






一张图片 做LORA模型 动漫 像素风 迪士尼形象一网打尽




平时我们拍照很少
但又想用自己形象让AI美化后出图发朋友的
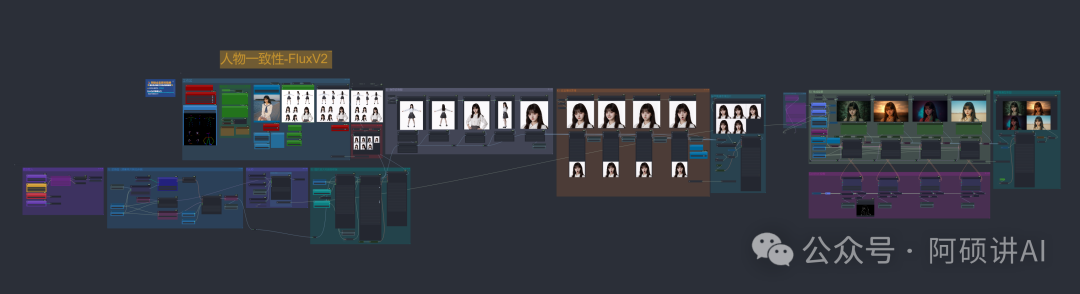
用这个工作流就对了 FLUX人物一致性的V2版本
载入一张图片 通过pulid默认脸部 openpose来固定姿势 形成多视图
再提取脸部 做多样化的表情 以这些表情作为驱动 来添加背景
最终我们就能从一张图得到N张一致性非常强的图片 从而拿去fluxgym训练LORA模型
最终得到的LORA模型 我们就可以随意出图啦~
下面讲全流程用法
总共5个主要板块 先把第一步的姿势图生成打开
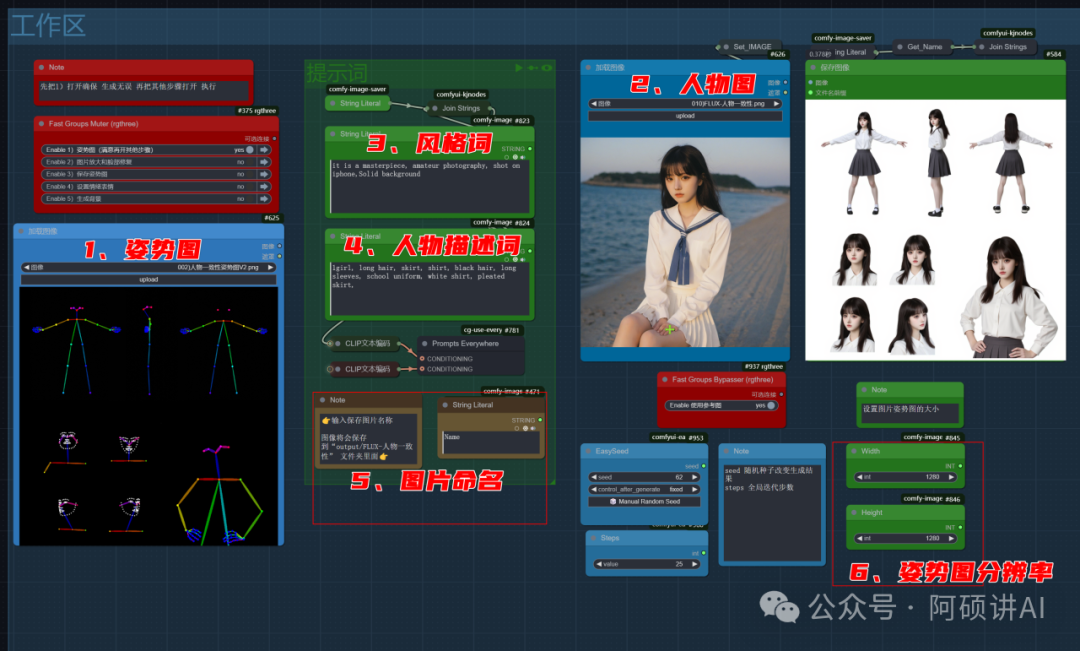
