









文章目录
- 五、数学问题
- 5.2最大公约数和最小公倍数
- 5.3分数的四则运算
- 5.4素数(质数)
- 5.4.1[素数的判断](https://blog.csdn.net/Moliay/article/details/132828386?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170981514616800197021234%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170981514616800197021234&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-132828386-null-null.nonecase&utm_term=%E7%B4%A0%E6%95%B0&spm=1018.2226.3001.4450)
- 5.4.2素数表的获取
- 5.5质因子分解
- 5.6大整数运算
- 5.7扩展欧几里得算法
- 六、c++标准模板库(STL)
五、数学问题
5.2最大公约数和最小公倍数
5.2.1最大公约数
- 约数,又称因数:整数a除以整数b(b≠0) 除得的商正好是整数而没有余数,就说a能被b整除,或b能整除a。a称为b的倍数,b称为a的约数。
- 正整数a与b的最大公约数:a和b的所有公约数中最大的那个公约数
#include<stdio.h>
int gcd(int a, int b){//求解最大公约数常用辗转相除法
if(b == 0) return a;
return gcd(b, a % b);
}
int main(){
int m, n;
scanf("%d%d", &m, &n);
printf("%d", gcd(m, n));
return 0;
}
5.2.2最小公倍数
- 正整数a和b的最小公倍数:a和b的所有公倍数中最小的那个公倍数
a和b的最小公倍数=ab/gcd(a, b)=a/(gcd(a,b))*b
即最小公倍数的计算在最大公约数的基础上进行。最小公倍数等于a和b的乘积除以a和b的最大公约数。其中ab在实际计算时可能会溢出,则进一步优化:先让其中之一除以最大公约数,再乘另一个数。
5.3分数的四则运算
分数的四则运算:给定两个分数的分子和分母,求它们加减乘除的结果。
5.3.1分数的表示与化简
假分数形式最简洁,用结构体来存储这种只有分子和分母的分数
- 表示规范:
- 分母down为非负数。若分数为负,则另分子up为负即可
- 若分数为0,则分子up为0,分母down为1
- 分子和分母没有除了1之外的公约数
struct Fraction{//分数
int up, down;//分别表示分子、分母
}
为了满足上述的三个规范,可能需要化简来实现
- 分数化简
- 若分母down为负数,则另分子up和分母down都变为相反数(符号位在分子)
- 若分子up为0,则林分母down为1
- 约分:求出分子绝对值和分母绝对值的最大公约数d,再另分子分母同时除以最大公约数d
Fraction reduction(Fraction result){//化简分数
if(result.down < 0){//符号位在分子
result.down *= -1;
result.up *= -1;
}
if(result.up == 0){//0约定为分子为0,分母为1
result.down = 1;
}
else{//分子不为0,进行约分
int d = gcd(abs(result.down), abs(result.up));
result.down /= d;
result.up /= d;
}
return result;
}
5.3.2分数的四则运算

Fraction add(Fraction a, Fraction b){//分数相加
Fraction c;
c.down = a.down * b.down;
c.up = a.up*b.down + b.up*a.down;
return reduction(c);
}
Fraction minu(Fraction a, Fraction b){//分数相加
Fraction c;
c.down = a.down * b.down;
c.up = a.up*b.down - b.up*a.down;
return reduction(c);
}
Fraction multi(Fraction a, Fraction b){//分数相乘
Fraction c;
c.down = a.down * b.down;
c.up = a.up * b.up;
return reduction(c);
}
//除法中注意,先判断除数是否为0:
//①除数为0,按照题目要求输出(例如error、inf等)
//②除数非0时,再进入下述函数
Fraction divide(Fraction a, Fraction b){//分数相除
Fraction c;
c.down = a.down * b.up;
c.up = a.up * b.down;
return reduction(c);
}
5.3.3分数的输出
- 注意:
- 输出分数前,先对其进行化简
- 若分数的分母为1,说明该分数为整数,一般来说题目会要求直接输出分子
- 若分数r的分子up大于分母down,则为假分数。需要按带分数的形式输出,即整数部分为r.up / r.down,分子部分为abs(r.up) % r.down
- 以上均不满足时,则为真分数,按原样输出即可
void showResult(Fraction f){//输出分数f
f = reduction(f);
if(f.down == 1) printf("%lld", f.up);//若为整数,则直接输出分子
else if(f.down < abs(f.up) printf("%d %d/%d", f.up/f.down, abs(f.up) % f.down, f.down);//若为假分数,则按带分数形式输出
else printf("%d/%d", f.up, f.down);//若为真分数,则直接原样输出
}
简单应用
#include<stdio.h>
#include<math.h>
struct Fraction{//分数表示
int down, up;
};
int gcd(int a, int b){//求最大公约数
if(b == 0) return a;
else return gcd(b, a%b);
}
Fraction reduction(Fraction f){//分数化简
if(f.down < 0){//若分母为负,则把负号调到分子上
f.down *= -1;
f.up *= -1;
}
if(f.up == 0) f.down = 1;//0约定表示为分子为0,分母为1
else{
int d = gcd(abs(f.up), abs(f.down));
f.up /= d;
f.down /= d;
}
return f;
}
Fraction add(Fraction a, Fraction b){//分数相加
Fraction c;
c.down = a.down * b.down;
c.up = a.up*b.down + b.up*a.down;
return reduction(c);
}
Fraction minu(Fraction a, Fraction b){//分数相加
Fraction c;
c.down = a.down * b.down;
c.up = a.up*b.down - b.up*a.down;
return reduction(c);
}
Fraction multi(Fraction a, Fraction b){//分数相乘
Fraction c;
c.down = a.down * b.down;
c.up = a.up * b.up;
return reduction(c);
}
Fraction divide(Fraction a, Fraction b){//分数相除
Fraction c;
c.down = a.down * b.up;
c.up = a.up * b.down;
return reduction(c);
}
void showResult(Fraction f){//输出分数f
f = reduction(f);
if(f.down == 1) printf("%lld", f.up);//若为整数,则直接输出分子
else if(f.down < abs(f.up)) printf("%d %d/%d", f.up/f.down, abs(f.up) % f.down, f.down);//若为假分数,则按带分数形式输出
else printf("%d/%d", f.up, f.down);//若为真分数,则直接原样输出
}
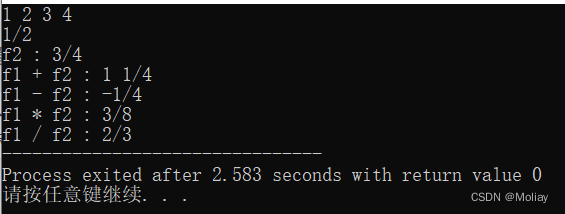
int main(){
Fraction f1, f2;
scanf("%d%d%d%d", &f1.up, &f1.down, &f2.up, &f2.down);
showResult(f1);
printf("\nf2 : ");
showResult(f2);
printf("\nf1 + f2 : ");
showResult(add(f1, f2));
printf("\nf1 - f2 : ");
showResult(minu(f1, f2));
printf("\nf1 * f2 : ");
showResult(multi(f1, f2));
printf("\nf1 / f2 : ");
showResult(divide(f1, f2));
return 0;
}
5.4素数(质数)
- 素数(质数):除了1和本身外,不能被其他数整除的数。换言之,对给定的正整数n,若对任意的正整数 a(1<a<n),都有n%a != 0成立,则a时素数
- 合数:除了1和本身外,还存在至少一个能被整除的数。例如4,还能被2整除,则为合数
- 1既不是素数,也不是合数
5.4.1素数的判断
5.4.2素数表的获取
素数筛法,时间复杂度O(nloglogn)
#include<iostream>
#include<vector>
using namespace std;
const int maxN = 101;
int main(){
vector<int> primes(maxN, 1), p;
for(int i = 2; i < maxN; i++){//打印100以内的素数表
if(primes[i]){
p.push_back(i);
for(int j = i * i; j < maxN; j += i){
primes[j] = 0;
}
}
