







数据采集通道搭建之业务数据采集通道搭建
1.数据同步策略分析
1.1常见的数据同步策略
我们每天都需要从数据库中将业务数据同步到数据仓库当中,对于离线数仓来说,各项指标计算的周期一般为天,因此,我们数据同步的周期也为天。
数据的同步策略有全量同步和增量同步这两种。
对于全量同步而言,就是每天都将数据库当中的所有数据全部都同步一份到数据仓库当中,如下图所示:
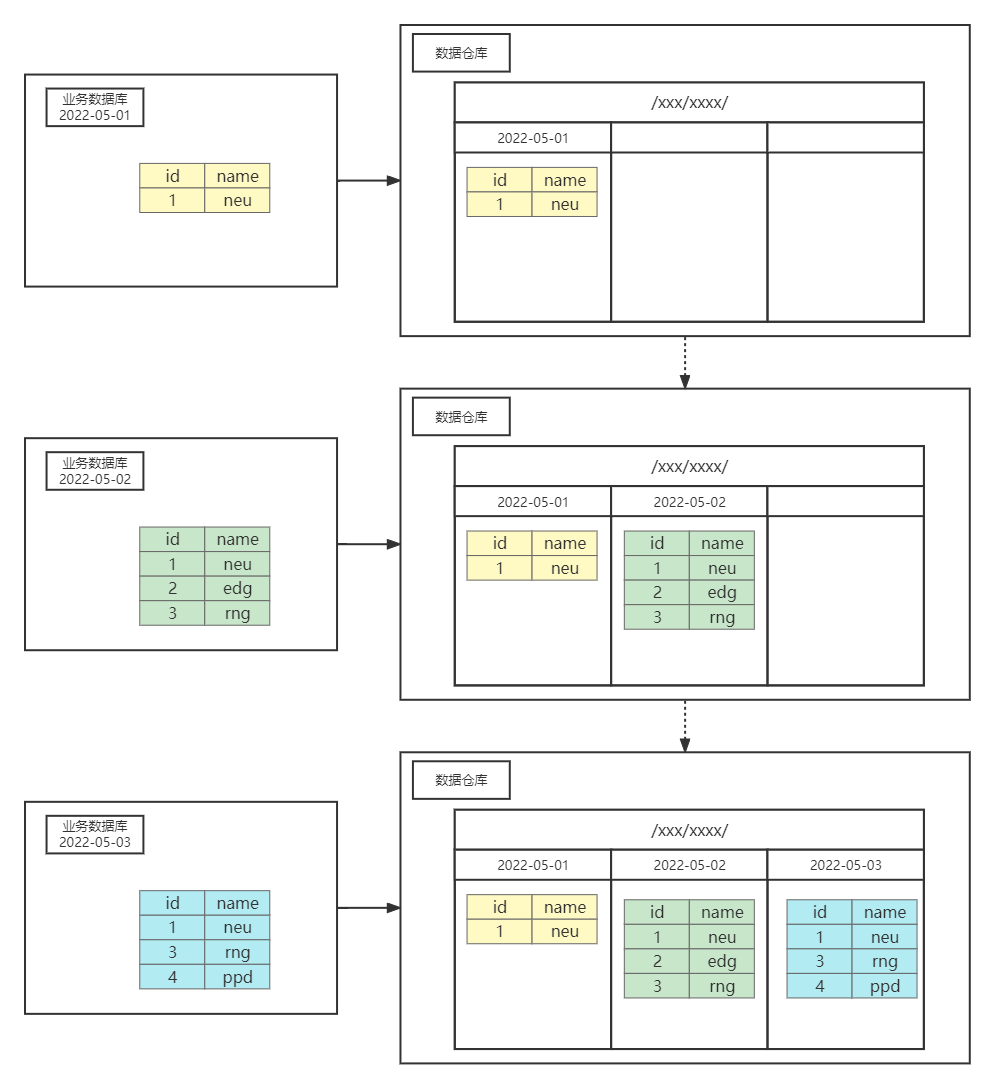
对于增量同步而言,就是将业务数据库当中每天新增及变化的数据同步到数据仓库之中。对于增量同步的表来说,数仓开始的第一天时需要先进行一次全量同步,之后每天进行的都是增量同步。增量同步示意图如下图所示:
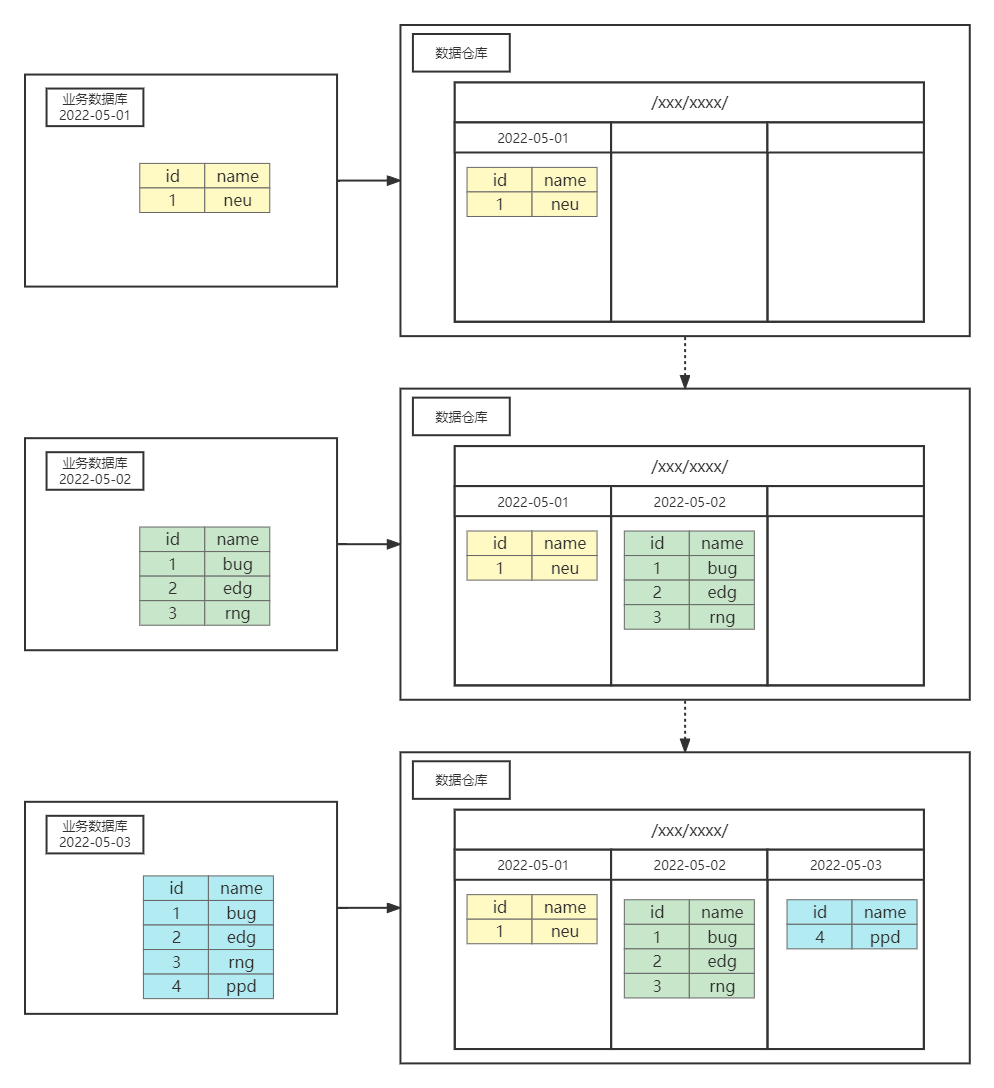
1.2数据同步策略的选择
对于该项目,我们在对不同的表选取同步策略之前,我们首先需要对两种同步策略进行对比:
| 同步策略 | 优点 | 缺点 |
|---|---|---|
| 全量同步 | 逻辑简单 | 在某些情况下效率较低。例如某张表数据量较大,但是每天数据的变化比例很低,若对其采用每日全量同步,则会重复同步和存储大量相同的数据。 |
| 增量同步 | 效率高,无需同步和存储重复数据 | 逻辑复杂,需要将每日的新增及变化数据同原来的数据进行整合,才能使用 |
因此,我们在选择同步策略时,如果当前业务数据表的数据量比较大,并且每天数据变化的概率比较低,那么我们就采用增量同步;如果当前业务数据表的数据量不大或者表中数据变化的概率比较大,那么我们就选取全量同步。
最终,我们考虑到以上因素,确定了各个业务表的同步策略,如下所示:

1.3数据同步工具的选择
数据同步工具种类繁多,大致可分为两类,一类是以DataX、Sqoop为代表的基于Select查询的离线、批量同步工具,另一类是以Maxwell、Canal为代表的基于数据库数据变更日志(例如MySQL的binlog,其会实时记录所有的insert、update以及delete操作)的实时流式同步工具。
全量同步,我们使用的是DataX这个基于查询的离线同步工具,而增量同步,我们可以使用DataX这类工具,也可以使用Maxwell这样的基于数据库数据变更日志的实时流式同步工具。
1.3.1增量同步方案的选择
| 增量同步方案 | Maxwell/Canal | DataX/Sqoop |
|---|---|---|
| 对数据库的要求 | 要求数据库记录变更操作,例如MySQL需开启binlog。 | 原理是基于查询,故若想通过select查询获取新增及变化数据,就要求数据表中存在create_time、update_time等字段,然后根据这些字段获取变更数据。 |
| 数据的中间状态 | 由于是实时获取所有的数据变更操作,所以可以获取变更数据的所有中间状态。 | 由于是离线批量同步,故若一条数据在一天中变化多次,该方案只能获取最后一个状态,中间状态无法获取。 |
由于在进行增量同步时,我们如果使用DataX,则不能获取一天中数据多次变化的状态,而Maxwell可以,因此我们增量同步采用Maxwell来进行数据的同步。
2.进行全量表数据同步
2.1全量表同步数据通道架构回顾
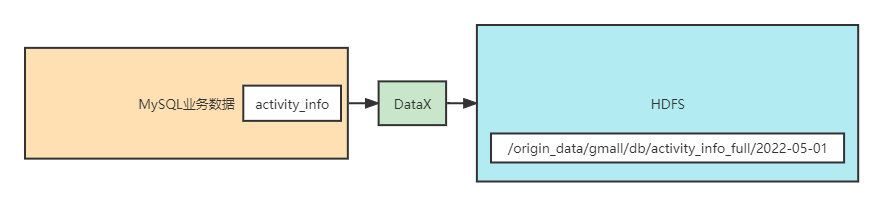
2.2DataX配置文件的编写
2.2.1 gmall.activity_info.json配置文件编写
{
"job":{
"content":[
{
"writer":{
"parameter":{
"writeMode":"append",
"fieldDelimiter":"\t",
"column":[
{