- 载入 我准备好的姿势图
- 载入 你的形象图
- 写一些风格词的 例如:漫画风格、像素风、皮克斯风格等 (需要配合相应的lora来达到最好的效果)
- 对你的形象进行描述 描述你的形象就行了 像是衣服 头发发色之类 其他都不需要
- 保存图片的名字 他会保存到 output/FLUX-人物一致性文件夹里面
- 调整出图的宽高 跑起来压力大 就调低 例如调成1024乘1024
使用参考图去掉 的话
那么工作流就会根据模型和提示词随机生成人物
得到一张满意的图片后
就可以把剩下的步骤全打开了
接着的步骤就是把出来的这张图片给高清化 和脸部细化
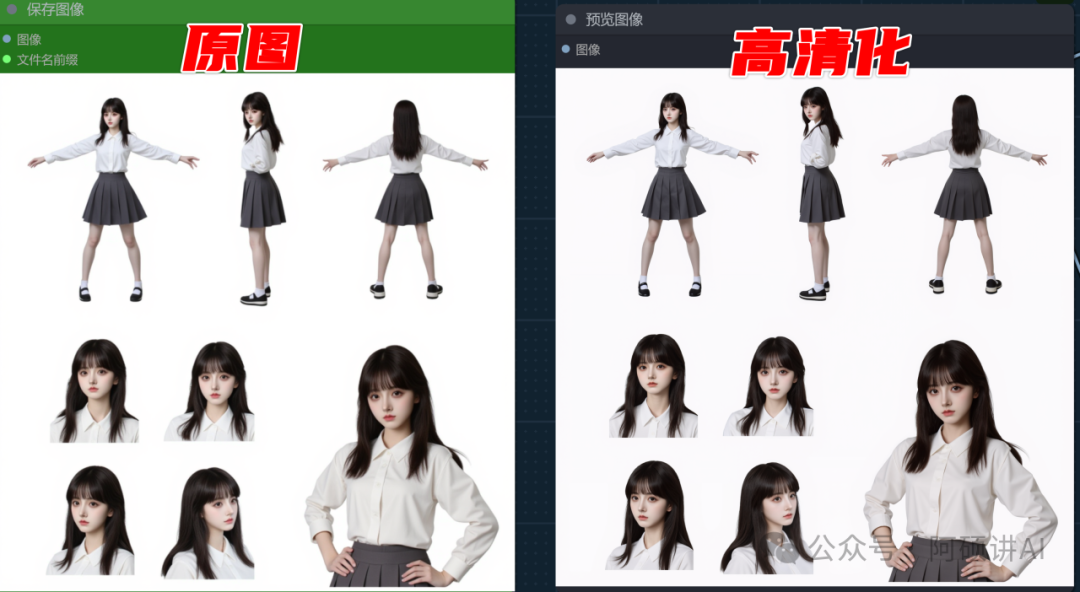