}
for(int i = 0; i < p.size(); i++){
printf("%d ", p[i]);
}
return 0;
}
5.5质因子分解
- 质因子分解:把一个正整数写为若干个质数相乘的形式
- 109 内整数本质不同质因数不会超过十个
23571113171923*29超过了int范围
- 对于一个正整数n而言,若它存在1和本身之外的因子,则一定是在sqrt(n)左右成对出现。
对于一个正整数n来说,若它存在[2, n]范围内的质因子,要么这些质因子全部小于等于sqrt(n),要么只存在一个大于sqrt(n)的质因子,而其余质因子全部小于等于sqrt(n)。
简单应用:
#include<iostream>
#include<map>
typedef long long LL;
using namespace std;
int main(){
map<LL, int> mp;
LL n, t;
int i = 1;
scanf("%lld", &n);
t = n;
for(int i = 2; i * i <= t; i++){
if(t % i == 0){
while(t % i == 0){
mp[i]++;
t /= i;
}
}
}
if(t > 1) mp[t]++;
printf("%lld=", n);
if(mp.size() != 0){
for(map<LL, int>::iterator it = mp.begin(); it != mp.end(); it++, i++){
if(it -> second == 1) printf("%lld", it -> first);
else printf("%lld^%lld", it -> first, it -> second);
if(i != mp.size()) printf("*");
}
}
else printf("%lld", n);
return 0;
}
5.6大整数运算
5.6.1大整数的存储
借助数组存储,一般逆序存储,即数组中的每一位对应整数中的每一位,其中整数的低位存储在数组的低位
为了方便获取大整数的长度,一般会定义一个int型变量记录长度和d数组组合为结构体
struct bign{
int d[1000];
int len;
bign(){//构造函数进行初始化结构体;每次定义结构体变量时,都会自动对该变量进行初始化
memset(d, 0, sizeof(d));
len = 0;
}
}
输入大整数时,一般都是先用字符串读入,再把字符串另存到bign结构体
bign change(char str[]){//输入大整数
bign b;
b.len = strlen(str);
int l = strlen(str);
for(int i = 0; i < l; i++){
b.d[i] = str[l - i - 1] - '0';//逆序存储
}
return b;
}
比较两个大整数的大小:
首先位数多的大
位数相同时,从高位至低位进行比较,同位数 数值大的更大
全部位数相同,则相等
int compare(bign b1, bign b2){//大整数变量比较大小
if(b1.len < b2.len) return -1;//b1小
else if(b1.len > b2.len) return 1;//b2小
else{
for(int i = b1.len - 1; i >= 0; i--){
if(b1.d[i] < b2.d[i]) return -1;
else if(b1.d[i] > b2.d[i]) return 1;
}
}
return 0;//相等
}
5.6.2大整数的四则运算
高精度加法
bign add(bign b1, bign b2){
bign b;
int carry = 0, i;//进位
for(i = 0; i < b1.len || i < b2.len; i++){
b.d[i] = (b1.d[i] + b2.d[i]) % 10 + carry;
carry = (b1.d[i] + b2.d[i]) / 10;
}
if(carry == 1) {
b.d[i] = 1;
b.len = i + 1;
}
else b.len = i;
return b;
}
高精度减法
使用sub函数前,需要先比较b1和b2的大小,确保b1 >= b2.换言之,当b1 < b2时,则输出负号,再交换b1,b2
bign sub(bign b1, bign b2){
bign b;
for(int i = 0; i < b1.len; i++){//确保b1 >= b2,以较长的为界限
if(b1.d[i] < b2.d[i]){//不足则借位
b1.d[i] += 10;
b1.d[i + 1]--;
}
b.d[b.len++] = b1.d[i] - b2.d[i];
}
while(b.len > 1 && b.d[i - 1] == 0){//去掉高位多余的0(有至少两位的时候才需要考虑该问题 );数组从0开始
b.len --;
}
return b;
}
高精度与低精度的乘法

如果两个乘数异号,则先记录负号,再用其绝对值带入函数
bign multi(bign b, int n){//高精度和低精度的乘法
bign ans;
int carry = 0, t;//进位
for(int i = 0; i < b.len; i++){
t = b.d[i] * n + carry;
ans.d[ans.len++] = t % 10;
carry = t / 10;
}
while(carry){//乘法进位可能不止一位
ans.d[ans.len++] = carry % 10;
carry /= 10;
}
return ans;
}
高精度与低精度的除法
bign divide(bign b, int n, int &r){//高精度和低精度的除法,r为余数(初始为0)
bign ans;
ans.len = b.len;
for(int i = b.len - 1; i >= 0; i--){//从高位开始
r = r*10 + b.d[i];//当前位数值+上一位的余数*10
if(r < n){//不够除,商0(注意够不够除,比较的是除数n)
ans.d[i] = 0;
}
else{//够除
ans.d[i] = r / n;//商(注意比较的是除数n)
r = r % n;//新的余数
}
}
while(ans.len > 1 && ans.d[ans.len - 1] == 0){//当位数至少为2位时,考虑高位是否有多余的0
ans.len--;
}
return ans;
}
简单应用
#include<stdio.h>
#include<string.h>
struct bign{
int d[1000];
int len;
bign(){
memset(d, 0, sizeof(d));
len = 0;
}
};
bign change(char str[]){//输入
bign b;
b.len = strlen(str);
int l = strlen(str);
for(int i = 0; i < l; i++){
b.d[i] = str[l - i - 1] - '0';
}
return b;
}
int compare(bign b1, bign b2){//比较
if(b1.len < b2.len) return -1;//b1小
else if(b1.len > b2.len) return 1;//b2小
else{
for(int i = b1.len - 1; i >= 0; i--){
if(b1.d[i] < b2.d[i]) return -1;
else if(b1.d[i] > b2.d[i]) return 1;
}
}
return 0;//相等
}
bign add(bign b1, bign b2){//相加
bign b;
int carry = 0, i;//进位
for(i = 0; i < b1.len || i < b2.len; i++){
b.d[i] = (b1.d[i] + b2.d[i]) % 10 + carry;
carry = (b1.d[i] + b2.d[i]) / 10;
}
if(carry == 1) {
b.d[i] = 1;
b.len = i + 1;
}
else b.len = i;
return b;
}
bign sub(bign b1, bign b2){//b1 >= b2
bign b;
for(int i = 0; i < b1.len; i++){//以较长的为界限
if(b1.d[i] < b2.d[i]){//不够减
b1.d[i] += 10;
b1.d[i+1]--;
}
b.d[b.len++] = b1.d[i] - b2.d[i];
}
while(b.len > 1 && b.d[b.len-1] == 0) b.len--;
return b;
}
bign multi(bign b, int n){//高精度和低精度的乘法
bign ans;
int carry = 0, t;//进位
for(int i = 0; i < b.len; i++){
t = b.d[i] * n + carry;
ans.d[ans.len++] = t % 10;
carry = t / 10;
}
while(carry){//乘法进位可能不止一位
ans.d[ans.len++] = carry % 10;
carry /= 10;
}
return ans;
}
bign divide(bign b, int n, int &r){//高精度和低精度的除法,r为余数(初始为0)
bign ans;
ans.len = b.len;
for(int i = b.len - 1; i >= 0; i--){//从高位开始
r = r*10 + b.d[i];//当前位数值+上一位的余数*10
if(r < n){//不够除,商0(注意够不够除,比较的是除数n)
ans.d[i] = 0;
}
else{//够除
ans.d[i] = r / n;//商(注意比较的是除数n)
r = r % n;//新的余数
}
}
while(ans.len > 1 && ans.d[ans.len - 1] == 0){//当位数至少为2位时,考虑高位是否有多余的0
ans.len--;
}
return ans;
}
int main(){
char str1[1000], str2[1000];
int n, r = 0;
scanf("%s%s%d", str1, str2, &n);
bign b1 = change(str1);
bign b2 = change(str2);
