






Hive 官网
https://cwiki.apache.org/confluence/display/Hive//GettingStarted
- 下载hive tar包
- 放入目录解压
- 在hive_home/conf中
vi hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://MysqlIP地址:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.thrift.bind.host</name>
<value>IP地址A:9083</value>
</property>
</configuration>4.将mysql的驱动拷贝到hive_home/lib 下
下载地址:https://downloads.mysql.com/archives/c-j/
如果完成后hive连接mysql时有报错更换驱动版本试试可能是过低导致的
5.1直接启动hive
schematool -dbType mysql -initSchema
bin/hive show databases; 可在mysql中查看是否有hive库。
5.2 使用beeline连接hive
1. 启动beeline的服务:bin/hiveserver2
2. 在另一个shell中 bin/beeline
3. jdbc连接hive服务
!connect jdbc:hive2://IP地址:10000 root pwdxxx
!connect jdbc:hive2://IP地址:10000/xxx pwdxxx
5.3 另一种方法连接hive;A服务器 上的metastroe server 的配置;
结构:mysql -> metastroe server 9083 -> hive (生产环境一般是这种 前面可以是Oracle或者MySQL)
在IP地址A 服务器上启动服务:
bin/hive --service metastore
在B服务器上直接启动bin/hive即可。
6.显示hive列名与不显示表名
写入显示列名+表名
set hive.cli.print.header=true;
不显示表名
set hive.resultset.use.unique.column.names=false;
配置可以加到hive-site.xml中设置默认
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>7.导入数据
7.1. 向表中装载数据(Load)
再hive上提前创建好表
hive>load data [local] inpath '路径' [overwrite] into table 表名 [partition (分区字段=值,…)];
overwrite:表示覆盖表中已有数据,否则表示追加
如:
从本地文件系统加载数据到hive表
load data local inpath '/root/data/testxx.txt' into table testxx;
从hdfs文件系统加载数据覆盖hive表
hive (default)> dfs -put /root/data/testxx.txt /xxx;
hive (default)> load data inpath '/xxx/test.txt' overwrite into table test;
7.2.创建表时加载数据
(1)创建表时使用查询语句as select
create table if not exists 表名A as 别名 FROM 表名B;
(2)创建表时通过location指定加载数据路径
7.3.通过查询语句向表中插入数据
insert into:以追加数据的方式插入到表或分区,原有数据不会删除
INSERT INTO TABLE tablenamexxx [PARTITION(partcol1=val1, partcol2=val2 ...)] 字段名xxFROM xx表名;
insert overwrite:覆盖表中已存在的数据
INSERT OVERWRITE TABLE tablenamexxx [PARTITION (partcol1=val1, partcol2=val2 ...) ] 字段名xx FROM xx表名;
7.4. Import数据到指定Hive表中
先用export导出后,再将数据导入(export和import主要用于两个Hadoop平台集群之间Hive表迁移)
import table 表名 from '路径';
例:
从A集群中导出hive表数据:
export table 库名.表名 to '/testxx/export';
向B集群中导入数据到hive表:
import table 表名 from '/testxx/export' ;
7.5. sqoop导入数据
7.6 三种数据格式导入88示例:
hive>load data inpath '/data/hive/test.txt' into table 表名; //关联表 (文件可以存在本地或者hdfs上)
hive>set hive.exec.mode.local.auto=true; //设置本地模式
将文件放入hdfs上或者本地上
array (集合)格式===============================
创建测试数据文件放入本地或hdfs上 DATA(vi test1.txt):
zhangsan,10000000:1234500000
zhangsan,11000000:1234500000:123456000
在hive上创建表