那么在这里你可以选择把这些图片保存下来
工作流会自动裁切脸部的图片的
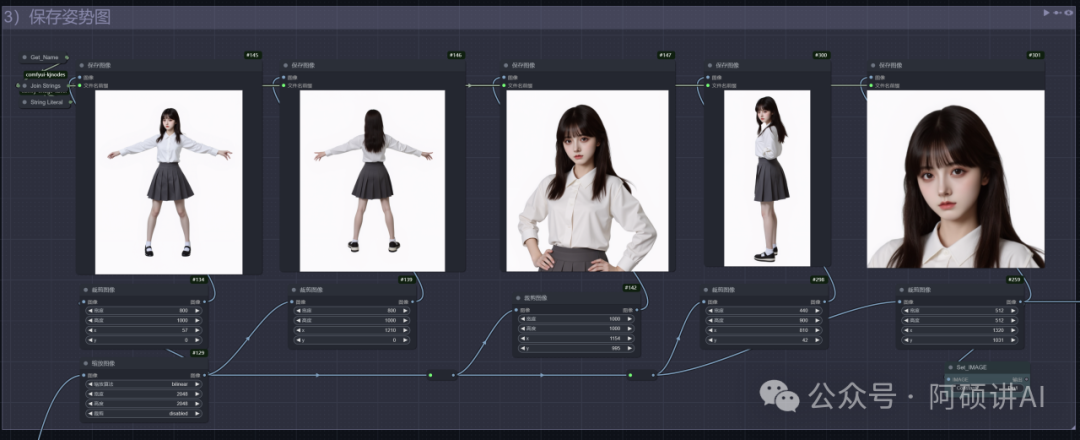
接着是多视图的裁切
把这些正脸侧脸都裁剪出来
下面可以调整裁切的大小和位置
如果你觉得位置不太对 就自行调整一下
接着会以最大的脸部这一张 为参考
用来操作脸部表情
都是一一对应的
在下面随意调 就可以了 这里的5个表情 分别是EM1到EM5
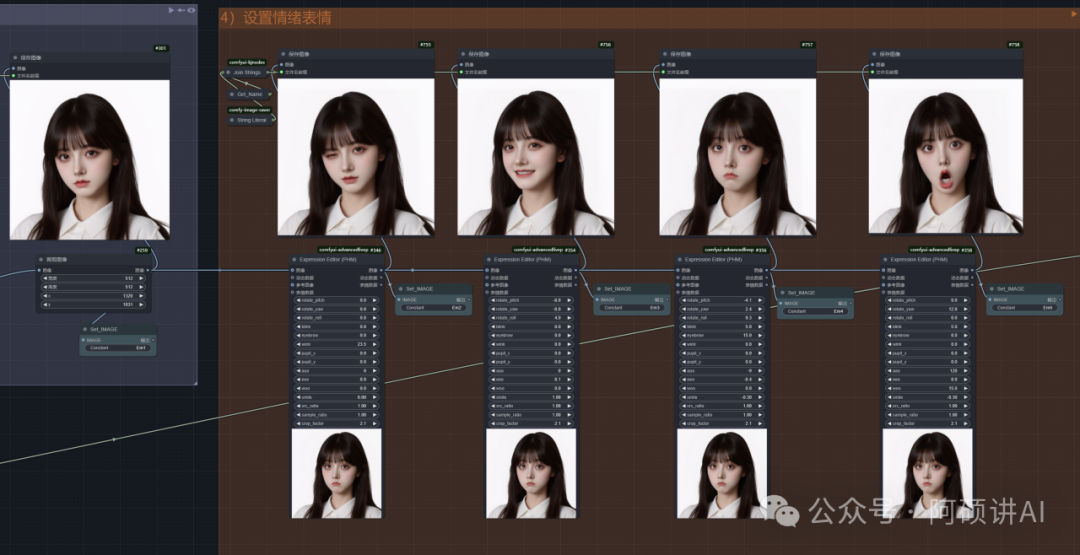
这个板块就是以
刚才的表情动作作为输入来生成背景
这里提示词 只需要输入你想要的场景词就可以了
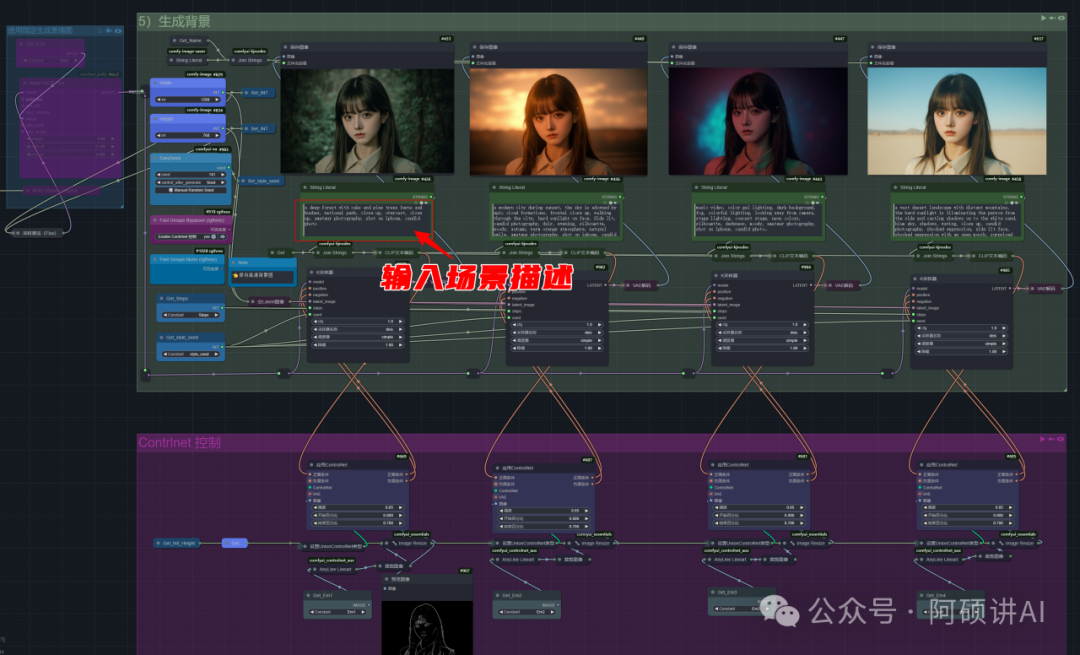
如果你不想要表情控制也可以把它给关掉