bign b = add(b1, b2);
for(int i = b.len - 1; i >= 0; i--){
printf("%d", b.d[i]);
}
printf("\n");
bign subN;
if(compare(b1, b2) < 0){
printf("-");
subN = sub(b2, b1);
}
else subN = sub(b1, b2);
for(int i = subN.len - 1; i >= 0; i--){
printf("%d", subN.d[i]);
}
printf("\n");
bign m = multi(b1, n);
for(int i = m.len - 1; i >= 0; i--){
printf("%d", m.d[i]);
}
printf("\n");
bign d = divide(b1, n, r);
for(int i = d.len - 1; i >= 0; i--){
printf("%d", d.d[i]);
}
return 0;
}
5.7扩展欧几里得算法


- 裴蜀定理(又称贝祖定理):一定存在整数x,y,满足ax + by = gcd(a, b)。例如4x + 6y = 2,有整数解x = -1, y =1。
它是判断一个不定方程是否有整数解的条件。即一个不定方程如果想要有整数解需要是系数的最大公约数或系数的最大公约数的整数倍。 - 裴蜀定理推广:一定存在整数x,y,满足ax + by = gcd(a, b)*n,其中n为整数。例如4x + 6y = 8,有整数解x = -4, y = 4
扩展欧几里得算法
ax + by = gcd(a, b)
给定两个非零整数a和b,求一组整数解(x, y),使得ax + by = gcd成立,其中gcd(a, b)表示a和b的最大公约数。
复习下欧几里得算法,总是把gcd(a,b) 转化为求解gcd(b, a %b),当b变为0时返回a,此时的a就等于gcd。即欧几里得算法结束的时候变量a中存放的是gcd,变量b中存放的是0,显然有a*1 + b * 0 = gcd成立,此时有x = 1, y = 0
int gcd(int a, int b){
if(b == 0) return a;
return gcd(b, a % b);
}
不妨利用上面欧几里得算法的过程来计算x和y。
目前已知的是递归边界成立时x=1,y=0。
当计算gc d(a, b)时,有ax1+by1=gcd成立;
而在下一步计算gcd(b, a%b)时,又有bx2+(a%b)y2=gcd成立。
==》则ax1+by1=bx2+(a%b)y2成立。
又a%b = a - (a/b)*b(此处除法为整除)
==>ax1+by1 = bx2+(a - (a/b)*b)y2
整理得ax1+by1 = ay2+b(x2-(a/b)y2)
对比等号左右两边可以得到下述递推公式
- x1 = y2
- y1 = x2 - (a/b)y2
则可以通过x2和y2来反推出x1和y1。于是只需要在达到递归边界,不断推出的过程中根据上述上式计算x和y
int exGcd(int a, int b, int &x, int &y){//x和y使用引用
if(b == 0){
x = 1;
y = 0;
return a;
}
int g = exGcd(b, a % b, x, y);//递归计算exGcd(b, a % b)
int temp = x;
x = y;
y = temp - a / b * y;
return g;
}
ax + by = c的求解
同余式ax ≡ c (mod m)的求解
首先聊下啥是同余式~对整数a、b、m来说,若m整除a-b(即(a-b)% m == 0),则a和b模m同余,对应的同余式为a ≡ b(mod m),m称为同余式的模。每一个整数都各自与[0, m)中唯一的整数同余。
a ≡ b (mod n) 表示a与b对模n同余。
“≡” 是数论中表示同余的符号,i mod j 是表示 i 对 j 取余。
即给定一个知正整数n,如果两个整数a和b满足a-b能被n整除,即(a-b)mod n=0,那么就称整数a与b对模n同余,记作a ≡ b(mod n),同时可成立a mod n=b。
在日常生活中,同余的概念是经常出现的。
例如钟表的指针,它表示的小时数是除以12同余的;若道12月1号是周日,很容易就知道12月8号、15号、22号、29号也是周日。
待处理的是同余式ax ≡ c(mod m)的求解,根据同余式的定义,有(ax - c) % m = 0

逆元的求解以及(b / a) % m的计算
先了解下何为“逆元”(此处特指乘法逆元)。假设a、b、m是整数,m > 1,且ab≡1(mod m)成立,则a和b互为模m的逆元,也记为a≡1 / b (mod m)或b≡1 / a (mod m)。换言之,若两个整数的乘积模m后等于1,则称它们互为m的逆元。
int inversse(int a, int m){
int x, y;
exGcd(a, m, x, y);
return (x % m + m) % m;//馍加馍,处理负数的情况,得到最小正整数x
}

当m是质数,且a不是m的倍数,则可直接使用费马小定理来得到逆元,无需使用扩展欧几里得算法
- 费马小定理:若m是素数,a是任意整数且a≡/0(mod m), 则am-1≡1(mod m)

六、c++标准模板库(STL)
Standard Template Library STL标准模板库
6.1vector变长数组
使用vector需要添加:
#include<vector>
using namespace std;
vector定义
其中typename可以说任意基本类型,也可以是STL标准容器,例如vector、set、queue等。注意,当typename也是STL容器时,定义时要在>>符号之间加上空格。
因为一些使用C++11之前标准的编译器会把它视为移位操作,导致编译错误。
vector<typename> name;
vector<double> name;
vector<node> name;//node是结构体的类型
//二维vector数组,可以理解为两个维都可变长的二维数组
vector<vector<int> > name;//>>之间记得加空格
vector数组的定义
其中Arrayname[0]~Arrayname[arraySize - 1]中每一个都是一个vector容器
。与vector<vector < typename> > name区别在于,该种写法的一维长度已经固定为arraySize,另一维才是变长的。
vector<typename> Arrayname[arraySize];
vector<int> vi[100];
以上定义的为空vector
vector定义并初始化:
- 定义并用n个val来初始化的vector
vector<typename> name(n, val);
vector<int> vi(10, 1);//用10个1来初始化vector
- 定义并用迭代器区间来初始化的vector
vector<int> vi1(vi.begin(), vi.end());//用vi的迭代器区间来初始化vi1
string s("you are so pretty");
vector<char> v(s.begin(), s.end());//用s的迭代器区间来初始化v
- 除了上述两种,还有三种
//一共有这五种初始化方式
(1) vector<int> a(10); //定义了10个整型元素的向量(尖括号中为元素类型名,它可以是任何合法的数据类型),但没有给出初值,其值是不确定的。
(2)vector<int> a(10,1); //定义了10个整型元素的向量,且给出每个元素的初值为1
(3)vector<int> a(b); //用b向量来创建a向量,整体复制性赋值
(4)vector<int> a(b.begin(),b.begin+3); //定义了a值为b中第0个到第2个(共3个)元素
(5)int b[7]={1,2,3,4,5,9,8};
vector<int> a(b,b+7); //从数组中获得初值
vector容器内元素的访问
1.通过下标访问
类似于普通数组,对于一个定义为vector< typename> vi的vector容器而言,直接访问vi[index]即可,其中下标index范围为[0, vi.size()-1]
注意,下面这种做法以及类似的做法都是错误的。下标只能用于获取已存在的元素,而现在的vi[i]还是空的对象
2.通过迭代器访问
所谓迭代器iterator可理解为类似指针的东东
其中,it是一个vector< typename>::iterator型的变量
vector<typename>::iterator it;
- vi.begin()函数:取vector容器vi的首元素地址
- vi.end()函数:取vector容器vi的尾元素地址的下一个地址
老外习惯:左闭右开
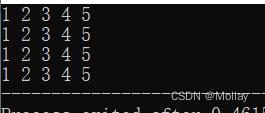
#include<stdio.h>
#include<vector>
using namespace std;
int main(){
vector<int> vi;
for(int i = 1; i < 6; i++)
vi.push_back(i);
vector<int>::iterator it = vi.begin();
for(int i = 0; i < vi.size(); i++)
printf("%d ", *(it + i));
printf("\n");
for(int i = 0; i < vi.size(); i++)
printf("%d ", *(vi.begin() + i));
printf("\n");
//vector的迭代器不支持it < vi.end()写法,则循环条件只能用it != vi.end()
//在常用STL容器中,只有vector和string中,才允许使用vi.begin()+n这种迭代器加上整数的写法
for(vector<int>::iterator i = vi.begin(); i != vi.end(); i++){//迭代器实现了自加自减操作(it++或++it)
printf("%d ", *i);//
}
printf("\n");
for(int i = 0; i < vi.size(); i++)
printf("%d ", vi[i]);//通过下标访问
return 0;
}
vector常用函数
- push_back(x) : 在vector后面添加一个元素x,时间复杂度为O(1)
- emplace_back(x)c++11新加,可以理解为实现更优雅的push_back()
- pop_back() : 删除vector的尾元素,时间复杂度为O(1)