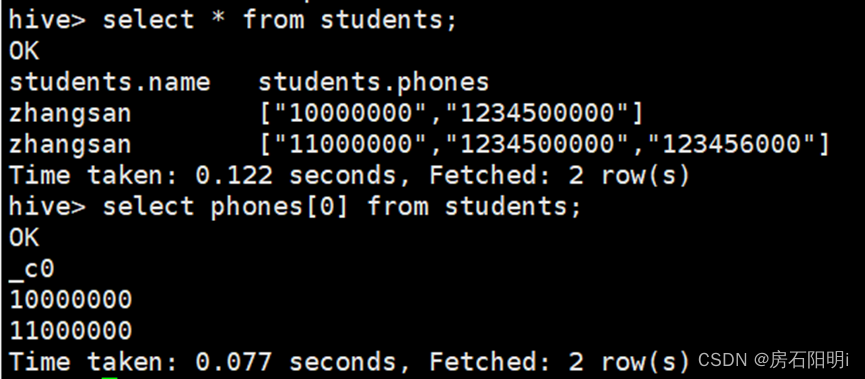
Hive> create table students (
name string,
phones array<string>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY ':'; hive>load data local inpath '/root/test1.txt' into table students;查看集合内的首数据
hive> select phones[0] from students;
Map 格式 ===============================
DATA: vi test2.txt
zhangsan,math:10|english:100
zhangsan,math:10|english:100|chinese:100
zhangsan,math:10|english:100|chinese:100|tiyu:1000
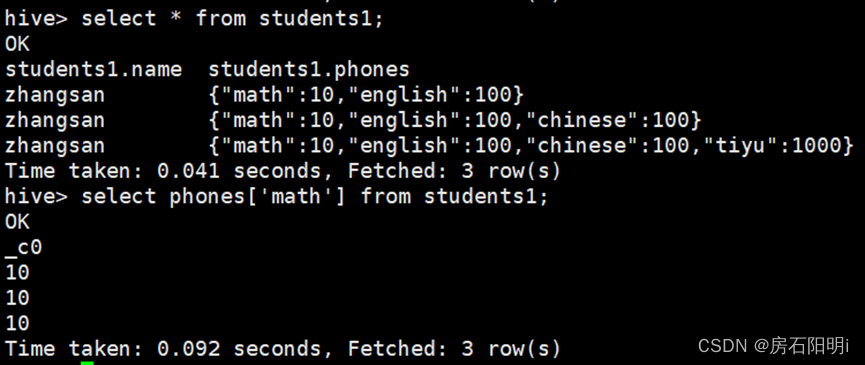
hive>create table students1 (
name string,
phones map<string,int>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '|'
MAP KEYS TERMINATED BY ':';hive>load data local inpath '/root/test2.txt' into table students1;hive> select phones['math'] from students1; //查看map内的value
struct格式===============================
DATA: vi test3.txt
zhangsan,zhangsan:20,50
zhangsan,zhangsan:21,60
zhangsan,zhangsan:22,70
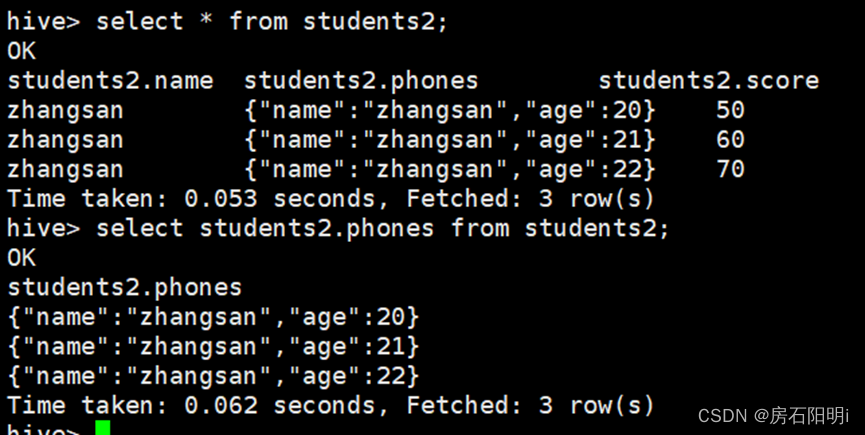
hive>create table students2 (
name string,
phones struct<name:string,age:int>,
score int
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY','
COLLECTION ITEMS TERMINATED BY ':';hive>load data local inpath '/root/test3.txt' into table students2;
hive>select person.name from students2;
特殊数据类型:
---正则表达式:最终的解决方案
1::F::11::10::11111
2::M::22::16::22222
3::M::33::15::33333
4::M::44::7::44444
5::M::55::20::55555
6::F::66::9::66666
7::M::77::1::77777
8::M::88::12::88888
9::M::99::17::99999
10::F::10::1::10101
create table users(
user_id bigint,
gender String,
age int,
occupation String,
zipcode bigint)
ROW FORMAT serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties
('input.regex' = '^(.*)::(.*)::(.*)::(.*)::(.*)$','output.format.string' = '%1$s%2$s%3$s%4$s%5$s')
stored as textfile;
load data local inpath '/root/users.dat' into table users;
8.hive数据导出方法(5种)
8.1. Insert方式,查询结果导出到本地或HDFS提前创建好目录
导出到本地上
mkdir hiveoutdata
insert overwrite local directory '/root/hiveoutdata/testxx' select * from testxx;
导出到HDFS上
insert overwrite directory '/testxx' row format delimited fields terminated by ',' select * from testxx;
8.2. Hadoop命令导出本地
hive>dfs -get /user/hive/warehouse/student/ 000000_0 /root/hadoop/student.txt
8.3. hive Shell命令导出
创建好用于存储导出数据的文件
touch testxx.txt
$ bin/hive -e ‘select * from testxx;’ > /root/testxx.txt
注:>>表示追加的意思,>表示覆盖。
8.4. Export导出到HDFS上
hive>export table testxx to ‘/testxxt’;
8.5. Sqoop导出














 1892
1892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