这样就可以让AI随意发挥了
甚至让他跳舞也是没有问题的
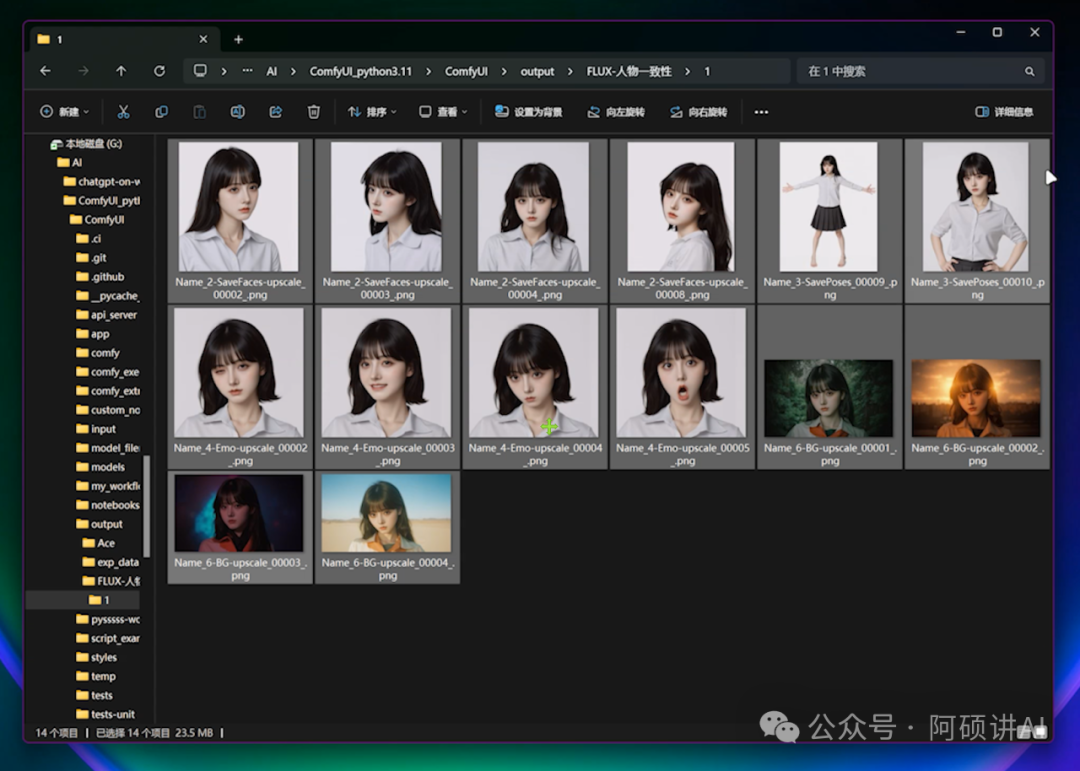
那么最后我们就让从1张图片变成10几张图片
这就足够我们去训练模型了
之后训练模型用的是fluxgym
这是flux训练lora的可视化工具 主打简单粗暴
我也准备了本地的整合包 和云端的部署
本地版就是 把他解压到一个没有中文的目录下
双击 一键启动 就可以打开
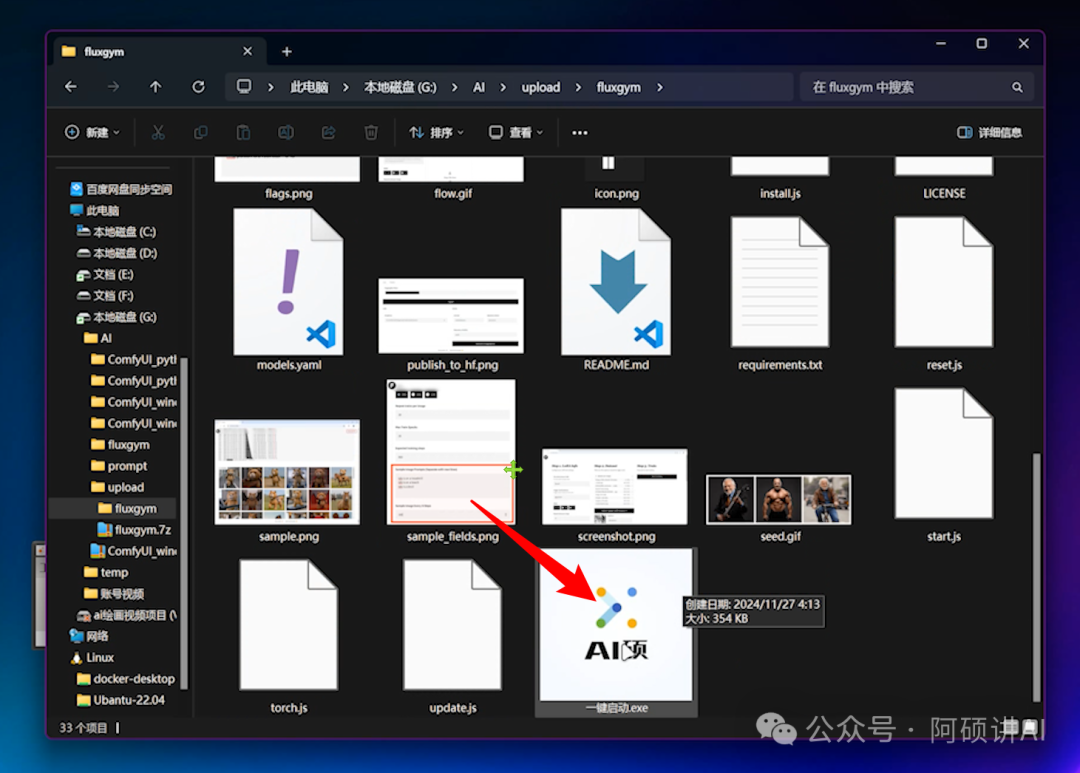
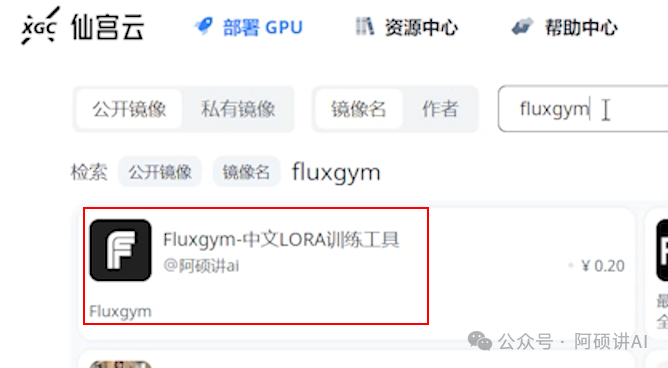
而云端 在仙宫云搜索fluxgym
阿硕的这一个
