






在许多制造业领域(尤其是汽车供应和制造行业)中,能力研究的标准样本数量为 30 个零件或部件。
与任何统计计算一样,样本数量对误差有逆效应。 样本数量越大,误差越小。 当我们评估过程的能力时,我们希望尽可能减小误差,因此可能需要更大的样本数量。
为什么要进行过程能力研究? 原因有三点:
1. 为了评估过程行为 – 是稳定/可预测(受控)还是不稳定/不可预测(失控)?
2. 为了评估过程的实际性能是否符合规范,以及过程在未来所生产的部件符合规格的可能性。
3. 为了确定过程可能生产出多少个不符合规格的部件。
30 件规则从何而来?
许多人使用 30 件作为界限,因为他们错误地认为,要使分析“在统计上显著”,他们需要 30 个样本。所以“30”已经成为一个有点随意的数字,人们倾向于认为这个数字足够大。尽管数字 30 在统计中(特别是在 t 分布中)确实起作用,但该数字与正确评估过程行为的能力以及过程能否满足规范之间没有关系。遗憾的是,在此应用中,数字 30 不足以对过程进行正确建模。
在汽车行业,这实际上是 100 件规则!
例如,在由汽车工业行动集团 (AIAG) 发布的统计过程控制 (SPC) 和生产件批准程序 (PPAP) 手册中,将 100 件(20 个子组,每个子组 5 个;或者 25 个子组,每个子组 4 个)定义为适合初始能力研究的样本数量。然而,每个过程都是不同的,因此过程的“正确”数字取决于其变异源。
它是什么呢? 30 件? 100 件? 更多或更少?
与实验或假设检验的设计不同,能力研究与统计功效无关,与变异性有关。在研究中,是否正确地捕获了所有(或最大)的过程变异源?无论采集了多少个样本,都可以通过在能力分析中使用置信区间来获取实际能力的可能范围。范围太大可能表明样本太小。
示例:
假设正态分布中有一个理论总体 (10,000),其均值为 30 毫米,标准差为 1 毫米
规格下限 (LSL) 为 25 毫米,规格上限 (USL) 为 35 毫米,我们知道“实际”能力(为简单起见将使用 Pp)为 1.67:
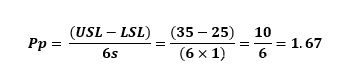
可以看到,在 Minitab 中,使用我们的整个总体,得到的 Pp 为 1.67,这正是我们所期望的。
现在,来看一下在对该总体抽样时得到的 Pp:
场景 1:我们对该总体进行了 100 次抽样,n=30
现在,如果使用 30 件样本对数据进行 100 次抽样,在下图中可以看到,存在巨大的变异性。 总体而言,我们的平均 Pp 为 1.69,接近“实际”值,但样本范围介于 1.19 和 2.44 之间。 实际上,我们在 30 件样本的结果中得到的变异性很大,存在样本 Pp 显著低于和高于实际总体 Pp 的情况。单凭此样本数量,我们可能会得出错误的结论。
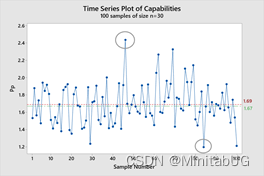
那么,如何确保接近正确的 PP?
捕获可靠 Pp 估计值的一个好方法是使用 Minitab 的置信区间(可在“统计 > 质量工具 > 能力分析 > 选项”中找到)。如果我们对过程进行一次抽样,并抽取 30 件样本,则在打开置信区间后,将得到以下结果:
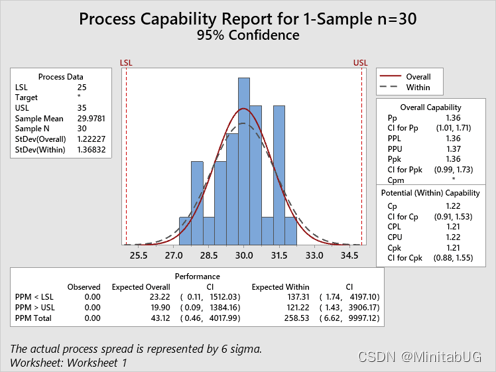
可以看到,基于单个 30 件样本,我们得到的 Pp 值下限为 1.36,这与总体的“实际”能力不太接近,这是另一个不可靠的估计值。如果只看这个数字,我们就会认为我们的过程不可能达到 1.67。
但是,使用 95% 的置信区间会看到可能达到的“实际”能力。而类似我们这里的一个大范围,低至 1.01(按大多数标准来说能力不太大)或高至 1.71(按大多数标准来说能力很大),这是一个指标,表明我们只是不确定该过程是否真正有能力。样本越大,此范围将越小。
结论
通常,样本越大,对实际能力的估计越准确。AIAG SPC 和 PPAP 手册建议样本数量至少为 100 个。 有时,收集样本会很困难或成本高昂。 不论采用哪种方式,使用 Minitab 的置信区间,都会更好地了解变异性并避免因样本数量小而导致的代价高昂的错误。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









