






有时候,一个好的问题定义,要比一个解决方案更重要。
hadoop、hive、spark
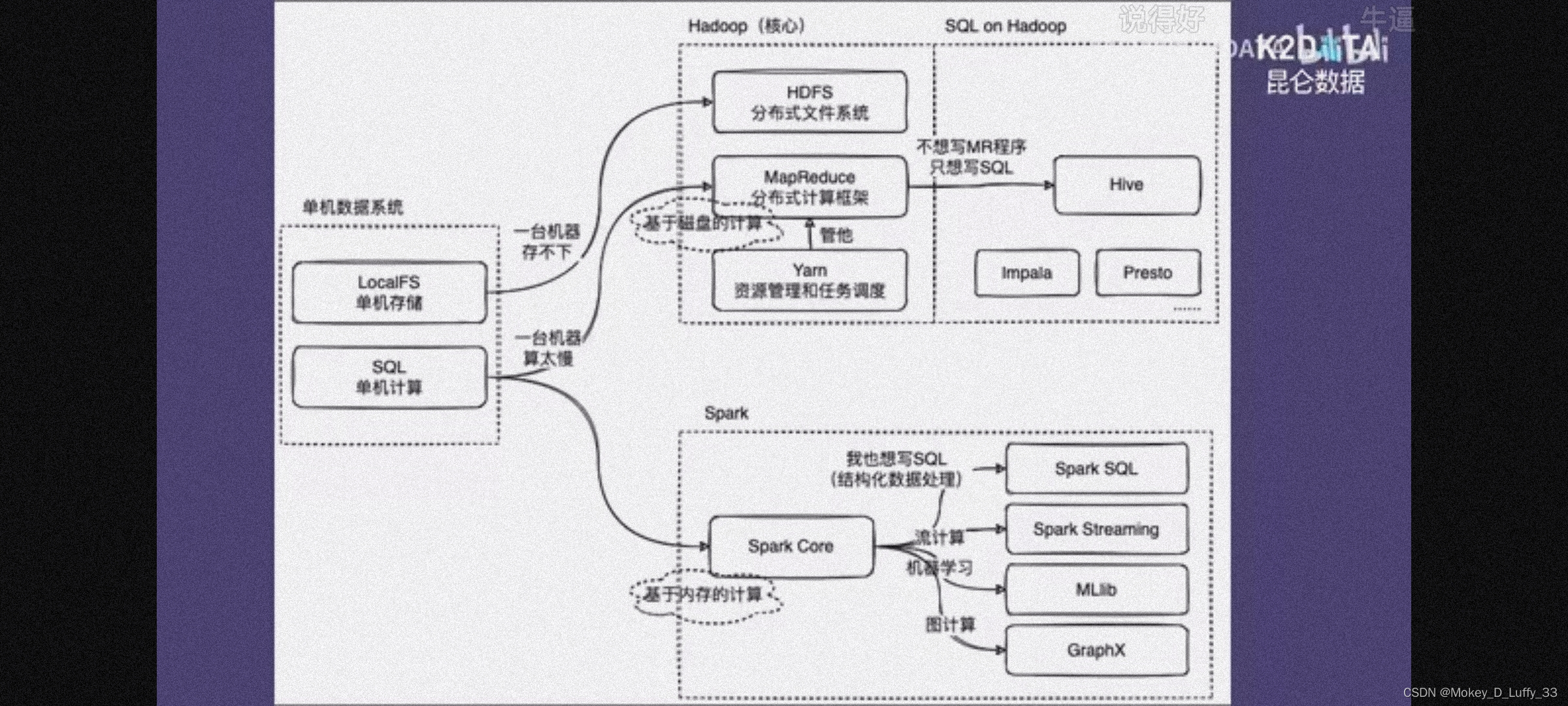
数据管理系统 处理两个问题:
1.数据怎么存?
2.数据怎么算?
单机->分布式
io密集型->cpu密集型
数据存储:HDFS(分布式文件系统)
hadoop生态中,HDFS扮演经理角色,去统一管理存储空间,提供一个接口,让这些机器看起来像一台机器上的,让客户感觉有无限大的存储空间,再基于这个去写应用程序
数据计算:MapReduce(映射、归约)
写程序去操作这100台机器,协作完成一个计算任务。任务怎么去分配到这些机器上?任务之间怎么去做同步?过程中,有台机器掉链子怎么办?(并行编程的复杂性)HDFS里面MapReduce模块处理这些问题。MR提供了一个任务并行框架,通过它的API抽象,让用户把并行(分布式处理程序)程序分为两个阶段:1.map阶段(任务量分配);2.reduce阶段(结果汇总)
在hadoop上面写sql:hive——在hadoop上进行结构化数据处理的解决方案
结构化处理S->查询Q->语言L
hive核心模块matestore用来存储结构化信息(“表”信息)。
过程:1.把sql语句进行语法分析,2.生成语法树(这两个步骤与数据库没什么区别)
3.hive的执行引擎,会把sql语句翻译成MR的任务去执行,4.把执行结果进行加工,返给用户
效率↑灵活性↓:数据处理的表达力和灵活性不如MR程序
在hadoop上写sql的其他方案:impala、presto
spark:是一个计算框架/引擎。经常被用来和hadoop里面的MR对比。
不同:spark是基于内存的计算,MR是基于磁盘的计算。所以spark的卖点就是快,极端情况下(数据集不大,机器的内存可以装得下),甚至比MR快100倍。一般认为spark比MR的处理程序快2-3倍左右。
相同:核心模块在使用体验上差不多,都提供一系列API,让开发者去写数据处理的程序。都有让用户去写sql的方案:hadoop-hive,spark-spark sql。
spark还提供了其他上层抽象,帮助用户写其他类型的数据处理程序:streaming模块->写流处理的程序;MLlib模块->写机器学习的程序;Graphx->图处理。















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