#include<stdio.h>
#include<vector>
using namespace std;
int main(){
vector<int> vi;
for(int i = 1; i < 6; i++)
vi.push_back(i);//在vector后面插入元素i
for(int i = 0; i < vi.size(); i++)
printf("%d ", vi[i]);
vi.pop_back();//删除vector尾元素
printf("\n");
for(int i = 0; i < vi.size(); i++)
printf("%d ", vi[i]);
return 0;
}

- size() : 获得vector中元素的个数,时间复杂度为O(1)。size()返回的是unsigned类型,不过用%d一般木得问题,该点适用于所有STL容器。
- clear() : 清空vector中的所有元素,时间复杂度为O(N),其中N为vector中元素的个数
- insert(it, x) : 向vector中的任意迭代器it处插入一个元素x,时间复杂度为O(1)
- erase
- erase(it)删除迭代器为it处的元素
- erase(first, last)删除[first, last)内的所有元素
#include<stdio.h>
#include<vector>
using namespace std;
int main(){
vector<int> vi;
for(int i = 1; i < 6; i++)
vi.push_back(i);
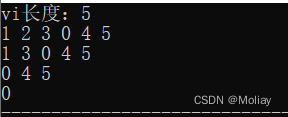
printf("vi长度:%d", vi.size());
vi.insert(vi.begin() + 3, 0);//把元素0插入到vi[3]的位置
printf("\n");
for(int i = 0; i < vi.size(); i++)
printf("%d ", vi[i]);
vi.erase(vi.begin() + 1);//删除vi[1]处的元素
printf("\n");
for(int i = 0; i < vi.size(); i++)
printf("%d ", vi[i]);
vi.erase(vi.begin(), vi.begin() + 2);//删除vi[0]到vi[1]的所有元素
printf("\n");
for(int i = 0; i < vi.size(); i++)
printf("%d ", vi[i]);
vi.clear();//清除所有元素
printf("\n%d", vi.size()); //0
return 0;
}
vector常见用途
- 作为数组使用,尤其是元素个数不确定的场合;当需要输出部分数据且中间用空格隔开而末尾不能有多余空格时,可以先用vector记录所有需要输出的数据,再一次性输出
- 用邻接表存储图
6.2set(升序、去重)
若使用set,需要添加:
#include<set>
using namespace std;
整体和vector容器非常相似,下述简化描述
set定义
set<typename> name;
set<int> name;
set<node> name;
set数组定义
set<typename> Arrayname[arraySize];
set<int> a[100];
set容器内元素的访问
set只能通过迭代器(iterator)访问元素
set<typename>::iterator it;
#include<stdio.h>
#include<set>
using namespace std;
int main(){
set<int> st;
st.insert(5);
st.insert(3);
st.insert(4);
st.insert(3);
st.insert(1);
//除了vector和string之外的STL容器都不支持*(it + i)的访问方式,则只能按照如下方式枚举
for(set<int>::iterator it = st.begin(); it != st.end(); it++){//同vector,不支持it < st.end()的写法
printf("%d ", *it);
}
return 0;
}
set常用函数
- insert(x) : 把x插入set容器中,且自动增序和去重,时间复杂度O(logN),其中N是set内的元素个数
- find(value) : 返回set中对应值为value的迭代器,时间复杂度为O(logN),N为set内的元素个数
- erase()
- erase(it) : it是所需要删除元素的迭代器,时间复杂度为O(1)。可以结合find()函数来使用
- erase(value) : value是所需要删除的元素的值,时间复杂度为O(logN),N为set内的元素个数
- erase(first, last)删除区间[ first, last)内的所有元素,时间复杂度为O(last - first)
- size() : 获得set内的元素个数,时间复杂度为O(1)
- clear() : 清空set中的所有元素,时间复杂度为O(N),其中N为set内元素的个数
#include<stdio.h>
#include<set>
using namespace std;
int main(){
set<int> st;
st.insert(5);//set(x)把元素x插入到set容器中,且自动实现增序和去重
st.insert(3);
st.insert(4);
st.insert(3);
st.insert(1);
for(set<int>::iterator it = st.begin(); it != st.end(); it++){
printf("%d ", *it);
}
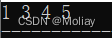
set<int>::iterator it = st.find(3);//find(value) 返回set中对应值为value的迭代器
printf("\n%d\n", *it); //3
//erase(it) 其中it是要删除元素的迭代器
st.erase(it);//先利用find()函数找到3,再用erase()删除
for(set<int>::iterator it = st.begin(); it != st.end(); it++){
printf("%d ", *it);
}
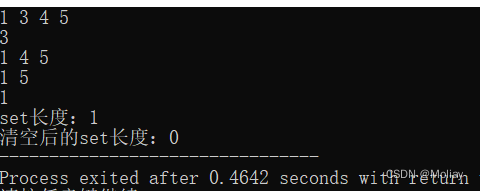
//erase(value) 其中value是要删除元素的值
st.erase(4);//删除set中值为4的元素
printf("\n");
for(set<int>::iterator it = st.begin(); it != st.end(); it++){
printf("%d ", *it);
}
//erase(first, last)删除区间[ first, last)内的所有元素
st.erase(st.find(5), st.end());//删除元素5到set末尾之间的所有元素
printf("\n");
for(set<int>::iterator it = st.begin(); it != st.end(); it++){
printf("%d ", *it);
}
//size() 返回set内的元素个数
printf("\nset长度:%d", st.size());
//clear() 清空set中的所有元素
st.clear();
printf("\n清空后的set长度:%d", st.size());
return 0;
}
set常见用途
set最主要的作用就是自动去重且按升序排序
6.3string字符串
使用string,需要添加:
#include<string>
using namespace std;
string定义
定义string的方式跟基本数据类型相同,直接在string后跟变量名即可
string str;
若初始化,可以直接给string类型的变量进行赋值
string str = "harder";
string中内容的访问
- 通过下标访问
一般而言,可以直接像字符数组那样去访问string
#include<stdio.h>
#include<string>
using namespace std;
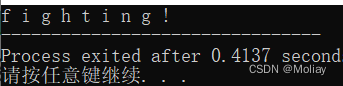
int main(){
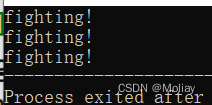
string str = "fighting!";
for(int i = 0; i < str.length(); i++){
printf("%c ", str[i]);
}
return 0;
}
读入和输出整个字符串
#include<iostream>
#include<string>
using namespace std;
int main(){
string str;
cin>>str;
cout<<str;
printf("\n%s", str.c_str());
return 0;
}
- 通过迭代器访问
一般情况下用下标进行访问即可,但有些函数比如insert()和erase()要求以迭代器为参数,需要了解string迭代器的用法
string::iterator it;
#include<stdio.h>
#include<string>
using namespace std;
int main(){
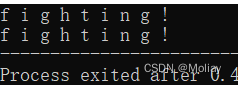
string str = "fighting!";
for(string::iterator it = str.begin(); it != str.end(); it++){
printf("%c ", *it);
}
printf("\n");
for(int i = 0; i < str.length(); i++){
//string和vector一样,支持直接对迭代器进行加减某个数字
printf("%c ", *(str.begin() + i));
}
return 0;
}
string常用函数
- += :把两个string直接拼接起来
#include<iostream>
#include<string>
using namespace std;
int main(){
string str1 = "fighting,", str2 = "blue!";
str1 += str2;//fighting,blue!
