







自定义scheduler plugin扩展开发
有两种方式可以实现自定义调度
- default scheduler recording:配置修改,直接在k8s默认scheduler配置基础上进行添加,然后重新编译kube-scheduler
- scheduler framework:插件实现,源码层面实现plugin,重新编译kube-scheduler
配置修改
创建一个policy.cfg文件,内容为:
{"kind":"Policy","apiVersion":"v1","priorities":[{"name":"LeastRequestedPriority","weight":100}]}
修改集群配置中的自定义服务参数中的scheduler参数:
services:
scheduler:
extra_args:
policy-config-file: /policy.cfg
scheduler会读取根目录中的cfg文件
所以需要把创建的该文件拷贝到scheduler组件中:
docker cp policy.cfg kube-scheduler:/policy.cfg && docker start kube-scheduler
kube-scheduler即为scheduler运行的container ID
可以进入scheduler容器查看cfg文件是否已成功拷贝:
docker exec -it kube-scheduler bash
实际效果
LeastRequestedPriority优选调度算法会计算pod所需cpu和内存在当前节点可用资源的百分比
百分比越小,说明节点资源越充足,更容易得分,pod更倾向向改节点调度
修改配置之前,节点资源使用情况如下:
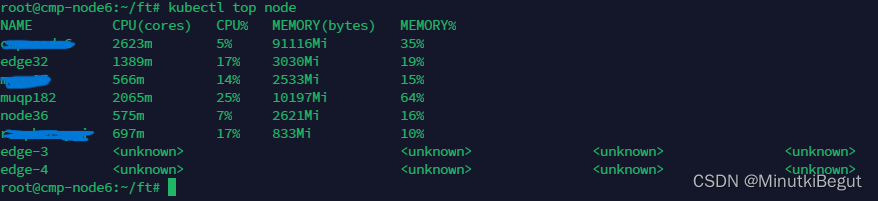
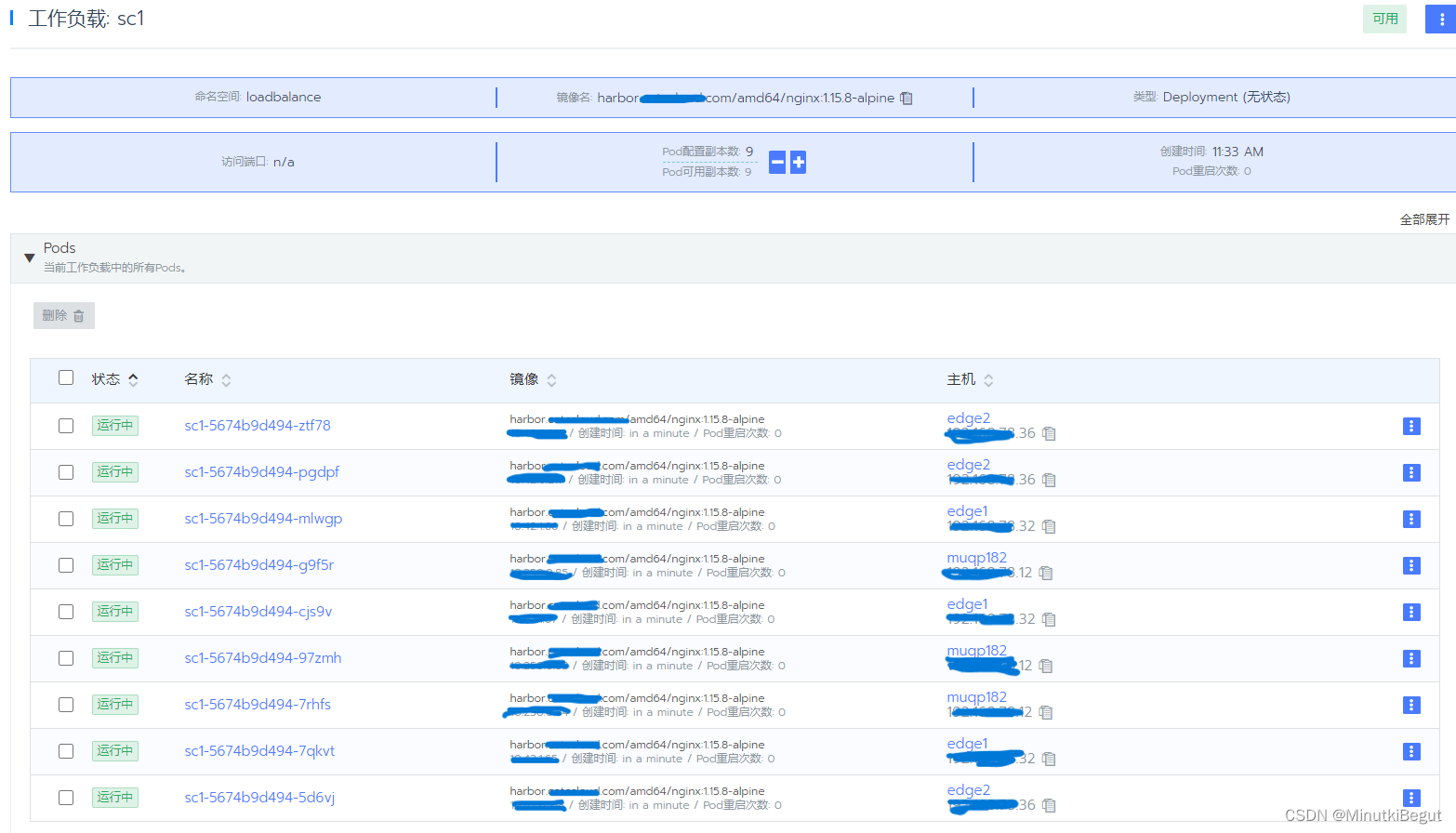
默认调度策略是轮询调度,副本数为9,每个节点分配三个pod
