






如果循环并用hive解决:可选UDF+explode(行转列) 或者 Spark rdd SQL
UDF:一进一出
UDAF:聚集函数,多进一出,类似于:count/max/min
UDTF:一进多出,如explore()、posexplode(),UDTF函数的时候只允许一个字段
UDF脱敏
1.pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>UDFTEST</artifactId>
<version>1.0-SNAPSHOT</version>
<name>UDFTEST</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.1.0-cdh5.14.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
</project>2.用idea自定义UDF
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class Desensitization extends UDF {
public Text evaluate(Text text) {
String str = text.toString();
String result = str.replace(str.substring(3, 9), "******");
return new Text(result);
}
}3.1打包上传到liunx目录(方法1本地)
hive>add jar /root/data/UDFTEST-1.0-SNAPSHOT-jar-with-dependencies.jar //添加jar包
hive>create temporary function desensitization as 'demo.Desensitization'; //创建一个临时函数
hive>select desensitization('12000000001'); //调用自定义脱敏函数3.2打包上传到HDFS(方法2hdfs)
linux>hdfs dfs -mkdir -p /user/hive
linux>hdfs dfs -put UDFTEST-1.0-SNAPSHOT-jar-with-dependencies.jar /user/hive
hive>CREATE FUNCTION desensitization AS 'demo.Desensitization' USING JAR 'hdfs://user/hive/UDFTEST-1.0-SNAPSHOT-jar-with-dependencies.jar';
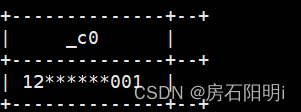
select desensitization('12000000001');结果可将电话号码进行脱敏:
explode 一行炸多列
1.在linux本地创建数据文件
linux>vi test.txt
name,age,java,y,男
name,age,java,y
name,java,y,女2.hive创建表导入数据
hive>create table test2(
line string
);
hive>load data local inpath '/root/data/test.txt' into table test2;3.查看炸裂
hive>select
*
from
(select explode(split(line,',')) as word from test2) t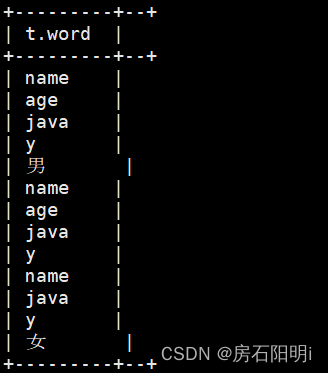
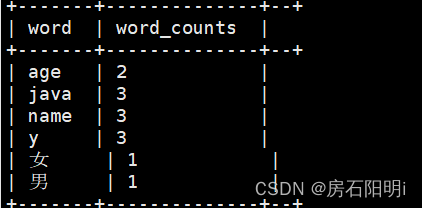
4.Hive word_count
hive>select
word,
count(1) as word_counts
from
(select explode(split(line,',')) as word from test2) t
group by word4.2另一种方式(with temp AS 为测试图)
hive>with temp as(
SELECT word
FROM test2 LATERAL VIEW explode(split(line,',')) t AS word
)
select
word,
count(1) as word_counts
from temp
group by word结果:
explode()将一行数据转换成列数据,可以用于array和map类型的数据
