







UTF-8 和 UTF-16 的设计背景与历史
为了更好地理解 UTF-8 和 UTF-16 的设计选择和背景,以下是两种编码方案的历史、设计动机和它们在计算机科学中的应用。
Unicode 的背景
在 Unicode 之前,不同的字符集和编码方案使得跨平台和国际化的文本处理变得复杂且难以维护。例如,ASCII 只能表示 128 个字符,无法满足处理全球所有文字的需求。不同的语言和地区有各自的编码方案,导致了“乱码”和“代码页地狱”等问题。
为了统一全球文字的编码,Unicode 联盟于 1991 年发布了 Unicode 标准,旨在为每一个字符分配唯一的编码点,并定义了一套通用的字符编码体系。
UTF-8 的设计背景与历史
设计背景
- 目标: 为了有效地编码所有 Unicode 字符,同时保持对 ASCII 的完全兼容。
- 网络友好: 需要一种适合于文件和网络传输的编码方案,因为许多互联网协议(如 HTTP 和 SMTP)基于 ASCII。
- 可变长度: 能够紧凑地表示不同语言的字符,尤其是对于占主导地位的英语字符集,应该高效。
- 逐字节处理: 允许通过单字节处理机制进行解码,这对于流媒体和网络数据包的处理特别重要。
历史
- 发明时间: UTF-8 于 1992 年由 Ken Thompson 和 Rob Pike 在贝尔实验室发明。
- 发表: 1993 年,UTF-8 被正式提出,并且在 RFC 2277 中定义为“用于所有文本 MIME 内容的标准格式”。
- 采用: 随着互联网的发展,UTF-8 被广泛采用,尤其在 web 技术和电子邮件传输中。
设计特色
- ASCII 兼容性: UTF-8 使用 1 字节来编码 ASCII 字符,这使得它可以与现有的基于 ASCII 的系统无缝集成。
- 无 BOM 影响: UTF-8 不需要字节序标记(BOM),因为其字节顺序在所有平台上都是一致的。
- 同步性: UTF-8 字符串可以通过前缀字节的模式确定下一个字符的起点,这使得它对流式处理特别有利。
UTF-16 的设计背景与历史
设计背景
- 目标: 提供一种比 UTF-8 更高效的 Unicode 编码,特别是针对 BMP(基本多文种平面)字符的高效处理。
- 固定长度(对于 BMP): 对于 BMP 字符,每个字符使用固定的 2 个字节,便于快速索引和处理。
- 代理对支持: 能够表示超出 BMP 范围的字符,这对于扩展 Unicode 范围至超过 65536 个字符是必要的。
历史
- 发明时间: UTF-16 于 1993 年由 Unicode 联盟发布,是 Unicode 标准的一部分。
- 发展: UTF-16 的前身是 UCS-2,它是一种固定长度的 16 位编码,但只能编码 BMP 范围内的字符。随着 Unicode 的扩展,UTF-16 引入了代理对以支持更多的字符。
- 应用: UTF-16 被广泛用于操作系统和编程语言的内部表示,如 Windows 的内部字符串表示和 Java 的字符存储。
设计特色
- 固定长度处理: 对于大多数常用字符,UTF-16 提供了 2 字节的固定长度,这简化了许多字符处理操作。
- 高效的东亚语言处理: UTF-16 对于东亚文字(如汉字)更为高效,因为这些文字大部分位于 BMP 范围内。
- 代理对机制: 通过使用代理对,UTF-16 可以编码超过 65536 个字符,这对于全面支持 Unicode 的所有字符是必需的。
设计动机和应用场景
-
UTF-8 的设计动机:
- 兼容性: UTF-8 保持了与 ASCII 的兼容性,这使得它成为互联网上的事实标准。
- 灵活性和效率: UTF-8 能够高效地编码 ASCII 字符(1 字节),并且相对高效地编码其他字符(多字节),这使得它在以英文为主的环境中非常高效。
- 无字节序问题: 由于每个字节在 UTF-8 中都有固定的位置,避免了字节序的问题。
- 简化传输和存储: UTF-8 的逐字节处理特点使得它在流媒体、文件传输和文本存储中极具优势。
-
UTF-16 的设计动机:
- 字符集扩展: UTF-16 的设计初衷是为了有效地表示扩展的 Unicode 字符集,尤其是当 Unicode 范围超出 BMP 后。
- 高效处理 BMP 字符: 大多数常用字符(特别是东亚语言)位于 BMP 范围内,因此 UTF-16 可以以 2 字节的固定长度编码这些字符,这对于这些语言的文本处理是高效的。
- 内部使用和处理: 许多操作系统和编程语言(如 Windows 和 Java)选择 UTF-16 作为内部字符表示形式,因其对 BMP 字符的高效处理。
编码机制
-
UTF-8:
- 可变长度编码: UTF-8 使用 1 到 4 个字节来编码 Unicode 字符。
- 1 字节: 0xxxxxxx(适用于 ASCII 范围的字符,0x00 - 0x7F)。