str2 += str2;//blue!blue!
cout<<str1<<endl;
printf("%s", str2.c_str());
return 0;
}
- 比较操作==、!=、<、<=、>、>= : 比较规则是字典序
#include<iostream>
#include<string>
using namespace std;
int main(){
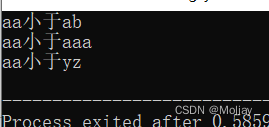
string str1 = "aa", str2 = "ab", str3 = "aaa", str4 = "yz";
if(str1 < str2) printf("%s小于%s\n", str1.c_str(), str2.c_str());
if(str1 < str3) printf("%s小于%s\n", str1.c_str(), str3.c_str());
if(str1 < str4) printf("%s小于%s\n", str1.c_str(), str4.c_str());
return 0;
}
- length()/size() : 返回string的长度
- insert()
- insert(pos, string) 在pos号位置上插入字符串string(pos从0开始
#include<iostream>
#include<string>
using namespace std;
int main(){
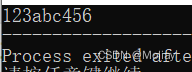
string str = "123456";
str.insert(3, "abc");
cout<<str;
return 0;
}
- insert()续
- insert(it, it1, it2) : 串[ it1, it2)将会插在it的位置上
#include<iostream>
#include<string>
using namespace std;
int main(){
string str = "123456", str1 = "abcdef";
str.insert(str.begin() + 3, str1.begin(), str1.begin() + 3);
cout<<str;
return 0;
}
- erase()
- erase(it) : 用于删除单个元素,其中it是需要删除的元素的迭代器
- erase(first, last) : 删除区间[first, last)内的所有元素
- erase(pos, length) : 删除从pos开始,length个字符
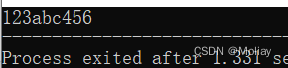
#include<iostream>
#include<string>
using namespace std;
int main(){
string str = "123456", str1 = "abcdef";
//erase(it) 删除单个元素
str.erase(str.begin() + 1); //13456 即删除1号位置的元素(位置从0开始)
cout<<str<<endl;
//erase(first, last) 删除区间[first, last)内的所有元素
str.erase(str.end() - 3, str.end());//13
cout<<str<<endl;
//erase(pos, length) 删除从pos开始的length个字符
str1.erase(3, 3);//abc 即删除从3号位开始的3个字符
cout<<str1;
return 0;
}
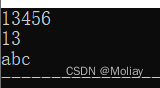
- clear() : 清空string中的数据
- substr(pos, len) : 返回从pos位置开始,长度为len的子串,时间复杂度为O(len)
#include<iostream>
#include<string>
using namespace std;
int main(){
string str1 = "abcdef123", str2;
str2 = str1.substr(6, 3);
cout<<str2<<endl;//123
str1.clear();
cout<<str1.size();//0
return 0;
}
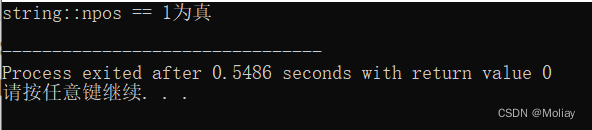
- string::npos 是一个常数,本身的值是-1,但由于是unsigned_int类型,则也可以认为是unsigned_int类型的最大值。string::pos是find()函数失配时的返回值。
#include<iostream>
#include<string>
using namespace std;
int main(){
// unsigned int n = -1;
// cout<<n<<endl;
if(string::npos == -1) cout<<"string::npos == 1为真"<<endl;
// if(string::npos == n) printf("string::npos == %u为真", n);
// else cout<<"err";
//[Warning] this decimal constant is unsigned only in ISO C90
if(string::npos == 4294967295) printf("string::npos == 4294967295为真");
return 0;
}
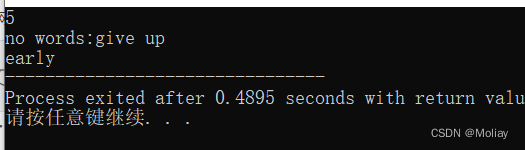
- find()
- str.find(str1) :
- 当str1是str的子串时,返回其在str中第一次出现的位置;
- 当str1不是str的子串时,返回string::npos
- str.find(str1, pos) : 从str的pos号位开始匹配str1,返回值和上个函数相同
- str.find(str1) :
#include<iostream>
#include<string>
using namespace std;
int main(){
string str1 = "fighting, blue!", str2 = "ing", str3 = "give up";
if(str1.find(str2) != string::npos) cout << str1.find(str2) << endl;
if(str1.find(str3) != string::npos) cout << str1.find(str3) << endl;
else printf("no words:%s\n", str3.c_str());
if(str1.find(str2, 6) != string::npos) cout << str1.find(str2, 6) << endl;
else cout<<"early";
return 0;
}
- replace() 时间复杂度为O(str.length())
- str.replace(pos, len, str1) : str从pos号位开始、长度为len的子串替换为str1
- str.replace(it1, it2, str1) : 把str的迭代器[it1, it2)范围的子串替换为str1
#include<iostream>
#include<string>
using namespace std;
int main(){
string str = "1234567890", str1 = "abc", str2 = "DEF";
cout << str.replace(3, 3, str1) << endl;//123abc7890
cout << str.replace(str.begin() + 6, str.begin() + 7, str2);//123abcDEF890 位置不够也会把str2替换
return 0;
}

6.4map键值对
若map使用,需要添加:
#include<map>
using namespace std;
map可以把任何基本类型(包括STL容器)映射到任何基本类型(包括STL容器)
map定义
定义一个map,其中前类型为key类型,后类型为value类型
map<typename1, typename2> mp;
当int型映射到int型,也就相当于普通的int型数组了。
注意当字符串到整型的映射时,必须使用string而不能使用char数组。
因为char数组作为数组,是不能被作为键值的。若想用字符串做映射,必须用string。
map<string, int> mp;
map<set<int>, string> mp;//map的键和值也可以是STL容器
map中内容的访问
- 通过下标进行访问
和普通数组的访问同理,例如对一个定义为map<char, int> mp的map来说,就可以直接使用mp[‘c’]的方式来访问它对应的整数。注意,map中的键是唯一的。
#include<iostream>
#include<map>
using namespace std;
int main(){
map<char, int> mp;
mp['a'] = 1;
mp['a'] = 2;//更新,因为键是唯一的
printf("%d", mp['a']);//2
return 0;
}
- 通过迭代器访问
map可使用it->first来访问键,使用it->second来访问值。map会以键从小到大的顺序自动排序
因为map内部使用红黑树实现(set也是),在建立映射的过程中会自动实现从小到大的排序功能
map<typename1, typename2>::iterator it;
#include<iostream>
#include<map>
using namespace std;
int main(){
map<char, int> mp;
mp['c'] = 4;
mp['a'] = 2;
mp['b'] = 5;
for(map<char, int>::iterator it = mp.begin(); it != mp.end(); it++){
printf("%c : %d\n", it->first, it->second);
}
return 0;
}

map常见函数
- find(key) : 返回键为key的映射的迭代器,时间复杂度O(logn),n是
#include<iostream>
#include<map>
using namespace std;
int main(){
map<char, int> mp;
mp['b'] = 4;
mp['a'] = 1;
mp['c'] = 3;
//find(key)返回键为key的映射的迭代器
//小复习:map可以使用it -> first访问键, it -> second访问值
map<char, int>::iterator it = mp.find('a');
printf("%c %d", it -> first, it -> second);//a 1
return 0;
