







3.1SQL概述
Structured Query Language
mysql安装
3.2学生-课程数据库
3.3数据定义
进入mysql
mysql;
or
mysql -uroot -p

创建数据库
CREATE DATABASE cyp;
查看已创建的databases
在早期,databases和schema本质没有区别
并且sql关键字不区分大小写,但是自己的命名是区分大小写的
show databases;

使用数据库(进入模式)
use cyp;

查看数据库中的所有表
show tables;
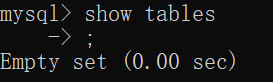
没创建所以一个都没有
创建
CREATE TABLE TAB1(COL1 SMALLINT,COL2 INT,COL3 CHAR(20),COL4 NUMERIC(10,3), COL5 DECIMAL(5,2));

再次查看表
SHOW TABLES;
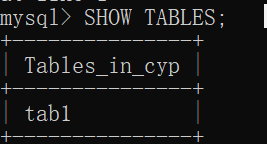
查看表中细则
DESC TAB1;

展示当初创建表时候的情况
SHOW CREATE TABLE TAB1;

删除表cyp
DROP DATABASE cyp ;

退出模式
再次
一行一行输入
>mysql -uroot -p //然后输入密码
>CREATE DATABASE cyp;
> use cyp;
> create table tab1 (c1 smallint,c2 int,c3 char(20),c4 numeric(10,3),c5 decimal(5,2));
> desc tab1;
> create table Student (Sno CHAR(9) PRIMARY KEY,Sname CHAR(20) UNIQUE,Ssex CHAR(2),Sage SMALLINT,Sdept CHAR(20));
> desc student;
> create table Course(Cno CHAR(4) PRIMARY KEY,Cname CHAR(40)NOT NULL,Cpno CHAR(4),Ccredit SMALLINT,FOREIGN KEY(Cpno)REFERENCES Course(Cno));
> DESC cOURSE;
> CREATE TABLE SC(Sno CHAR(9),Cno CHAR(4),Grade SMALLINT,PRIMARY KEY(Sno,Cno),FOREIGN KEY (Sno) REFERENCES Student(Sno),FOREIGN KEY(Cno) REFERENCES Course(Cno));
> DESC SC;

在student表中增加一行
ALTER TABLE Student ADD S_entrance DATE;

修改类型
将age的字符型改成整数型
ALTER TABLE STUDENT MODIFY COLUMN Sage INT;

增加课程名称必须取唯一值的约束条件
ALTER TABLE Course ADD UNIQUE(Cname);

删除基本表
DROP TABLE <表名> [RESTRICT|CASCADE];/*有限制|无限制*/
DROP TABLE STUDENT CASCADE;
表示删不掉

CREATE VIEW IS_STUDENT
-> AS
-> SELECT Sno,Sname,Sage
-> FROM Student
-> WHERE Sdept='is';

DROP TABLE Student RESTRICT;
DROP TABLE Student CASCADE;
SELECT *FROM IS_STUDENT;

不同的sql的细节不同
见page87
索引类型
顺序文件的索引
B+树索引
散列索引
位图索引
建立索引
CREATE UNIQUE INDEX Stusno ON Student(Sno);
CREATE UNIQUE INDEX Coucno on Course(Cno);
CREATE UNIQUE INDEX Scno ON SC(Sno ASC,Cno DESC);