- 2 字节: 110xxxxx 10xxxxxx
- 3 字节: 1110xxxx 10xxxxxx 10xxxxxx
- 4 字节: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- 字节顺序一致: UTF-8 不受字节序影响,即大端序(Big-endian)和小端序(Little-endian)都一样。
- ASCII 兼容: UTF-8 对于 0x00 到 0x7F 的 ASCII 字符使用单字节编码,与 ASCII 完全兼容。
- 可变长度编码: UTF-8 使用 1 到 4 个字节来编码 Unicode 字符。
-
UTF-16:
- 可变长度编码: UTF-16 使用 2 个或 4 个字节来编码 Unicode 字符。
- 基本平面(BMP,0x0000 - 0xFFFF)的字符使用 2 个字节。
- 辅助平面(0x10000 - 0x10FFFF)的字符使用 4 个字节(一个高位代理和一个低位代理)。
- 字节顺序影响: UTF-16 可以是大端序或小端序,通常通过字节序标记(BOM,Byte Order Mark,0xFEFF)来指示。
- 可变长度编码: UTF-16 使用 2 个或 4 个字节来编码 Unicode 字符。
存储效率
-
UTF-8:
- 对于 ASCII 范围的字符(0x00 - 0x7F),UTF-8 使用 1 个字节,存储非常高效。
- 对于非 ASCII 字符,尤其是汉字等需要 3 个字节,这时存储效率较低。
- 对于补充字符(大于 0xFFFF),使用 4 个字节。
-
UTF-16:
- 对于大多数常用字符(BMP 范围内,0x0000 - 0xFFFF),UTF-16 使用 2 个字节。
- 对于超出 BMP 的字符(0x10000 及以上),UTF-16 使用 4 个字节。
- 在以英文为主的文本中,UTF-16 的存储效率较低,但对于东亚文字较高效。
编码特性
-
UTF-8:
- 前向兼容: UTF-8 编码具有前缀的特性,每个字节的高位可以指示字节序列的长度,这样扫描字符时可以确定下一个字符的起始位置。
- 同步容错: 如果遇到无效的字节序列,可以跳过错误部分并继续解码后续部分,不影响整体的解码。
- 按字节处理: 可以逐字节处理,非常适合流媒体和网络传输。
-
UTF-16:
- 固定长度(对于 BMP 字符): 对于 BMP 范围内的字符,每个字符使用 2 个字节,便于快速索引和字符计数。
- 复杂的代理对: 对于补充字符,需要代理对(surrogate pairs),编码和解码较为复杂。
- 适合大字符集: 在需要处理大量非 ASCII 字符的情况下,UTF-16 更高效。
兼容性和应用场景
-
UTF-8:
- 广泛应用于网络传输和文件存储中,尤其适合以英文和数字为主的场景。
- 常用于互联网标准,如 HTML 和 JSON,因其对 ASCII 的良好兼容性。
-
UTF-16:
- 常用于操作系统和编程语言内部,如 Windows 的内部 API 和 Java 的字符串表示。
- 适合处理大量非 ASCII 字符的应用,如东亚文字处理。
总结
- UTF-8: 以可变长度编码字符,具有较好的 ASCII 兼容性和网络传输效率,非常适合以英语为主的文本处理和互联网应用。目前UTF-8快要在互联网一统江湖了
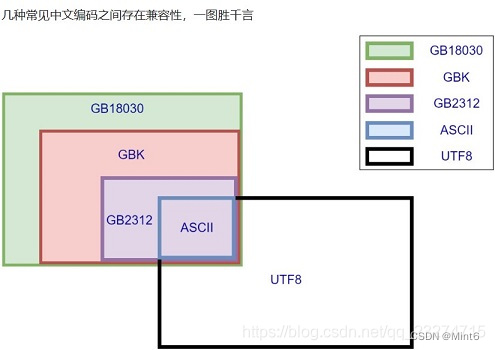
- UTF-16: 适合需要处理大量非 ASCII 字符的场景,虽然占用存储空间较大,但在处理字符时较为高效,适合在内存中存储文本和内部字符处理。
图示比较
-
UTF-8 编码示例:
- 字符 'A' (U+0041): 0x41 →
01000001(1 字节) - 字符 '中' (U+4E2D): 0x4E2D →
11100100 10111010 10101101(3 字节) - 字符 '𐍈' (U+10348): 0x10348 →
11110000 10010000 10001101 10001000(4 字节)
- 字符 'A' (U+0041): 0x41 →
-
UTF-16 编码示例:
- 字符 'A' (U+0041):
00000000 01000001(2 字节) - 字符 '中' (U+4E2D):
01001110 00101101(2 字节) - 字符 '𐍈' (U+10348):
11011000 00000011 11011100 00101000(4 字节,代理对)
- 字符 'A' (U+0041):
通过以上的对比,可以清楚地看到 UTF-8 和 UTF-16 在编码方式、存储效率和适用场景上的差异。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









