






从时间节点来看,Stable Diffusion依然是小众产品。
用具体的数字来衡量,假如国内ChatGPT的用户有1亿人,那么Midjourney的用户大约是GPT的十分之一,千万级的规模;而SD又是MJ的十分之一左右,也就是百万级。
而事实上,SD之所以最有可能成为新一代生产力工具,正是因为它有更强的可控性,即便Midjourney也难以望其项背。
而我要做的事,就是毫无保留的与各位分享实际案例和方法,希望有更多人看到SD的生产能力,进而有兴趣学习和使用。
这篇文章不会告诉你如何绘制更好看的小姐姐,相反,你可以从中学到一种新技能:即便足不出户,也能用Stable Diffusion绘制精美的电商产品图。
具体而言,你会看到这样的过程:
一个随手拍摄的咖啡杯

如何变成这样

这样

或者是这样

制作全流程都在这篇文章里,跟着做,你也能学会。
在开始之前,我们先捋一捋制作思路:
从一张真实产品图开始——分割背景和产品——替换背景——调整尺寸和文字
拍摄真实产品图
别看一些MJ教程中用提示词出产品图,绕不开的问题是随机性太大。如果你的商品已经是实物,毫无疑问,必然货要对板。
首先你要拍摄若干张实物图,拍摄设备并不需要太高要求,手机相机都可以,唯一的要求是光线充足,细节清晰,就像下面这样:

虽然照片中放置商品的盒子沾满猫毛,但这并不重要,它提供了一个简单有效的参照物,在后面的制作流程中能极大地减少我们的修正工作量。
照片的处理工作还没结束,手机拍摄的照片分辨率超过3K,这样的分辨率在Stable
Diffusion中处理难度太大,电商平台的商品详情页并不需要如此高的分辨率,所以我们要预先调整照片尺寸。

以手机拍摄的3024x4032为例。如果你的设备显存高于16G,那么你可以缩减一半,改成1512x2016;如果你的设备显存低于16G,我建议你一步到位缩小3-4倍,改成1008x1344或者756x1008,先出图,再扩精度。
万物皆可SAM
如果你看过我之前写的文章,就不难理解我对Segment Anything有多推崇。技术进步带来的直观变化,就应当是任何人都可以学会的效率工具。

左键选择要保留的图形,右键选择不需要的图形,然后点击预览,前后不过一分钟的时间,蒙板就已经做好了。

这一步工作还没完,为什么现在市面上一些基于SD制作的电商图工具出图效果并不理想,正是因为它们忽略的商品的相对关系。如果做出来的商品图让人看着一眼假,谁又会相信产品详情页的描述货真价实呢?
接下来这一段是重点:
原图导入controlnet,选择预处理器softedge_hed得到预览图

下载预览图,然后修改成下面这个样子:

这样,你就得到了一个主要产品和次要背景之间直接联系,这能为你后面的出图和修改节约大量的时间。
万事俱备,开始替换背景。
局部重绘
主模型推荐realisticVision或者majicmixRealistic
正向提示词,重点描述产品背景
(best quality),(masterpiece), (photorealistic:1.3),extreme detail, product
photo,raw photo, coffee_shop background, day time,warm light, no human,
反向提示词,常规的反向embedding
bad-picture-chill-75v BadDream badhandv4 EasyNegative FastNegativeV2
ng_deepnegative_v1_75t UnrealisticDream,(coffee cup:1.5),
参数设置如下图

重绘幅度可以多尝试几次,有时降低幅度反而会有更好的出图效果。

Controlnet设置平平无奇,没什么特别需要调整的地方。

直接出图:

实测1363x1817分辨率直出,显存峰值占用21.6GB,建议低于24G显存的用户出图分辨率不要超过1K。

跑出一张图之后,你就可以多抽几次背景,或者继续修改提示词尝试,再或者按照之前介绍的扩图方法延展画面,最后加上必要的文字,一系列咖啡杯广告图就做好了。不清楚的地方可以回看前几期文章,这里就不再累述。
有些时候我们不止要有产品,还需要个代言人,最好还是能指定性别、年龄、肤色的代言人,怎么办?
好办!如果你看过画手的那篇文章就不难理解:你需要的并不是一个代言人,而是一张拿着产品的人像照片。
流程如下:
拍摄真人产品图
叫上你的同事或者亲朋好友,性别年龄都不重要,重要的是摆出pose