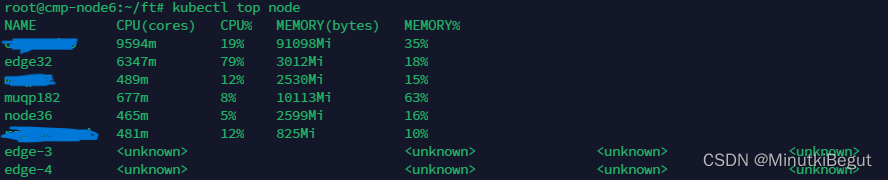
使用stress工具给32节点加压,cpu使用量增加,并修改配置(配置LeastRequestedPriority算法)
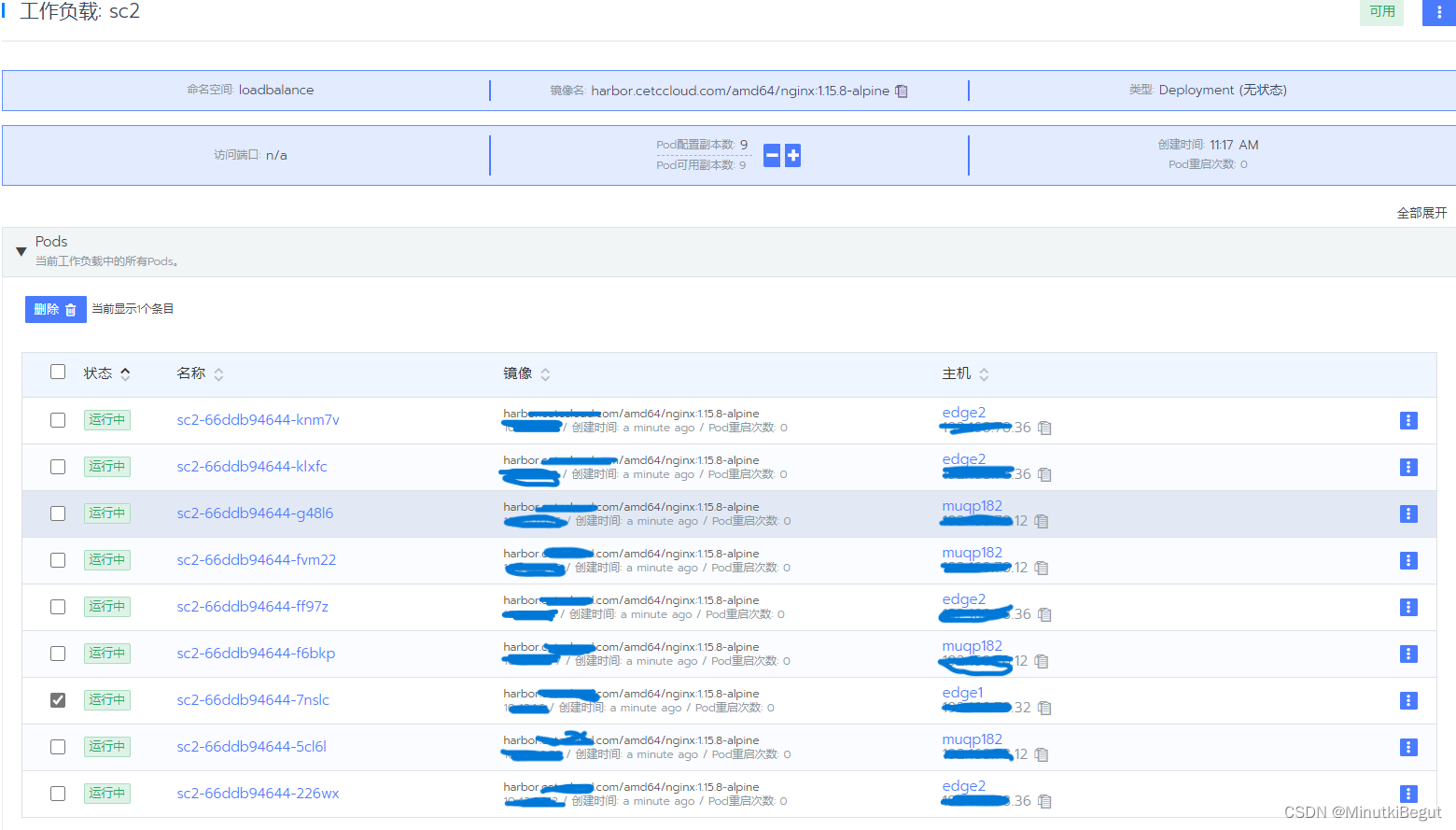
调度至32节点的pod减少
插件实现
pod调度流程以及对应的scheduler plugins扩展点如下,可以看出scheduler整个调度流程可以分为如下两个阶段:
- scheduling cycle:选择出一个节点以供pod运行,主要包括预选&优选,串行执行(一个pod调度完成后才调度下一个)
- binding cycle:将scheduling cycle选择的node与pod进行绑定,主要包括bind操作,并发执行(并发执行不同pod的绑定操作)
这里按照调用顺序依次介绍各个plugin扩展点:
- Queue sort:用于对scheduelr优先级队列进行排序,需要实现"less(pod1, pod2)"接口,且该插件只会生效一个
- Pre-filter:用于检查集群和pod需要满足的条件,或者对pod进行预选 预处理,需要实现"PreFilter"接口
- Filter:对应scheduler预选算法,用于根据预选策略对节点进行过滤
- Pre-Score:对应"Pre-filter",主要用于优选 预处理,比如:更新cache,产生logs/metrics等
- Scoring:对应scheduler优选算法,分为"score"(Map)和"normalize scoring"(Reduce)两个阶段
- score:并发执行node打分;同一个node在打分的时候,顺序执行插件对该node进行score
- normalize scoring:并发执行所有插件的normalize scoring;每个插件对所有节点score进行reduce,最终将分数限制在[MinNodeScore, MaxNodeScore]有效范围