修改索引
遇到bug了
3.4数据查询
套路:
SELECT [ALL|DISTINCT] <目标列表达式> [,<目标列表表达式>]... /*3在按照SELECT子句中的目标列表式选出元组中的属性值形成结果表
FROM<表名或视图名>[,<表名或视图名>...]|(<SELECT语句>)[AS]<别名> /*2从from子句指定的基本表,视图,或派生表找到满足条件的元组
[WHERE<条件表达式>] /*1根据where条件表达式
[GROUP BY<别名1>[HIVING<条件表达式>]] /*如果有,按照列名1的值进行分组,改属性列值相等的元组分一组
[ORDER BY<列名2>[ASC|DESC]]; /* 如果有,按照列表2的值进行升序或者降序排序
单表查询
SELECT Sno,Sname
FROM student;
SELECT Sname,Sno,Sdept
FROM Student;
查询全体学生
SELECT*
FROM Student;
查询经过计算的值
SELECT Sname,2021-Sage /*当年减去年龄得到年份
FROM Student;
选择列
SELECT Sname,'Year of Birth:',2014-Sage,LOWER(Sdept)
FROM Student;
通过指定别名来改变查询结果的列标题
SELECT Sname NAME,'Year of Birth:'BIRTH,2014-Sage BIRTHDAY,LOWER(Sdept)DEPARTMENT
FROM Student;
消除取值重复的行
SELECT (ALL) Sno
FROM SC;
去重
SELECT DISTINCT Sno
FROM SC;
查询满足条件的元组
| 查询条件 | 谓词 |
|---|---|
| 比较 | =,>,<,>=,<=,!=,<>,!>,!<;NOT+上述比较运算符 |
| 确定范围 | BETWEEN AND,NOT BETWEEN AND |
| 确定集合 | IN,NOT IN |
| 字符匹配 | LIKE,NOT LIKE |
| 空值 | IS NULL ,IS NOT NULL |
| 多重条件(逻辑运算) | AND,OR,NOT |
查询计算机科学系全体学生的名单
SELECT Sname
FROM Sudent
WHERE Sdept='CS';
查询所有年龄在20岁以下的学生的姓名以及年龄
SELECT Sname,Sage
FROM Student
WHERE Sage<20;
查询考试成绩不及格的学生的学号
SELECT DISTINCT Sno
FROM SC
WHERE Grade<60;
查询年龄在20~23岁之间的学生姓名。系别和年龄。
SELECT Sname,Sdept,Sage
FROM Sdudent
WHERE Sage BETWEEN 20 AND 23;
查询年龄不在20~23岁之间的学生姓名系别和年龄
SELECT Sname,Sdept,Sage
FROM Sdudent
WHERE Sage NOT BETWEEN 20 AND 23;
IN可以用来查找属性值属于指定集合的元组
查询计算机科学系。数学系、和信息系
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN ('CS','MA','IS');
字符匹配
谓词like可以用来进行字符串的匹配
[NOT] LIKE'<匹配串>' [ESCAPE'<换码字符>']
SELECT*
FROM Student
WHERE Sno LIKE '20192502';
等价于
SELECT*
FROM Student
WHERE Sno ='20192502';
姓刘的
以下没有必要不写找啥,从那个表找
SELECT
FROM
WHERE Sname LIKE '刘%';
欧阳啥
SELECT
FROM
WHERE Sname LIKE '欧阳_';
_代表必须得有
%代表string可以为空
_阳%
SELECT
FROM
WHERE Sname LIKE '_阳%';
不姓刘
SELECT
FROM
WHERE Sname NOT LIKE '刘%';
转义字符
ESCAPE ‘\’
SELECT
FROM
WHERE Cname LIKE 'DB\_Design' ESCAPE'\';
查询以‘DB_’开头,且倒数第三个字符为i的课程的详细情况
SELECT *
FROM Course
WHERE Cname LIKE 'DB\_%i__' ESCAPE'\';
NULL
SELECT
FROM
WHERE Grade IS NULL;
SELECT
FROM
WHERE Grade IS NOT NULL;
多重条件查询
SELECT
FROM
WHERE Sdept='CS' AND Sage <20;
SELECT
FROM
WHERE Sdept='CS' OR Sdept='MA' OR Sdept='IS';
第四行加入
默认升序ASC降序DESC
ORDER BY Grade DESC;
A升序B降序
ORDER BY A,B DESC;
聚焦函数
COUNT(*) 统计元组个数
COUNT([DISTINCT|ALL]<列名>) 统计一列中值的个数
SUM([DISTINCT|ALL]<列名>) 计算一列值的总和(整数列)
AVG([DISTINCT|ALL]<列名>) 计算一列值的平均值(整数列)
MAX([DISTINCT|ALL]<列名>) 计算一列值的最大值
MIN([DISTINCT|ALL]<列名>) 计算一列值的最小值
















 4789
4789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