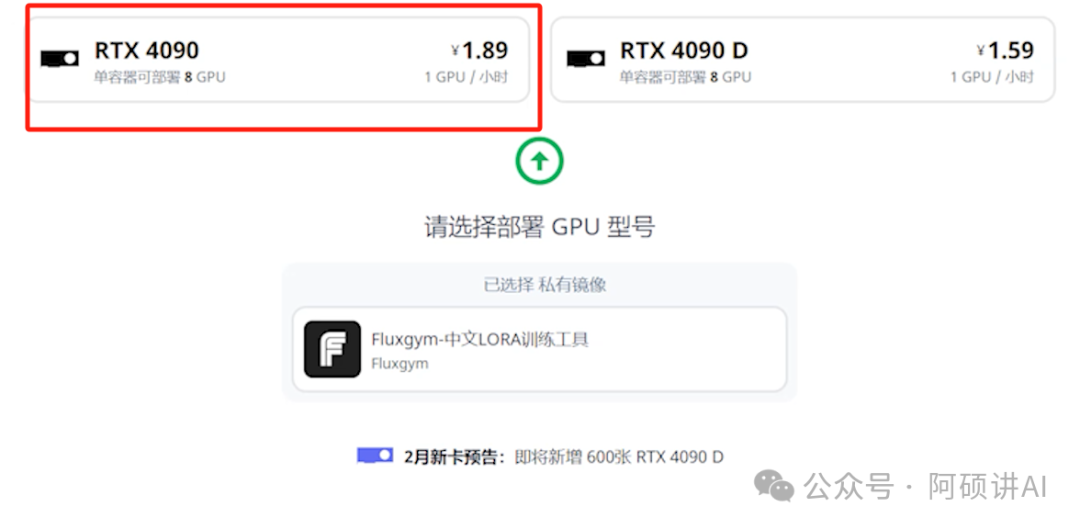
用4090部署 4090D也可以 速度应该差不了太多的
开机后点 仙宫云os进入界面
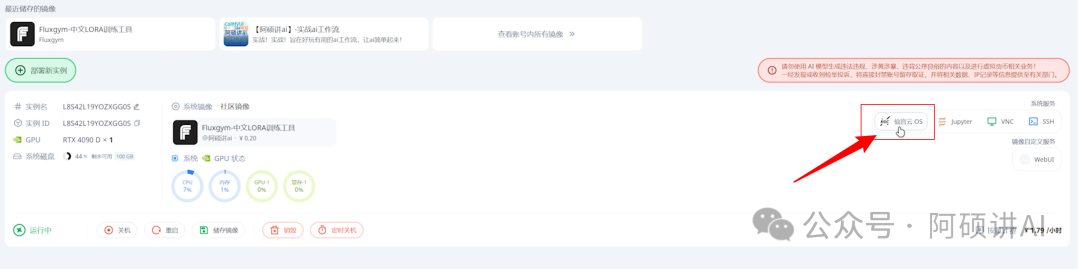
双击 fluxgym界面启动
把我们刚才生成的图片拉进中间
如果你之前出的图比较多
就尽量挑选一下 选多点不同样动作表情
不同样的光照环境的
15张左右就可以了 多一点也无所谓
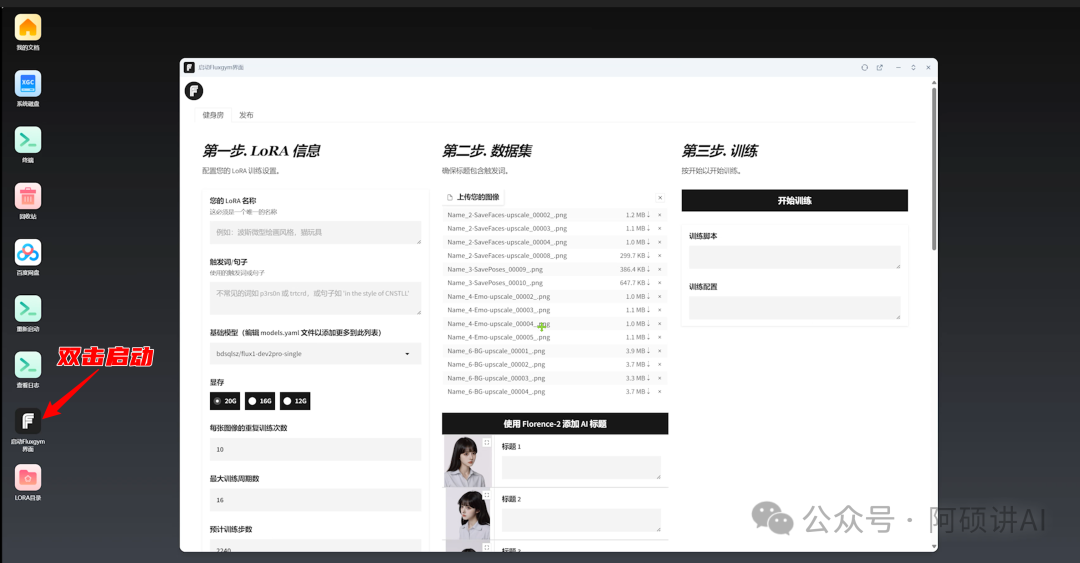
输入我们的lora模型的名字 就是文件名字 随意就行
触发词 就是输入这个词就能召唤你的人物出来
这个词不能和模型已经有的词冲突
需要独一无二 例如 ashuo_ai
往后我们要激活它 只需要输入触发词即可