再一次,万物皆可SAM

别忘了手部特写,值得单独做个softedge_hed

万事俱备,开始重绘
主模型推荐realisticVision和photon(欧美面孔)或者majicmixRealistic(亚洲面孔)
正向提示词:
Best quality,masterpiece,ultra high res,raw photo,deep shadow,dark
theme,(photorealistic:1.4),(1man,smiling),(fashion clothes:1.2),inspired by
brutalist architecture,vibrant color palette,undertones,hart hand, (london
street),(standing in front of starbucks coffee shop:1.3),(sfw:1.1),good
fingers,good logo,(starbucks logo:1.3)
反向提示词:
bad-picture-
chill-75v,BadDream,badhandv4,EasyNegative,ng_deepnegative_v1_75t,exposed,
(nsfw:1.1), many fingers, many hands, (nsfw:1.1)(tatoo)
设置参数跟上面的案例差不多,区别在于controlnet是这样的:

如果你不放心身体姿态,多加一个openpose也未尝不可:

直接出图:


还是那句话,只要你成功做出了一张图,你就已经做出了无数张图 。重复这个工作流,你可以制作出任意姿势的真人产品图,一次性生成十几张,慢慢挑就行了。
既然你已经看到了这里,我建议你也动手试一试。创作的快乐,真的难以想象。
目前 ControlNet 已经更新到 1.1 版本,相较于 1.0 版本,ControlNet1.1 新增了更多的预处理器和模型,每种模型对应不同的采集方式,再对应不同的应用场景,每种应用场景又有不同的变现空间
我花了一周时间彻底把ControlNet1.1的14种模型研究了一遍,跑了一次全流程,终于将它完整下载好整理成网盘资源。
其总共11 个生产就绪模型、2 个实验模型和 1 个未完成模型,现在就分享给大家,点击下方卡片免费领取。
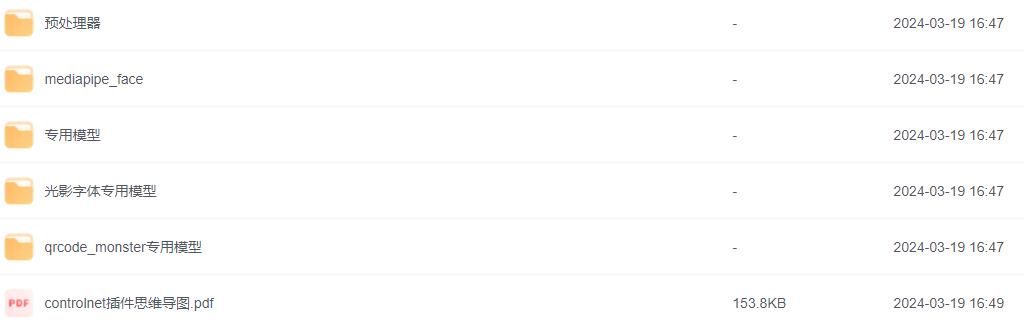
1. 线稿上色
**方法:**通过 ControlNet 边缘检测模型或线稿模型提取线稿(可提取参考图片线稿,或者手绘线稿),再根据提示词和风格模型对图像进行着色和风格化。
**应用模型:**Canny、SoftEdge、Lineart。
Canny 示例:(保留结构,再进行着色和风格化)
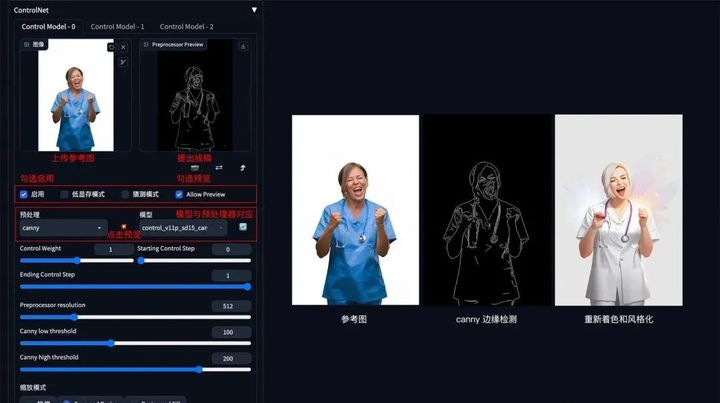
2. 涂鸦成图
方法:通过 ControlNet 的 Scribble 模型提取涂鸦图(可提取参考图涂鸦,或者手绘涂鸦图),再根据提示词和风格模型对图像进行着色和风格化。
应用模型:Scribble。
Scribble 比 Canny、SoftEdge 和 Lineart 的自由发挥度要更高,也可以用于对手绘稿进行着色和风格处理。Scribble 的预处理器有三种模式:Scribble_hed,Scribble_pidinet,Scribble_Xdog,对比如下,可以看到 Scribble_Xdog 的处理细节更为丰富:

Scribble 参考图提取示例(保留大致结构,再进行着色和风格化):
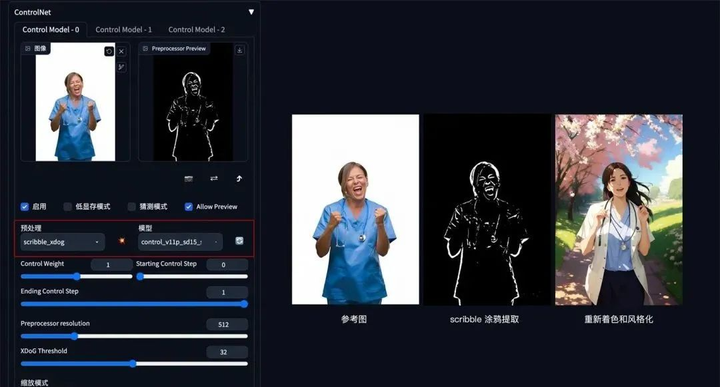
3. 建筑/室内设计
**方法:**通过 ControlNet 的 MLSD 模型提取建筑的线条结构和几何形状,构建出建筑线框(可提取参考图线条,或者手绘线条),再配合提示词和建筑/室内设计风格模型来生成图像。
**应用模型:**MLSD。
MLSD 示例:(毛坯变精装)
这份完整版的ControlNet 1.1模型我已经打包好,需要的点击下方插件,即可前往免费领取!
4. 颜色控制画面
**方法:**通过 ControlNet 的 Segmentation 语义分割模型,标注画面中的不同区块颜色和结构(不同颜色代表不同类型对象),从而控制画面的构图和内容。
**应用模型:**Seg。
Seg 示例:(提取参考图内容和结构,再进行着色和风格化)
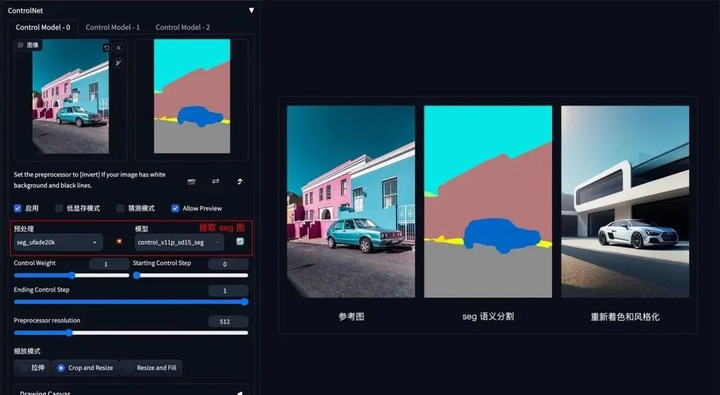
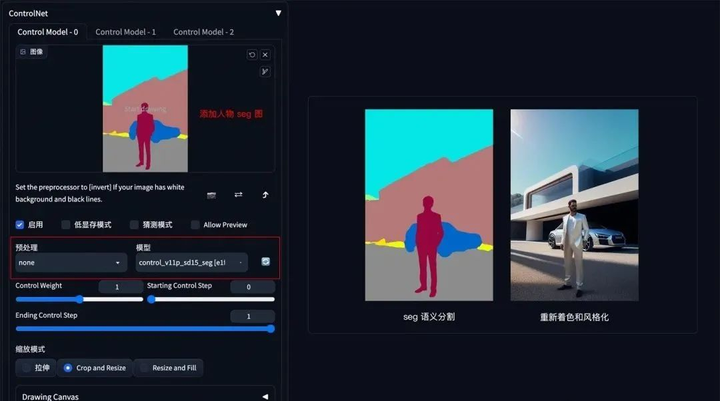
如果还想在车前面加一个人,只需在 Seg 预处理图上对应人物色值,添加人物色块再生成图像即可。
5. 背景替换
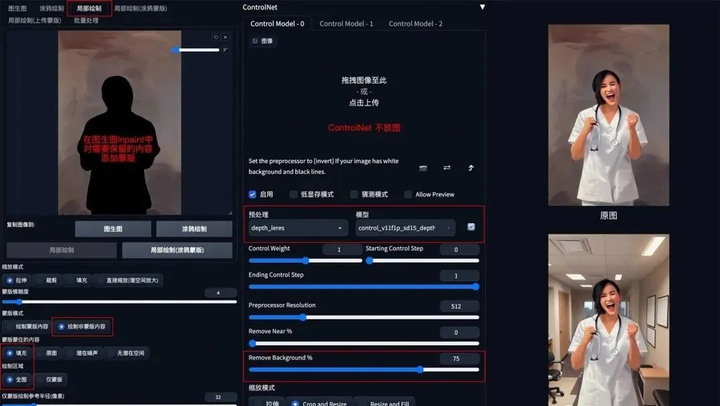
**方法:**在 img2img 图生图模式中,通过 ControlNet 的 Depth_leres 模型中的 remove background 功能移除背景,再通过提示词更换想要的背景。
**应用模型:**Depth,预处理器 Depth_leres。
**要点:**如果想要比较完美的替换背景,可以在图生图的 Inpaint 模式中,对需要保留的图片内容添加蒙版,remove background 值可以设置在 70-80%。
Depth_leres 示例:(将原图背景替换为办公室背景)
6. 图片指令
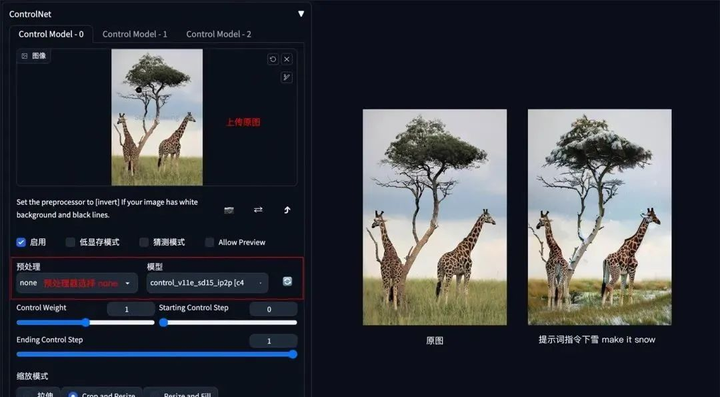
