







1.定义:索引是对数据表或视图中的一列或多列的值进行排序的一种结构(B树),可以加快检索速度。
2.作用:加快查找和排序的速度(原因:采用平衡树结构,避免了全表扫描)
3.缺点:①影响增删改的速度(需要重新梳理索引)②占用更多的磁盘空间
4.语法:4.1 创建索引:
CREATE [UNIQUE] [CLUSTERED| NONCLUSTERED ]
INDEX index_name ON { table | view } ( column [ ASC | DESC ] [ ,...n ] )
[with[PAD_INDEX][[,]FILLFACTOR=fillfactor]
CREATE INDEX命令创建索引各参数说明如下:
UNIQUE:用于指定为表或视图创建唯一索引,即不允许存在索引值相同的两行。
CLUSTERED:用于指定创建的索引为聚集索引。
NONCLUSTERED:用于指定创建的索引为非聚集索引。
index_name:用于指定所创建的索引的名称。
table:用于指定创建索引的表的名称。
view:用于指定创建索引的视图的名称。
ASC|DESC:用于指定具体某个索引列的升序或降序排序方向。
Column:用于指定被索引的列。
4.2 删除索引:DROP INDEX table_name.index_name[,table_name.index_name]
4.3 显示索引信息:
使用系统存储过程:sp_helpindex 查看指定表的索引信息。Exec sp_helpindex table_name;
5.分类:
聚集索引和非聚集索引(类似于汉语字典中的拼音查字法和部首查字法)
唯一索引和非唯一索引
单列索引和多列索引
6.索引的数据结构:b+tree(b树,平衡树 ,不是二叉树)
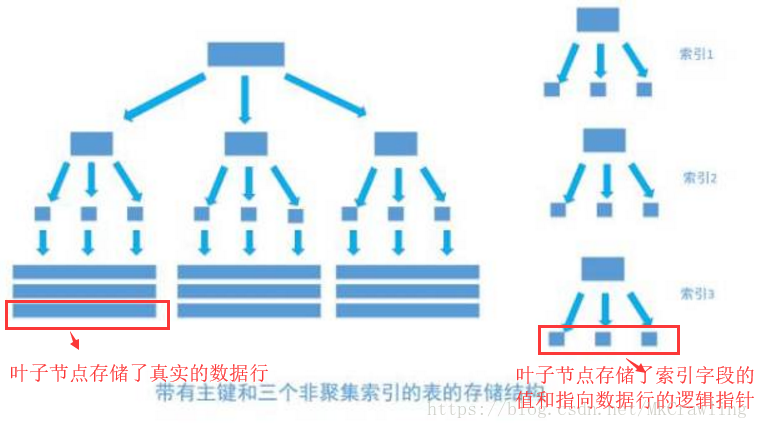
一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。如下图所示:

非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。 如下图














 3059
3059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