显存根据你显存大小来选择 最少也需要12G才能启动
每张训练重复数和 训练轮次 和图片数量是相乘的关系
下面能自动计算出总训练步数的
现在我是14张图片 总训练大概2000~2500就够了
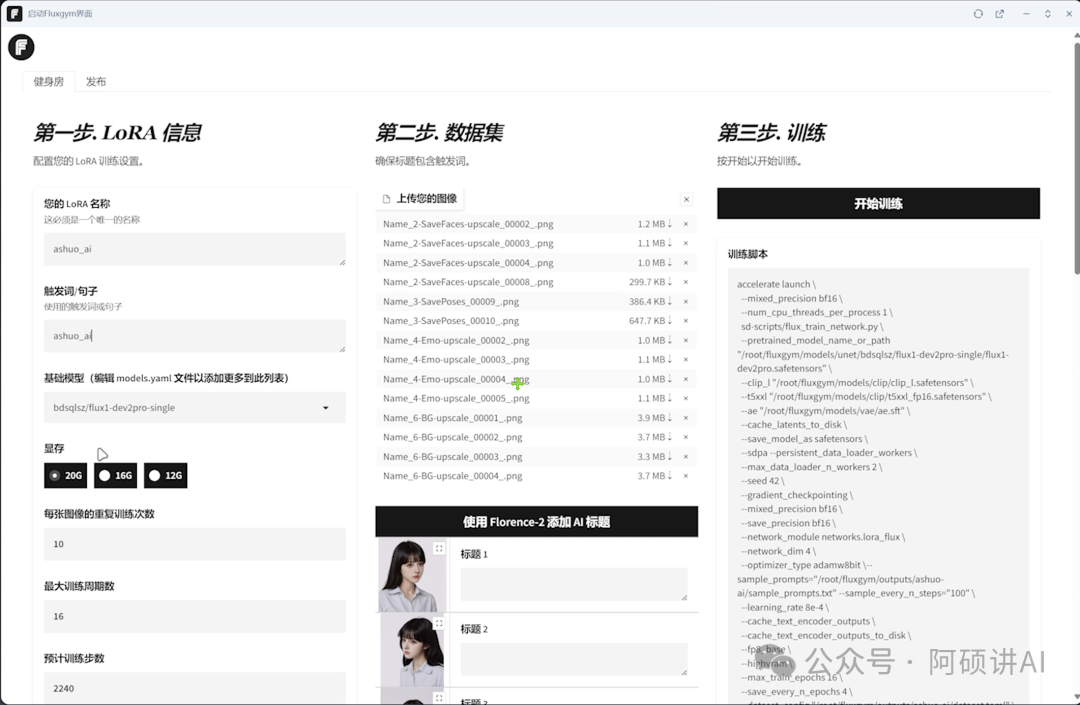
设置训练时生成示例图的提示词和多少步生成示例图像
加入我们的触发词ashuo_ai 接着写一句人物场景描述就行了
训练集的缩放
会把图像最小的一个边 缩放成你给的数值
用512其实就够了 768 或者1024效果肯定会更好
但训练时长就得翻倍了
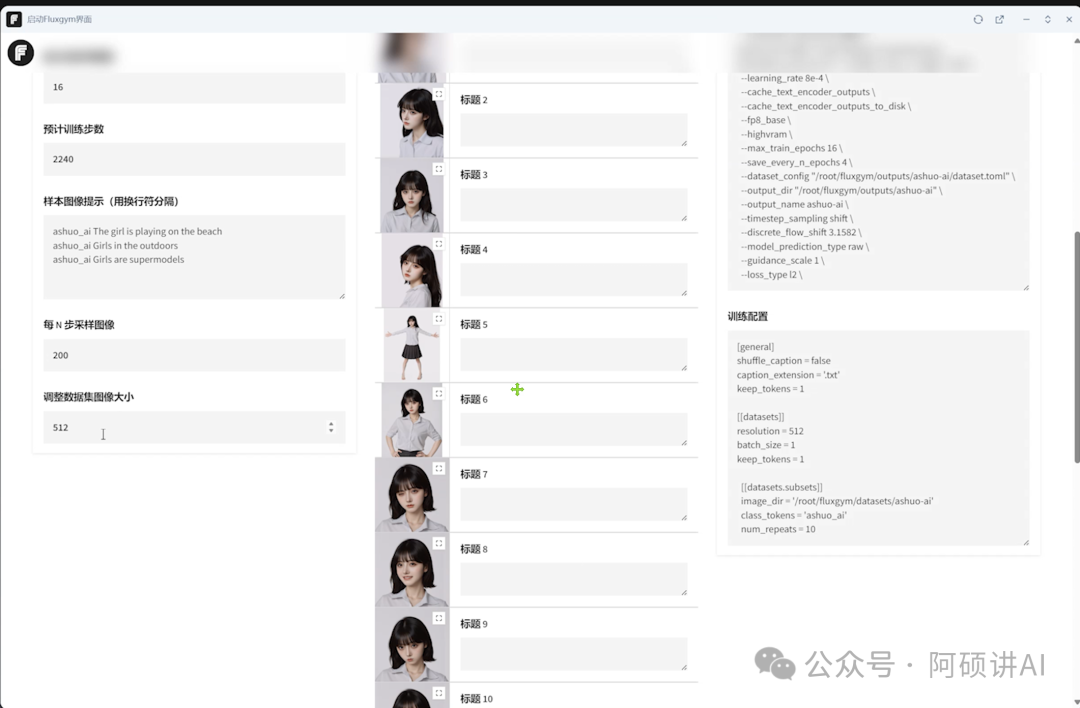
接着点Florence2反推提示词