- Reserve(aka Assume):scheduling cycle的最后一步,用于将node相关资源预留(assume)给pod,更新scheduler cache;若binding cycle执行失败,则会执行对应的Un-reserve插件,清理掉与pod相关的assume资源,并进入scheduling queue等待重新调度
- Permit:binding cycle的第一个步骤,判断是否允许pod与node执行bind,有如下三种行为:
- approve:允许,进入Pre-bind流程
- deny:不允许,执行Un-reserve插件,并进入scheduling queue等待重新调度
- wait (with a timeout):pod将一直持续处于Permit阶段,直到approve,进入Pre-bind;如果超时,则会被deny,等待重新被调度
- Pre-bind:执行bind操作之前的准备工作,例如volume相关的操作
- Bind:用于执行pod与node之间的绑定操作,只有在所有pre-bind plugins相关操作都完成的情况下才会被执行;另外,如果一个bind插件选择处理pod,那么其它bind插件都会被忽略
- Post-bind:binding cycle最后一个步骤,用于在bind操作执行成功后清理相关资源
开发过程
要实现一个调度器插件必须满足两个条件:
必须实现对应扩展点插件接口
将此插件在调度框架中进行注册。
每个扩展点的插件都必须要实现其相应的接口,所有的接口定义在
https://github.com/kubernetes/kubernetes/pkg/scheduler/framework/interface.go















 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