1)explode()用于array的语法如下:
select explode(arraycol) as newcol from tablename;
#arraycol:arrary数据类型字段。
#tablename:表名2)explode()用于map的语法如下:
select explode(mapcol) as (keyname,valuename) from tablename;
#tablename:表名
#mapcol:map类型的字段
#keyname:表示key转换成的列名称,用于代表key转换之后的列名。
#valuename:表示value转换成的列名称,用于代表value转换之后的列名称。explode()用于map类型的数据时,由于map是kay-value结构的,所以它在转换的时候会转换成两列,一列是kay转换而成的,一列是value转换而成的。
3)以上为explode()函数的用法,此函数存在局限性:
其一:不能关联原有的表中的其他字段。
其二:不能与group by、cluster by、distribute by、sort by联用。
其三:不能进行UDTF嵌套。
其四:不允许选择其他表达式。
lateral view侧视图
lateral view为侧视图,其实就是用来和像类似explode这种UDTF函数联用的,lateral view会将UDTF生成的结果放到一个虚拟表中,然后这个虚拟表会和输入行进行join来达到连接UDTF外的select字段的目的。
不加lateral view的UDTF函数只能提取单个字段拆分,并不能塞回原来数据表中。加上lateral view就可以将拆分的单个字段数据与原始表数据关联上。在使用lateral view的时候需要指定视图别名和生成的新列别名
1)udtf + lateral view 一
lateral view udtf(expression) tableAlias as columnAlias (,columnAlias)*lateral view在UDTF前使用,表示连接UDTF所分裂的字段。
UDTF(expression):使用的UDTF函数,例如explode()。
tableAlias:表示UDTF函数转换的虚拟表的名称。
columnAlias:表示虚拟表的虚拟字段名称,如果分裂之后有一个列,则写一个即可;如果分裂之后有多个列,按照列的顺序在括号中声明所有虚拟列名,以逗号隔开。
2)udtf + lateral view 二
from basetable (lateral view)*3)udtf + lateral view 三(Hive0.12开始支持)
from basetable (lateral view outer)*outer的作用是在UDTF转换列的时候将其中的空也给展示出来,UDTF默认是忽略输出空的
案例:
1求一下每个学生成绩最好的学科及分数、最差的学科及分数、平均分数
1.1.linux本地准备数据
linux>vi testdata1.txt
zhangsan|Chinese:80,Math:60,English:90
lisi|Chinese:90,Math:80,English:70
wangwu|Chinese:88,Math:90,English:96
maliu|Chinese:99,Math:65,English:601.2.hive创建表
hive>create table stu_score_test(name string,score map<String,string>)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':';1.3.导入数据
hive>load data local inpath '/root/data/testdata1.txt' into table stu_score_test;1.4.hive查看数据
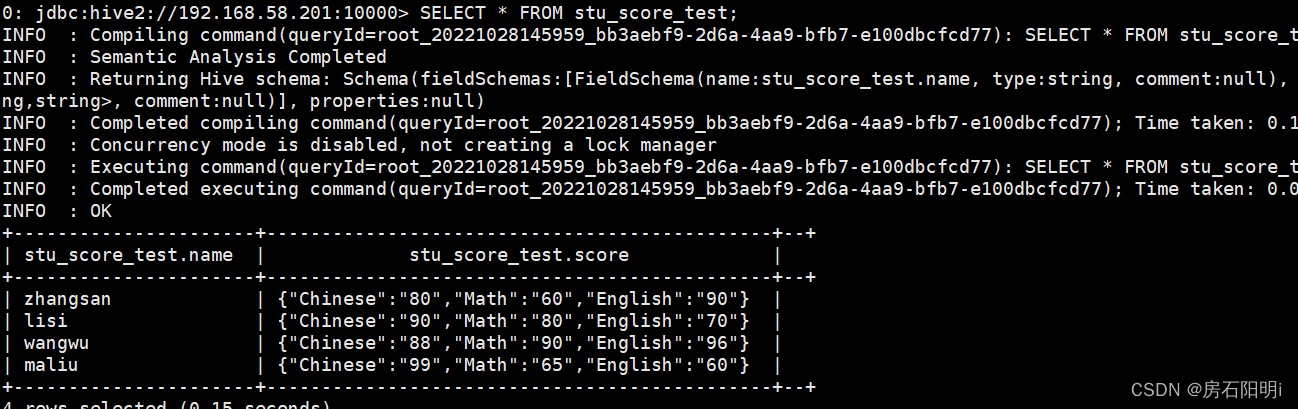
1. 5.hive计算
hive>select
name,course,csorce
from(
select
name
,course
,csorce
,rank()over(partition by name order by csorce) last_rn
,rank()over(partition by name order by csorce desc) best_rn
from stu_score_test
lateral view explode(score) score_view as course,csorce
)aa