}
- erase()
- erase(it) : it是要删除元素的迭代器,时间复杂度为O(1)
- erase(key) : key是要删除的映射的键,时间复杂度为O(logN)
- erase(first, last) : 删除区间[ first, last)内的元素。其中first是要删除区间的起始迭代器,last是要删除的区间的末尾迭代器的下一个地址。
#include<iostream>
#include<map>
using namespace std;
int main(){
map<char, int> mp;
mp['b'] = 4;
mp['a'] = 1;
mp['c'] = 3;
mp['d'] = 2;
mp['y'] = 4;
mp['x'] = 1;
mp['z'] = 3;
mp['o'] = 2;
for(map<char, int>::iterator it = mp.begin(); it != mp.end(); it++){
printf("%c %d, ", it -> first, it -> second);
}
printf("\n");
map<char, int>::iterator it = mp.find('a');
//mp.erase(it) it是要删除元素的迭代器
mp.erase(it);
mp.erase(mp.find('d'));
//mp.erase(key) key是要删除的映射的键
mp.erase('c');
//mp.erase(first, last)删除区间[first, last)区间内的元素
//注意,这里的迭代器不能用mp.begin()或者mp.end()加整数
//string和vector才支持对迭代器进行加减某个数字,例如str.begin()+3
mp.erase(mp.find('x'), mp.end());
for(map<char, int>::iterator it = mp.begin(); it != mp.end(); it++){
printf("%c %d, ", it -> first, it -> second);
}
printf("\n");
return 0;
}
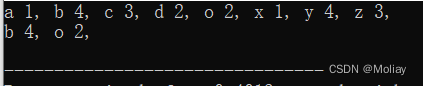
- count(key) : 判断键值元素是否存在,若存在返回1,不存在返回0
- size() : 返回的是map中映射的对数,时间复杂度O(1)
- clear() : 清空map中的所有元素,复杂度为O(n),其中N为map中元素的个数
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main(){
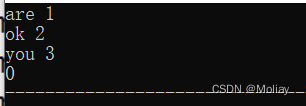
map<string, int> mp;
mp["are"] = 1;
mp["you"] = 3;
mp["ok"] = 2;
for(map<string, int>::iterator it = mp.begin(); it != mp.end(); it++)
printf("%s %d\n", it -> first.c_str(), it -> second);
//mp.clear() 清空mp中的所有元素
mp.clear();
//mp.size() 返回mp中的映射对数
printf("%d", mp.size());
return 0;
}
#include<iostream>
#include<queue>
#include<map>
#include<string>
#include<algorithm>
using namespace std;
string begin, end, t;
map<string, int> mp;
int n, d, k, x, y;
int X[4] = {-1, 1, 0, 0};
int Y[4] = {0, 0, -1, 1};//上 下 左 右
int bfs(string s){
queue<string> q;//辅助队列
q.push(s);//初始状态入队
while(!q.empty()){
t = q.front();//访问队首元素
q.pop();//队首元素出队
if(t == end) return mp[t];//首次到达目标状态 ,得到最少操作次数
k = t.find('0');//找到空位置0在状态串中的位置
for(int i = 0; i < 4; i++){
x = k / 3 + X[i];//一维坐标转二维坐标
y = k % 3 + Y[i];
if(x < 0 || x >= 3 || y < 0 || y >= 3) continue;//非法坐标
d = mp[t];
swap(t[k], t[x * 3 + y]);//交换
if(!mp.count(t)) {//确保无重复操作 ,若已存在字符串t,则返回1;若不存在返回0
mp[t] = d + 1;
q.push(t);//把该状态入队
}
swap(t[k], t[x * 3 + y]); //还原,以判断下一个相邻变换
}
}
}
int main(){
cin >> begin;
end = "123804765";
cout << bfs(begin);
return 0;
}
map常见用途
- 需要建立字符(字符串)与整数之间映射的题目,可以使用map减少代码量
- 判断大整数或者其他类型数据是否存在的题目,可以把map当bool数组用
- 字符串和字符串的映射也有可能会遇到
unordered_map
若使用需添加
#include <unordered_map>
using namespace std;
- unordered_map是一个将key和value关联起来的容器,它可以高效的根据单个key值查找对应的value。
- key值应该是唯一的,key和value的数据类型可以不相同。
- unordered_map存储元素时是没有顺序的,只是根据key的哈希值,将元素存在指定位置,所以根据key查找单个value时非常高效,平均可以在常数时间内完成。
- unordered_map查询单个key的时候效率比map高,但是要查询某一范围内的key值时比map效率低。
- 可以使用[]操作符来访问key值对应的value值。
6.5queue队列
queue定义
若用queue,需添加
#include<queue>
using namespace std;
queue<typename> name;//typename可以是任意基本数据类型或容器
queue中内容的访问
队列本身是限制性(先进先出)的线性结构,只能用front()来访问队首元素,用back()来访问队尾元素,两者及其下面常用函数时间复杂度皆为O(1)
queue常见函数
- push(x) : 把x进行入队尾
- pop():队首元素出队
- empty():检查queue是否为空,空返回true,非空返回false
- size():返回queue内元素的个数
#include<iostream>
#include<queue>
using namespace std;
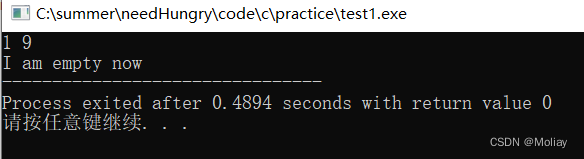
int main(){
queue<int> q1, q2;
for(int i = 1; i < 10; i++){
q1.push(i);
}
//使用front()和pop()函数, back()前,必须用empty()判断队列是否为空!先问有木有,再问是哪位
if(!q1.empty()) printf("%d %d\n", q1.front(), q1.back());
if(q2.empty()) printf("I am empty now");
return 0;
}
queue常见用途
实现DFS时,直接使用即可,无需再手动实现。
6.6priority_queue优先队列
priority_queue又称为优先队列,底层使用堆来实现的。在优先队列中,队首元素一定是当前队列中优先级最高的那个小伙。
若使用priority_queue,要添加
#include<queue>
using namespace std;
priority_queue定义
priority_queue<typename> name;// typename可以是任意基本数据类型或容器
priority_queue内元素的访问
只能通过top()函数来访问队首元素(也称为堆顶元素),即优先级最高的元素。时间复杂度为O(1)。
注意使用top()函数前,要先判断队列是否为空
priority_queue常见函数
- push(x) : 把x入队,时间复杂度为O(logN),其中N为当前优先队列中的元素个数。
可以在任意时间把元素加入(push)到优先队列中,优先队列底层的数据结构堆(heap)会随时调整结构,使得每次的队首元素都是优先级最大的。
- pop() : 把队首元素(即堆顶元素)出队,时间复杂度为O(logN)
- empty() : 检查优先队列是否为空,空则返回true, 非空返回false。时间复杂度为O(1)
- size() : 返回优先队列内元素的个数,时间复杂度为O(1)
#include<iostream>
#include<queue>
using namespace std;
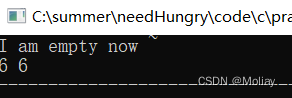
int main(){
priority_queue<int> q;
if(q.empty()) printf("I am empty now ~ \n");
for(int i = 1; i < 10; i++){
q.push(i);
}
for(int i = 1; i <= 3; i++){
q.pop();
}
printf("%d %d", q.top(), q.size());
return 0;
}
priority_queue内元素优先级的设置
基本数据类型的优先级设置
这里的基本数据类型是int型、double型、char型等可以直接使用的数据类型,一般优先级位置为数字大的优先级更高。则对于基本数据类型来说,下面两种优先队列的定义是等价的:
priority_queue<int> q;
priority_queue<int, vector<int>, less<int> > q;//老规矩,记得加空格,否则编译时会识别为右移运算啦
第二种定义方式的尖括号内多出的两个参数:
- 第二个参数vector< int > 是来承载底层数据结构堆(heap)的容器。其中第一个参数是double或char型则相应的填写vector< double>或vector< char>
- 第三个参数less< int>是堆第一个参数的比较类
- less< int>表示数字大的优先级越大(less是增序,greater是降序)
- greater< int>表示数字小的优先级越大
#include<iostream>
#include<queue>
using namespace std;
int main(){
priority_queue<int, vector<int>, greater<int> > q;
