






flink-cdc官网:Oracle CDC Connector — CDC Connectors for Apache Flink® documentation
Flink环境依赖:
(1)下载postgresql jdbc jar包 postgresql-42.3.5 和 flink-sql-connector-oracle-cdc-2.2.0.jar将包放到flink 下 lib目录里面 下载地址https://jdbc.postgresql.org/download.html flink-connector-jdbc_2.12_1.14.4.jar 包 https://mvnrepository.com/artifact/org.apache.flink/flink-connector-jdbc_2.12/1.14.4 (2)以 DBA 身份连接到数据库
ORACLE_SID=SID
export ORACLE_SID
sqlplus /nolog
CONNECT sys/password AS SYSDBA(3)启用日志归档
alter system set db_recovery_file_dest_size = 10G;
alter system set db_recovery_file_dest = '/opt/oracle/oradata/recovery_area' scope=spfile;
shutdown immediate;
startup mount;
alter database archivelog;
alter database open;
• 启用日志归档需要重启数据库,尝试时注意
• 归档日志会占用大量磁盘空间,建议定期清理过期日志(4)检查是否启用了日志归档
-- Should now "Database log mode: Archive Mode"
archive log list;
必须为捕获的表或数据库启用补充日志记录,以便数据更改捕获已更改数据库行的之前状态。下面说明了如何在表/数据库级别进行配置。
-- Enable supplemental logging for a specific table:
ALTER TABLE inventory.customers ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
-- Enable supplemental logging for database
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;(5)创建具有权限的 Oracle 用户
(5.1)。创建表空间
sqlplus sys/password@host:port/SID AS SYSDBA;
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/SID/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
exit;
(5.2)。创建用户并授予权限
sqlplus sys/password@host:port/SID AS SYSDBA;
CREATE USER flinkuser IDENTIFIED BY flinkpw DEFAULT TABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS;
GRANT CREATE SESSION TO flinkuser;
GRANT SET CONTAINER TO flinkuser;
GRANT SELECT ON V_$DATABASE to flinkuser;
GRANT FLASHBACK ANY TABLE TO flinkuser;
GRANT SELECT ANY TABLE TO flinkuser;
GRANT SELECT_CATALOG_ROLE TO flinkuser;
GRANT EXECUTE_CATALOG_ROLE TO flinkuser;
GRANT SELECT ANY TRANSACTION TO flinkuser;
GRANT LOGMINING TO flinkuser;
GRANT CREATE TABLE TO flinkuser;
GRANT LOCK ANY TABLE TO flinkuser;
GRANT ALTER ANY TABLE TO flinkuser;
GRANT CREATE SEQUENCE TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkuser;
GRANT SELECT ON V_$LOG TO flinkuser;
GRANT SELECT ON V_$LOG_HISTORY TO flinkuser;
GRANT SELECT ON V_$LOGMNR_LOGS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkuser;
GRANT SELECT ON V_$LOGFILE TO flinkuser;
GRANT SELECT ON V_$ARCHIVED_LOG TO flinkuser;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkuser;Flink SQL 客户端连接器测试:
- 创建Oracle链接器
CREATE TABLE TEST_source (
ID INT,
PRIMARY KEY (ID) NOT ENFORCED
) WITH (
'connector' = 'oracle-cdc',
'hostname' = 'Oracle_IP地址',
'port' = '1521',
'username' = 'flinkuser',
'password' = 'flinkpw',
'database-name' = 'ORA19C',
'schema-name' = 'FLINKUSER',
'table-name' = 'TEST'
'debezium.log.mining.strategy'='online_catalog'
);2.创建postgresql链接器接收端
create table flink_cdc_sink1(
ID INT,
primary key(ID) NOT ENFORCED)
with(
'connector' = 'jdbc',
'url' = 'jdbc:postgresql://pg库_IP地址:5432/ postgres?currentSchema=public',
'username' = 'postgres',
'password' = '123456',
'table-name' = 'sink1'
);3.插入数据
insert into flink_cdc_sink1 select ID from TEST_source;4.问题:数据同步不过去