where last_rn=1 or best_rn=11.6.查看结果
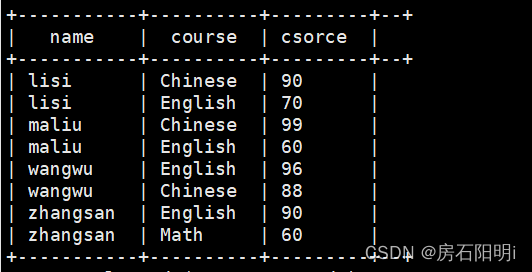
2.计算酒店每天有多少个房间的入住
2.1.linux本地准备数据
linux>vi testdata2.txt
7,2004,2021-03-05,2021-03-07
23,2010,2021-03-05,2021-03-06
7,1003,2021-03-07,2021-03-08
8,2014,2021-03-07,2021-03-08
14,3001,2021-03-07,2021-03-10
18,3002,2021-03-08,2021-03-10
23,3020,2021-03-08,2021-03-09
25,2006,2021-03-09,2021-03-122. 2.hive建表
hive>create table temp_hotal_live(
user_id varchar(50),
room_code varchar(50),
Check_date varchar(50),
leave_date varchar(50)
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
;2.3.hive导入数据
hive>load data local inpath '/root/data/testdata2.txt' into table temp_hotal_live;2.4.hive查看数据

2.5.hive计算
用posplode炸裂,补充完整时间
hive>SELECT
t.start_dd,t.end_dd,count(1)
from
(SELECT
user_id,
check_date,
leave_date,
date_add( check_date, pos ) start_dd,
date_add( check_date, pos+1 ) end_dd
FROM
temp_hotal_live
lateral VIEW
posexplode ( split ( REPEAT('A,',datediff( leave_date, check_date )) , ',' ) ) t AS pos, val
) t
group by t.start_dd,t.end_dd;2.6.查看结果
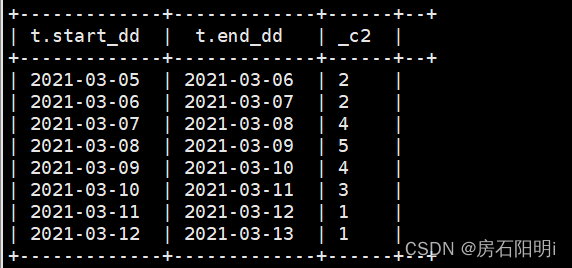
datediff,计算住了多少天,两个时间之间的差值
REPEAT(),把字符串复制多少次,把'A,'本题是把A,复制
split,把字符串按分隔符分割为数组
posexplode :炸裂,并排序
3.找出相同数字的号码超过5位的手机号
3.1. Linux 本地创建数据
linux>vi testdata3.txt
jimmhe,18191512076
xiaosong,18392988059
jingxianghua,18118818818
donghualing,17191919999
3.2. hive创建表
hive>CREATE TABLE udtf_test1(
name string,
phonenumber string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','3.3. hive加载数据
hive>load data local inpath '/root/data/testdata3.txt' into table udtf_test1;3.4.hive查看数据
hive>select * from udtf_test1;
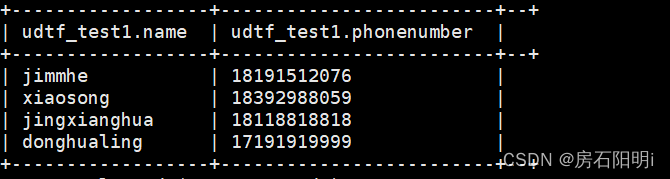
split将电话号码,拆分成数组,在用explode炸裂
3.4.hive计算
hive>select name,phonenumber
from(
select
name
,phonenumber
,phone_num
from udtf_test1
lateral view explode(split(phonenumber,'')) view_number as phone_num)aa
group by name,phonenumber,phone_num
having count(1)>=53.5.结果
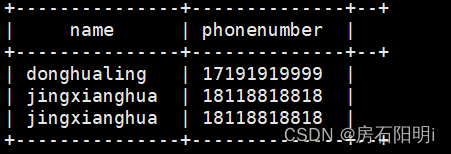















 4506
4506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