q.push(3);
q.push(4);
q.push(2);
q.push(5);
printf("%d %d", q.top(), q.size());
return 0;
}
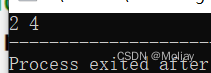
基本数据类型的优先级设置
以结构体靓仔为例
struct handsome{
string name;
int score;
};
若按照靓仔的分数高的为优先级高,则需要重载(overload)小于号"<"。重载是指对已有的运算符进行重新定义。
struct handsome{
string name;
int score;
friend bool operator< (handsome h1, handsome h2) {
return h1.score < h2.score;
}
};
上述可见靓仔结构体增加了一个函数
- "friend"是友元,简单了解皆可。
- "bool operator < (handsome h1, handsome h2)“对handsome类型的操作符”<“进行了重载(重载大于号会编译错误,从数学上来说只需要重载小于号,而h1 > h2等价于判断 h2 < h1,h1 == h2等价于判断!(h1 < h2) && !(h2 < h1),函数内部为"return h1.score < h2. score”。此时可以直接定义handsome类型的优先队列,其内部就是以价格高的水果为优先级高。
为了满足喜欢在垃圾堆找人的群体需求,若想要以分数低的靓仔为优先级高,只需把return 中的小于号改为大于号即可
struct handsome{
string name;
int score;
friend bool operator< (handsome h1, handsome h2) {
return h1.score > h2.score;
}
};
之前在排序函数sort中的cmp函数和小于号的重载有点子像
- 参数都是两个变量
- 函数内部都是返回true或false
两者的不同之处在于它们的效果相反。
#include<iostream>
#include<queue>
using namespace std;
struct handsome{
string name;
int score;
friend bool operator < (handsome h1, handsome h2){
return h1.score > h2.score;
}
}h[3];
int main(){
priority_queue<handsome> q;
for(int i = 0; i < 3; i++){
cin >> h[i].name >> h[i].score;
q.push(h[i]);
}
if(!q.empty()) cout << q.top().name << " " << q.top().score;
return 0;
}
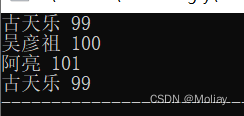
priority_queue常见用途
栈是受限的线性数据结构,后进先出
解决贪心问题或堆迪杰斯特拉算法进行优化时,皆可使用。
6.7stack栈
若使用stack,需添加:
#include<stack>
using namespace std;
stack定义
stack<typename> name;//typename可以是任意基本数据类型或容器
stack容器内元素的访问
STL中的stack只能通过top()来访问栈顶元素
stack常用函数
- push(x) : 把x入栈,时间复杂度O(1),下同
- pop() : 弹出栈顶元素
- empty() : 检查stack内是否为空,为空返回true,非空返回false
- size() : 返回stack内元素的个数
#include<iostream>
#include<stack>
using namespace std;
int main(){
stack<int> st;
for(int i = 1; i <= 9; i++){
st.push(i);
}
for(int i = 1; i < 4; i++){
st.pop();
}
if(!st.empty()) {
printf("I have %d elements\n", st.size());
printf("%d", st.top());
}
return 0;
}
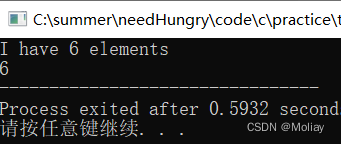
stack常见用途
模拟递归的实现,防止程序对栈内存的限制而导致程序运行错误。
6.8pair
若用pair,需添加:
#include<map>
using namespace std;
或
#include<utility>
using namespace std;
由于map的内部实现中设计pair,则添加mao头文件会自动添加utility头文件,故可以直接偷懒用map头文件来代替utility头文件,好记~
pair定义
pair有俩参数,分别对应first和second的数据类型,它们可以是任意基本数据类型或容器
pair<typename1, typename2> name;
pair<string, int> p;
若在定义pair时进行初始化,只需跟上一个小括号,里面填写两个想要初始化的元素即可
pair<string, int> p("harder", 1);
若想要在代码中临时构建一个pair,有如下两种方法
- 把类型定义写在前面,后面用小括号内两个元素的方式
pair<string, int>("blue", 2)
- 使用自带的make_pair函数
make_pair("first", 1)
pair中元素的访问
pair中只有两个元素,分别是first和second,只需要按正常结构体的方式去访问即可
#include<iostream>
#include<map>
using namespace std;
int main(){
pair<string, int> p;
p.first = "fighting";
p.second = 1;
cout << p.first << " " << p.second << endl;
p = pair<string, int>("coming", 1);
cout << p.first << " " << p.second << endl;
p = make_pair("harder", 111);
cout << p.first << " " << p.second;
return 0;
}
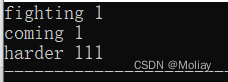
pair常用函数
两个pair类型数据可以直接使用== , !=, < , <= , >, >=比较大小。
- 比较规则:先以first的大小作为标准,只有当first相等时才去判别second的大小
#include<iostream>
#include<map>
using namespace std;
int main(){
pair<int, int> p1(3, 1);
pair<int, int> p2(3, 2);
pair<int, int> p3(2, 3);
if(p1 < p2) cout << p1.first << " " << p1.second << "小于" << p2.first << " " << p2.second << endl;
if(p1 > p3) cout << p1.first << " " << p1.second << "大于" << p3.first << " " << p3.second;
return 0;
}

pair常见用途
- 用来替代二元结构体及其构造函数,可以节省编码时间
- 作为map键值对来进行插入
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main(){
map<string, int> mp;
//mp.insert("that", 4);报错
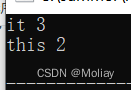
mp.insert(pair<string, int>("this", 2));
mp.insert(make_pair("it", 3));
for(map<string, int>::iterator it = mp.begin(); it != mp.end(); it++){
cout << it->first << " " << it->second << endl;
}
return 0;
}
6.9 algorithm头文件下的常用函数
若使用algorithm头文件,需要在头文件下添加
using namespace std;
6.9.1 max(), min()和 abs()
- max(x, y) 返回x和y中的最大值(且参数必须是两个,可以是浮点数)
- min(x, y) 返回x和y中的最小值
- abs(x) 返回x的绝对值
#include<iostream>
#include<algorithm>
using namespace std;
int main(){
int x, y, z;
cin >> x >> y >> z;
cout << max(x, y) << endl;
cout << max(x, max(y, z)) << endl;
cout << min(x, y) << endl;
cout << abs(x) << endl;
cout << fabs(x);
return 0;
}
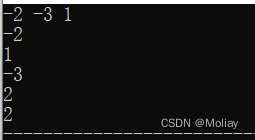
#include<iostream>
#include<algorithm>
using namespace std;
int main(){
// int x, y, z;
double x = -1, y = -3, z = -2;
// cin >> x >> y >> z;
cout << max(x, y) << endl;
cout << max(x, max(y, z)) << endl;
cout << min(x, y) << endl;
cout << abs(x) << endl;
cout << fabs(x);
return 0;
}
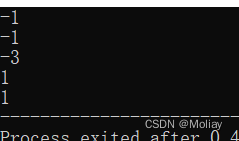
- swap(x, y) 交换x和y的值
- reverse(it1, it2) 把[ it1, it2)之间的元素或容器的迭代器在该范围内反转
#include<iostream>
#include<algorithm>
#include<string>
using namespace std;
int main(){
string str = "abcdefg";
int a[10] = {1, 2, 3, 4, 5};
swap(a[0], a[1]);
reverse(a + 2, a + 5);
for(int i = 0; i < 5; i++){
printf("%d ", a[i]);
}