差不多等个几十秒 图片的提示词就写上了
可以看到反推出来的每一句开头都会把我们触发词给加上
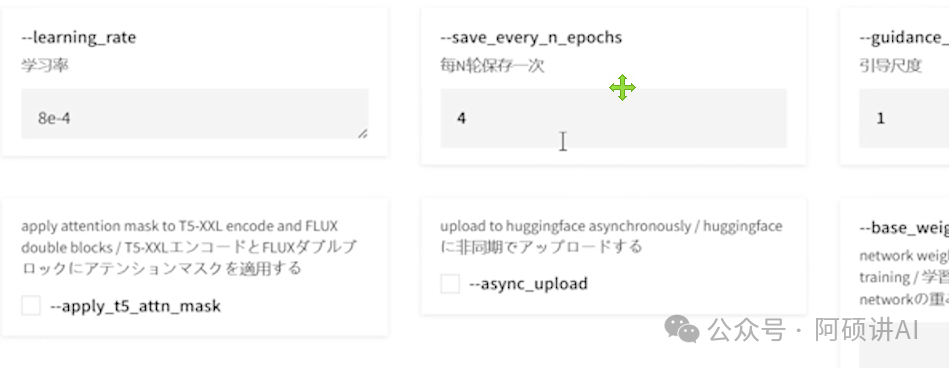
fluxgym也提供了高级选项 非常非常多的参数
可以更改多少轮保存一次文件
默认是4轮保存一次
接着就可以开始训练了
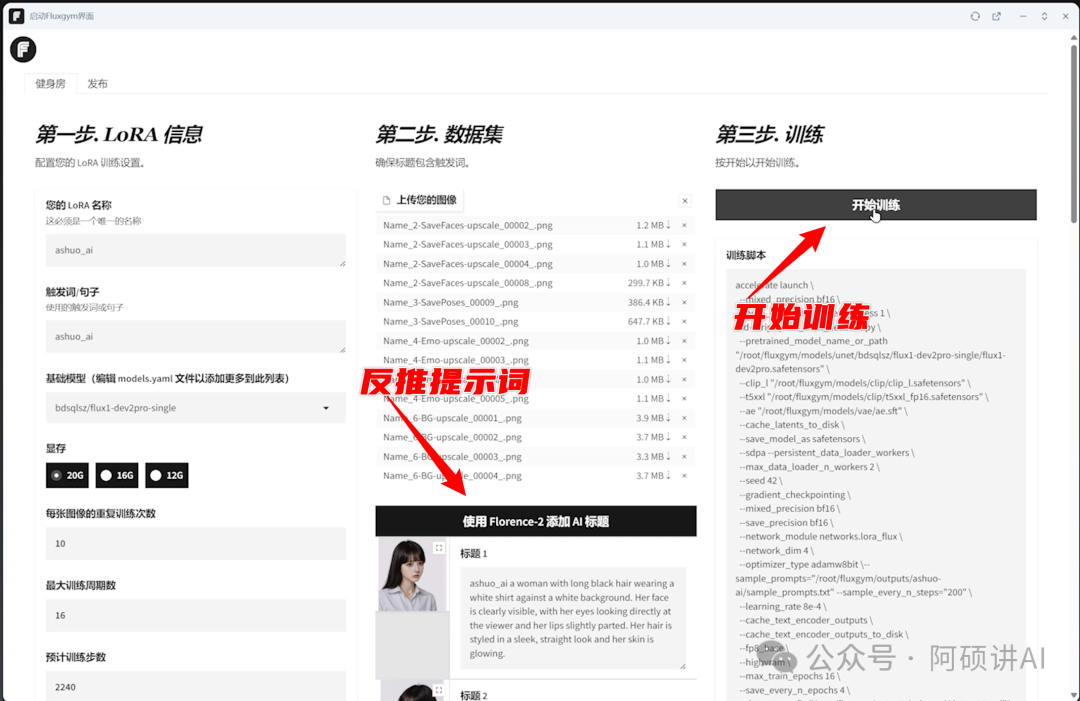
训练的时候 页面时锁定的
可以点右上角解锁
等到它出现进度条 就能看到 大概需要耗时多久
4090训练时长是 40分钟左右
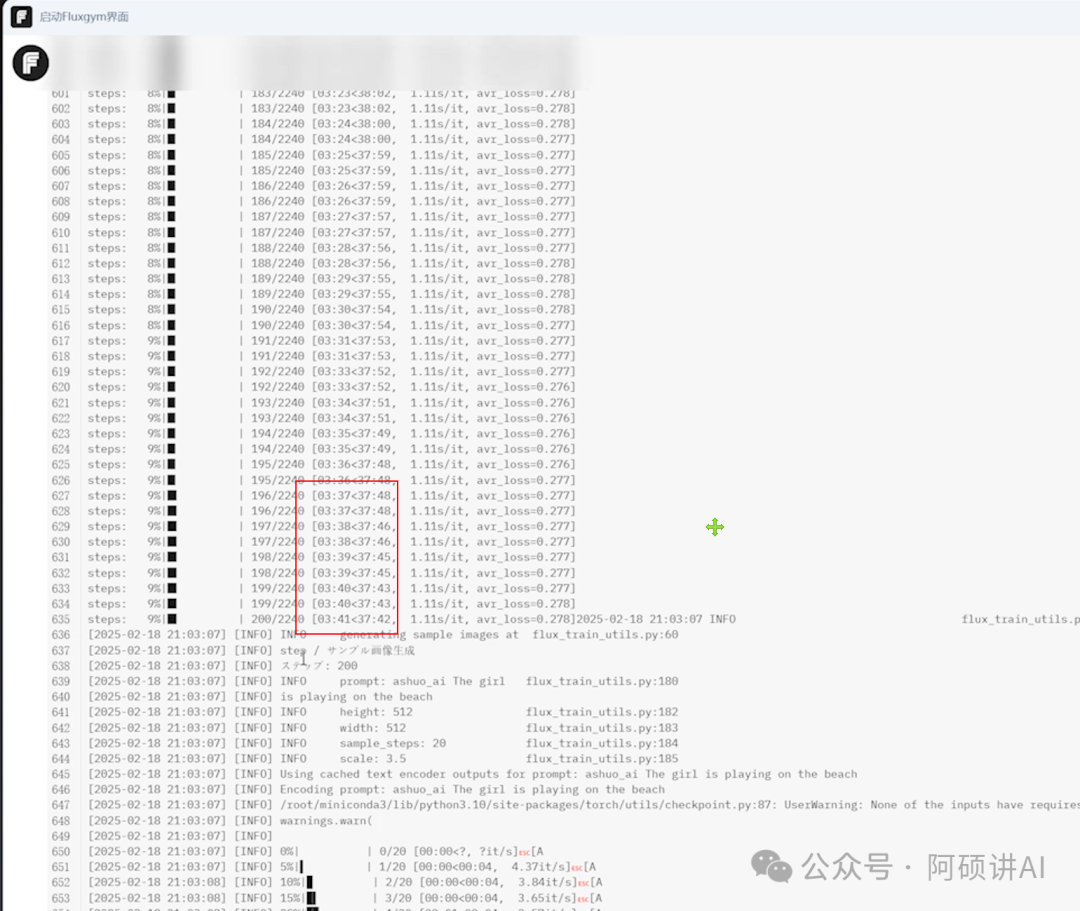
每训练够200步 它这里就会生成图片
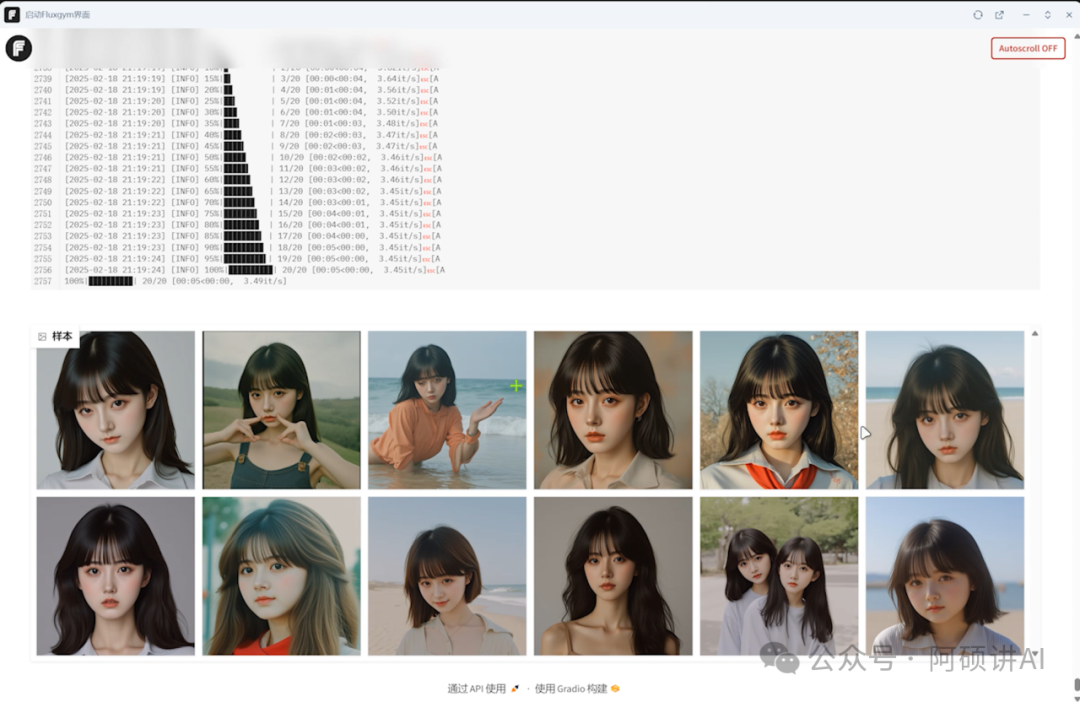
你也可以观察到 整个过程
每次出图都会像你得人物模样靠近
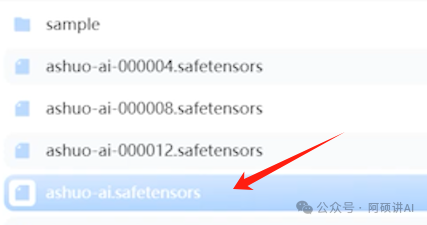
训练出来的模型 会保存到 output目录下
云端双击lora目录就可以打开

刚才我们设置最大训练轮数是16轮 每4轮保存一次 所以就得到04 08 12和16轮
没有数字模型是 完整跑完全部步数的
我们可以载入一个flux的工作流来测试一下
载入我们新训练好的LORA
在提示词前面加入触发词
我用gpt出了一些提示词 可以看一下出图效果
摆出各种各样姿势也完全没问题






为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