"type":"bigint",
"name":"id"
},
{
"type":"string",
"name":"activity_name"
},
{
"type":"string",
"name":"activity_type"
},
{
"type":"string",
"name":"activity_desc"
},
{
"type":"string",
"name":"start_time"
},
{
"type":"string",
"name":"end_time"
},
{
"type":"string",
"name":"create_time"
}
],
"path":"${targetdir}",
"fileType":"text",
"defaultFS":"hdfs://hadoop102:8020",
"compress":"gzip",
"fileName":"activity_info"
},
"name":"hdfswriter"
},
"reader":{
"parameter":{
"username":"root",
"column":[
"id",
"activity_name",
"activity_type",
"activity_desc",
"start_time",
"end_time",
"create_time"
],
"connection":[
{
"table":[
"activity_info"
],
"jdbcUrl":[
"jdbc:mysql://hadoop102:3306/gmall"
]
}
],
"password":"*******",
"splitPk":""
},
"name":"mysqlreader"
}
}
],
"setting":{
"speed":{
"channel":3
},
"errorLimit":{
"record":0,
"percentage":0.02
}
}
}
}
2.2.2 gmall.activity_rule.json配置文件编写
{
"job":{
"content":[
{
"writer":{
"parameter":{
"writeMode":"append",
"fieldDelimiter":"\t",
"column":[
{
"type":"bigint",
"name":"id"
},
{
"type":"bigint",
"name":"activity_id"
},
{
"type":"string",
"name":"activity_type"
},
{
"type":"string",
"name":"condition_amount"
},
{
"type":"bigint",
"name":"condition_num"
},
{
"type":"string",
"name":"benefit_amount"
},
{
"type":"string",
"name":"benefit_discount"
},
{
"type":"bigint",
"name":"benefit_level"
}
],
"path":"${targetdir}",
"fileType":"text",
"defaultFS":"hdfs://hadoop102:8020",
"compress":"gzip",
"fileName":"activity_rule"
},
"name":"hdfswriter"
},
"reader":{
"parameter":{
"username":"root",
"column":[
"id",
"activity_id",
"activity_type",