reverse(str.begin(), str.begin() + 4);
cout << endl << str;
return 0;
}
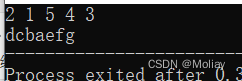
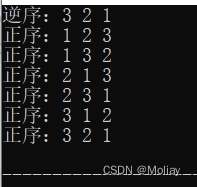
- next_permutation(first, last) : 给出一个序列在[first, last]范围内全排列中的下一个序列

next_permutation在已经到达全排列的最后一个时会返回false。使用do…while语句是为了输出最有一组序列后再退出。
#include<iostream>
#include<algorithm>
using namespace std;
int main(){
int a[5] = {3, 2, 1}, b[5] = {1, 2, 3};
do{
printf("逆序:%d %d %d\n", a[0], a[1], a[2]);
}while(next_permutation(a, a + 3));
do{
printf("正序:%d %d %d\n", b[0], b[1], b[2]);
}while(next_permutation(b, b + 3));
return 0;
}
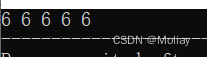
- fill(first, last, value) : 把[first, last]区间内皆赋值为value
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int main(){
vector<int> vi;
for(int i = 1; i < 6; i++)
vi.push_back(i);
fill(vi.begin(), vi.end(), 6);
for(int i = 0; i < 5; i++)
cout << vi[i] << " ";
return 0;
}
6.9.6sort()
sort()使用
- 需要加
#include<algorithm>和using namespace std;
sort(首元素地址,尾元素地址的下一个地址, 比较函数(选填));
若比较函数不填,默认从小到大(序列元素一定要有可比性)(对于char型数组默认为字典序)对于结构体这种本身没有大小关系,需要手动制定比较规则。
①整型数组
#include<cstdio>
#include<algorithm>
using namespace std;
int main(){
int a[6] = {9, 4, 2, 5, 6, -1};
sort(a, a + 4);//默认从小到大
for(int i = 0; i < 6; i++){
printf("%d ", a[i]);//2 4 5 9 6 -1
}
printf("\n");
sort(a, a + 6);
for(int i = 0; i < 6; i++){
printf("%d ", a[i]);//-1 2 4 5 6 9
}
return 0;
}
②char型数组
#include<cstdio>
#include<algorithm>
using namespace std;
int main(){
char c[] = "harder";
sort(c, c + 6);
for(int i = 0; i < 6; i++) printf("%c ", c[i]);
return 0;
}
实现比较函数
(1)基本数据类型数组的排序
从大到小a>b
①整型数组
#include<cstdio>
#include<algorithm>
using namespace std;
bool cmp(int a, int b){
return a > b;
}
int main(){
int a[6] = {9, 4, 2, 5, 6, -1};
sort(a, a + 4, cmp);//默认从小到大
for(int i = 0; i < 6; i++){
printf("%d ", a[i]);//9 5 4 2 6 -1
}
printf("\n");
sort(a, a + 6, cmp);
for(int i = 0; i < 6; i++){
printf("%d ", a[i]);//9 6 5 4 2 -1
}
return 0;
}
②字符型数组
#include<cstdio>
#include<algorithm>
using namespace std;
bool cmp(char a, char b){
return a > b;
}
int main(){
char c[] = "harder";
sort(c, c + 6, cmp);
for(int i = 0; i < 6; i++) printf("%c ", c[i]);//r r h e d a
return 0;
}
(2)结构体数组的排序
以该结构体为例:
struct node{
int x, y;
}ssd[10];
- 一级排序
以ssd数组按照x从大到小排序
bool cmp(node a, node b){
return a.x > b.x;
}
- 二级排序
以ssd数组先按x从大到小排序;当x相等时,按照y从小到大排序
bool cmp(node a, node b){
if(a.x != b.x) return a.x > b.x;
else return a.y < b.y;
}
(3)容器的排序
在STL标准容器中,只有vector,string,deque可以使用sort
对于像set,map这种容器是用红黑树实现的,元素本身有序,则不运行使用sort排序
//以vector为例
#include <stdio.h>
#include <vector>
#include <algorithm>
using namespace std;
bool cmp(int a, int b){//vector中的元素为int型,则仍然是int的比较
return a > b;
}
int main(){
vector<int > vi;
vi.push_back(3);
vi.push_back(2);
vi.push_back(4);
sort(vi.begin(), vi.end(), cmp);//对整个vector排序
for(int i = 0; i < 3; i++)
printf("%d ", vi[i]);//4 3 2
return 0;
}
//以string按字典序从小到大输出为例
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
int main(){
string str[3] = {"better", "a", "person"};
sort(str, str + 3);//把string型数组按照字典序从小到大输出
for(int i = 0; i < 3; i++)
cout<<str[i]<<endl; //a better person
return 0;
}
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
bool cmp(string str1, string str2){
return str1.length() < str2.length();//按string的长度从小到大排序
}
int main(){
string str[3] = {"better", "a", "person"};
sort(str, str + 3, cmp);//把string型数组按照字典序从小到大输出
for(int i = 0; i < 3; i++)
cout<<str[i]<<endl; //a better person
return 0;
}
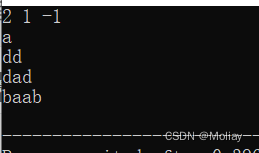
简单应用
#include<iostream>
#include<vector>
#include<string>
#include<algorithm>
using namespace std;
bool cmp1(int a, int b){
return a > b;
}
bool cmp2(string s1, string s2){
return s1.length() < s2.length();
}
int main(){
vector<int> vi;
vi.push_back(2);
vi.push_back(-1);
vi.push_back(1);
sort(vi.begin(), vi.end(), cmp1);
for(vector<int>::iterator it = vi.begin(); it != vi.end(); it++)
cout << *it << " ";
string str[5] = {"dd", "dad", "a", "baab"};
sort(str, str + 5, cmp2);
for(int i = 0; i < 5; i++)
cout << str[i] << endl;
return 0;
}
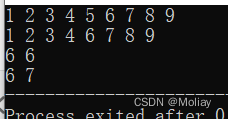
6.9.7 lower_bound() 大于等于 && upper_bound() 大于
- lower_bound(first, last, val) : 返回在数组或容器中的[first, last)范围内第一个值大于等于val元素的数组位置或容器迭代器
- upper_bound(first, last, val) : 返回在数组或容器中的[ first, last)范围内第一个值大于val元素的数组位置或容器迭代器
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int main(){
vector<int> vi;
for(int i = 1; i < 10; i++)
vi.push_back(i);
for(int i = 0; i < vi.size(); i++)
printf("%d ", vi[i]);
printf("\n");
vi.erase(vi.begin() + 4);
for(int i = 0; i < vi.size(); i++)
printf("%d ", vi[i]);
printf("\n");
printf("%d %d", *lower_bound(vi.begin(), vi.begin() + 10, 5), *upper_bound(vi.begin(), vi.begin() + 10, 5));
printf("\n");
printf("%d %d", *lower_bound(vi.begin(), vi.begin() + 9, 6), *upper_bound(vi.begin(), vi.begin() + 9, 6));
return 0;
}















 1359
1359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