解决方案:检查flink-connector-jdbc.jar包 版本问题 替换即可
FLINK Oracle to Postgresql (JAVA)
1. java编码
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* 测试 flink cdc 实时获取oracle数据变化
*/
public class FlinkCdcOracleExample {
public static void main(String[] args) throws Exception {
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, fsSettings);
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
String sourceDDL ="CREATE TABLE oracle_source (\n" +
" ID INT, \n" +
" NAME STRING, \n" +
" PRIMARY KEY (ID) NOT ENFORCED \n" +
" ) WITH (\n" +
" 'connector' = 'oracle-cdc',\n" +
" 'hostname' = 'Oracle_IP地址',\n" +
" 'port' = '1521',\n" +
" 'username' = 'flinkuser',\n" +
" 'password' = 'flinkpw',\n" +
" 'database-name' = 'ORA19C',\n" +
" 'schema-name' = 'FLINKUSER',\n" + // 注意这里要大写
" 'table-name' = 'tablename',\n" +
" 'debezium.log.mining.strategy'='online_catalog'\n"+
" )";
// 创建一张用于输出的表
String sinkDDL = "CREATE TABLE outTable (\n" +
" id INT,\n" +
" name STRING, \n" +
" PRIMARY KEY (id) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:postgresql://PG库_IP地址:5432/postgres?currentSchema=public',\n" +
" 'username' = 'postgres',\n" +
" 'password' = '123456',\n" +
" 'table-name' = 'pg_sink'\n" +
")";
/*String transformSQL =
"select * from oracle_source ";*/
String transformSQL =
"INSERT INTO outTable " +
"SELECT ID,NAME " +
"FROM oracle_source";
//执行source表ddl
tableEnv.executeSql(sourceDDL);
//TableResult tableResult = tableEnv.executeSql("select * from oracle_source");
//tableResult.print();
//执行sink表ddl
tableEnv.executeSql(sinkDDL);
//执行逻辑sql语句
TableResult tableResult = tableEnv.executeSql(transformSQL);
tableResult.print();
env.execute();
}
}返回内容 以上代码是修改后的应不会有下图报错
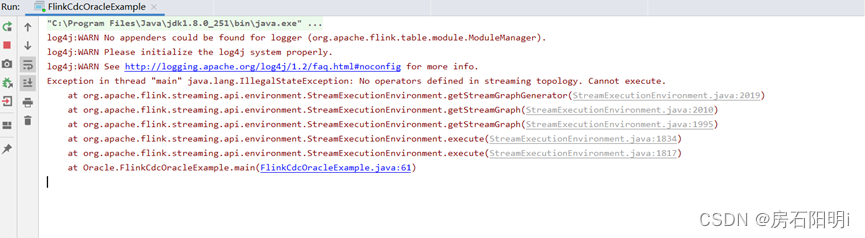
注:报这个错误,但数据可以同步过去
错误:可以读取oracle表内的数据,但jdbc连接postgres 报错,数据传不过去
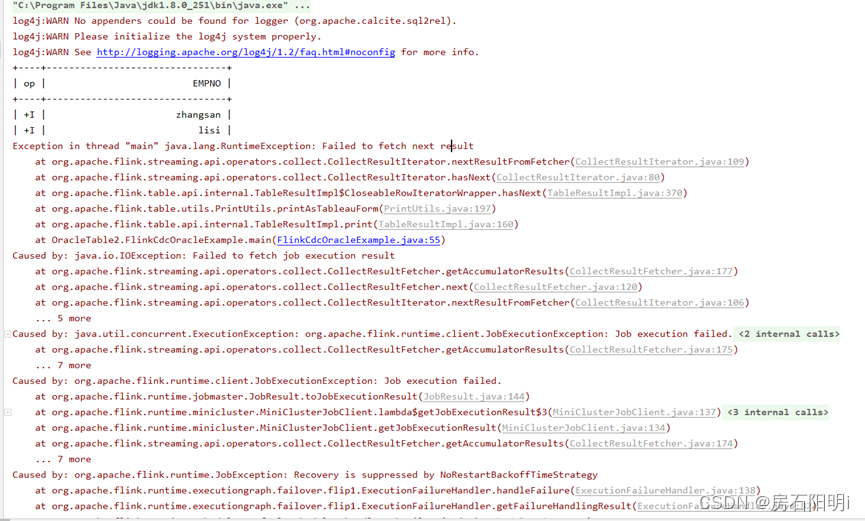
解决:修改maven依赖
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-oracle-cdc</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.3.5</version>
</dependency>flink sql 端 创建oracle 接收器
create table flink_cdc_sink (
ID INT,
NAME STRING
)with(
'connector' = 'jdbc',
'url' = 'jdbc:oracle:thin:@192.168.58.202:1521:ORA19C',
'username' = 'flinkuser',
'password' = 'flinkpw',
'table-name' = 'TEST2',
'driver' = 'oracle.jdbc.driver.OracleDriver');报错:
![]()
jdbc 连接oracle错误处理 解决方法:目前flink 1.14不支持jdbc 连接oracle 需要安装 flink 1.15 处理 Flink 1.15 安装 需要使用java11
1.官网下载java 11
https://www.oracle.com/java/technologies/downloads/#java112.解压 jdk tar 包
linux>tar -xzvf jdk-11.0.15.1_linux-x64_bin.tar.gz3.修改环境配置文件
linux> vim /etc/profile
# Java11环境变量配置
JAVA_HOME=/devtools/java/java11/jdk-11.0.15
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/lib
export JAVA_HOME CLASSPATH PATH
# Java8环境变量配置
JAVA_HOME=/devtools/java/java8/jdk1.8.0_321
PATH=$PATH:$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/lib
export JAVA_HOME PATH CLASSPATH4.重启电脑生效
5.下载flink 1.15
linux>Wget https://dlcdn.apache.org/flink/flink-1.15.0/flink-1.15.0-bin-scala_2.12.tgz6.配置 flink 1.15
linux>vim conf/flink-conf.yaml
jobmanager.rpc.address: jobIP地址
# 配置high-availability mode
high-availability: zookeeper
# JobManager的meta信息放在dfs,在zk上主要会保存一个指向dfs路径的指针
high-availability.storageDir: hdfs://cluster/flinkha/
# 配置zookeeper quorum(hostname和端口需要依据对应zk的实际配置)
high-availability.zookeeper.quorum: IPA:2181,IPB:2181,IPC:2181
# (可选)设置zookeeper的root目录
#high-availability.zookeeper.path.root: /test_dir/test_standalone2_root
# 注释以下配置
# jobmanager.bind-host: localhost
# taskmanager.bind-host: localhost
#taskmanager.host: localhost
#rest.address: localhost
#rest.bind-address: localhost
#配置yarn 高可用重试次数
yarn.application-attempts: 10注意:必须要操作上面的“注释以下配置” 否则Web UI 访问不了 其余配置一样,可以参考最上面的搭建。















 2642
2642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









