:关闭ECS-2的所有缓存。该方案会导致性能非常差,请根据业务实际情况选择合适的方案。挂载时,添加 actimeo=0字段,挂载命令如下所示:
sudo mount -t nfs -o vers=3,nolock,proto=tcp,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport,actimeo=0 file-system-id.region.nas.aliyuncs.com:/ /mnt文件写入延时
- 问题现象:
ECS-1更新了文件abc,但是ECS-2立即去读它,仍然是旧的内容,这是为什么?
- 问题原因:涉及如下两个原因。
- 第一个原因:ECS-1写了abc后,不会立即flush,会先进行PageCache,依赖应用层调用fsync或者close。
- 第二个原因:ECS-2存在文件Cache,可能不会立即去服务端取最新的内容。例如,ECS-2在ECS-1更新文件abc之时,就已经缓存了数据,当ECS-2再次去读时,仍然使用了缓存中的内容。
- 解决方案:如果要保证ECS-1创建文件后,ECS-2立即就能看到它,可以使用如下方案:
- 方案一:CTO一致性,让ECS-1或ECS-2的读写符合CTO模式,则ECS-2一定能读到最新数据。具体来说,ECS-1更新文件后,一定要执行close或者执行fsync。ECS-2读之前,重新open,然后再去读。
- 方案二:关闭ECS-1和ECS-2的所有缓存。该方案会导致性能非常差,请根据业务实际情况选择合适的方案。
- 关闭ECS-1的缓存。挂载时,添加noac字段,保证所有写入立即落盘。挂载命令如下所示:
说明sudo mount -t nfs -o vers=3,nolock,proto=tcp,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport,noac file-system-id.region.nas.aliyuncs.com:/ /mnt
- 如果ECS-1的写操作完成后会调用fsync,或者使用sync写,可以将上面的noac替换为actimeo=0,性能会稍好一点。
- noac等价于
actimeo=0加sync(即,强制所有写入都为sync写)。- 关闭ECS-2的缓存。挂载时,添加actimeo=0字段,忽略所有缓存。挂载命令如下所示:
sudo mount -t nfs -o vers=3,nolock,proto=tcp,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport,actimeo=0 file-system-id.region.nas.aliyuncs.com:/ /mnt

















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