"condition_amount",
"condition_num",
"benefit_amount",
"benefit_discount",
"benefit_level"
],
"connection":[
{
"table":[
"activity_rule"
],
"jdbcUrl":[
"jdbc:mysql://hadoop102:3306/gmall"
]
}
],
"password":"*******",
"splitPk":""
},
"name":"mysqlreader"
}
}
],
"setting":{
"speed":{
"channel":3
},
"errorLimit":{
"record":0,
"percentage":0.02
}
}
}
}
2.2.3 gmall.base_category1.json配置文件编写
{
"job":{
"content":[
{
"writer":{
"parameter":{
"writeMode":"append",
"fieldDelimiter":"\t",
"column":[
{
"type":"bigint",
"name":"id"
},
{
"type":"string",
"name":"name"
}
],
"path":"${targetdir}",
"fileType":"text",
"defaultFS":"hdfs://hadoop102:8020",
"compress":"gzip",
"fileName":"base_category1"
},
"name":"hdfswriter"
},
"reader":{
"parameter":{
"username":"root",
"column":[
"id",
"name"
],
"connection":[
{
"table":[
"base_category1"
],
"jdbcUrl":[
"jdbc:mysql://hadoop102:3306/gmall"
]
}
],
"password":"*******",
"splitPk":""
},
"name":"mysqlreader"
}
}
],
"setting":{
"speed":{
"channel":3
},
"errorLimit":{
"record":0,
"percentage":0.02
}
}
}
}
2.2.4 gmall.base_category2.json配置文件编写
{
"job":{
"content":[
{
"writer":{
"parameter":{
"writeMode":"append",
"fieldDelimiter":"\t",
"column":[
{
"type":"bigint",
"name":"id"
},
{
"type":"string",
"name":"name"
},
{
"type":"bigint",
"name":"category1_id"
}
],
"path":"${targetdir}",
"fileType":"text",
"defaultFS":"hdfs://hadoop102:8020",
"compress":"gzip",
"fileName":"base_category2"
},
"name":"hdfswriter"
},
"reader":{
"parameter":{
"username":"root",
"column":[
"id",
"name",
"category1_id"
] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