**方法:**通过 ControlNet 的 Pix2Pix 模型(ip2p),可以对图片进行指令式变换。
应用模型:ip2p,预处理器选择 none。
**要点:**采用指令式提示词(make Y into X),如下图示例中的 make it snow,让非洲草原下雪。
Pix2Pix 示例:(让非洲草原下雪)
7. 风格迁移
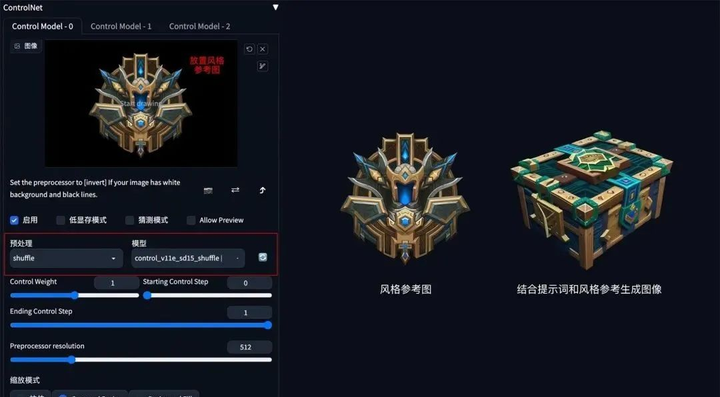
**方法:**通过 ControlNet 的 Shuffle 模型提取出参考图的风格,再配合提示词将风格迁移到生成图上。
**应用模型:**Shuffle。
Shuffle 示例:(根据魔兽道具风格,重新生成一个宝箱道具)
8. 色彩继承
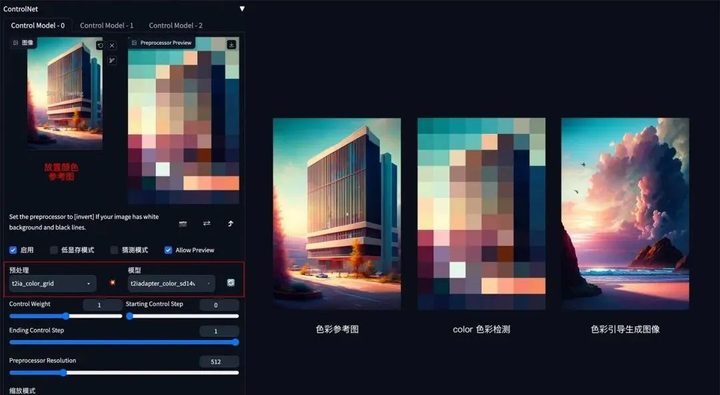
**方法:**通过 ControlNet 的 t2iaColor 模型提取出参考图的色彩分布情况,再配合提示词和风格模型将色彩应用到生成图上。
**应用模型:**Color。
Color 示例:(把参考图色彩分布应用到生成图上)
这份完整版的ControlNet 1.1模型我已经打包好,需要的点击下方插件,即可前往免费领取!
这里就简单说几种应用:
1. 人物和背景分别控制
2. 三维重建
3. 更精准的图片风格化
4. 更精准的图片局部重绘
以上就是本教程的全部内容了,重点介绍了controlnet模型功能实用,当然还有一些小众的模型在本次教程中没有出现,目前controlnet模型确实还挺多的,所以重点放在了官方发布的几个模型上。
同时大家可能都想学习AI绘画技术,也想通过这项技能真正赚到钱,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学,因为自身做副业需要,我这边整理了全套的Stable Diffusion入门知识点资料,大家有需要可以直接点击下边卡片获取,希望能够真正帮助到大家。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









