







MongoDB是由C++语言编写的非关系数据库,也是一个基于分布式文件存储的开源数据库系统。它是NoSQL文档存储数据库的重要一员,也是该领域中最热门的一种产品(总排名为第五),迄今为止,已经涵盖100余个国家和地区,平台下载量超过3.65亿次。
分布式文件存储:传统的存储方式也称为集中式存储,指的是整个存储集中在一个系统(但不是单独的设备)之中。其最大的特点是所有数据都需要经过一个统一的入口(机头)。而分布式存储最早由谷歌提出,目的是通过廉价的服务器来提供使用,缓解大规模、高并发场景下的web访问问题。其采用可拓展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息。
目录
前言
本文主要记录自己的学习历程,跟随笔者自身的学习进度更新,除了将课上讲师的知识点整理以外,便是通过网络等资源进行知识的补充和拓展,最终汇总成文章内容。其中可能碍于笔者自身实力的原因,会出现一些知识的错误或纰漏等,还请海涵。
什么是NoSQL?
我们都知道近些年大数据、云计算等技术快速发展,互联网企业对海量的数据存储和并发访问要求越来越高,传统类型的关系数据库由于ACID原则、结构规整以及表连接操作等特性而不能满足人们的需求。
ACID原则中,A指原子性(Atomicity),一个事务要么全部执行,要么不执行;C指一致性(Consistency),确保事务更改与关系数据库约束一致;I指隔离性(Isolation),事务间互不影响;D指持久性(Durability),事务执行成功后,其所作的更改将持久保存在数据库中而不会无故回滚。
而NoSQL数据库就是为解决这一问题而诞生的,对NoSQL最普遍的解释是“非关系型的”,主要强调键值对存储和文档存储的优点,而非反对关系数据库。事实上,二者并非孰优孰劣
NoSQL和SQL的区别?
| 关系数据库 | 非关系数据库 | |
|---|---|---|
| 存储方式 | 表 | 数据集 |
| 存储结构 | 结构化 | 动态结构 |
| 存储规范 | 最小数据表 | 平面数据集 |
| 扩展方式 | 一定程度的垂直和水平扩展 | 水平扩展 |
| 查询方式 | SQL | UnQL |
| 规范化 | 规范 | 非规范 |
| 事务性 | ACID | BASE |
| 读写性能(面对海量数据) | 较低 | 较高 |
| 授权方式 | 非开源 | 开源 |
存储方式
关系数据库采用表的格式、数据采用行和列的格式进行存储,稳定性高,读取和查询都十分方便,但随着表的数量增加,管理会愈发困难。
非关系数据库以数据集的方式进行存储,便于修改,也非常灵活。
存储结构
关系数据库按照结构化的方法存储数据。如此一来,数据表的可靠性和稳定性都比较高,但是修改数据表的结构就会显得异常困难。
非关系数据库采用的是动态结构存储数据。面对大量非结构化数据的存储,它可以非常轻松地适应数据类型和结构的改变。
存储规范
关系数据库将数据都按照最小关系表的形式进行存储。避免了重复存储,充分利用了存储空间。但随着表的数量增加,管理会越来越复杂。
非关系数据库则是用平面数据集的方式集中存放。尽管会出现数据被重复存储造成存储空间的浪费,但这对数据的读写提供了极大的便利。
扩展方式
如上述,关系数据库将数据存储在数据表中,在进行多张表的操作时,会出现I/O瓶颈,要解决这个问题,只能提升设备,提高处理能力。并且由于可扩展的空间是有限的,所以,即使扩展空间,问题也无法得到有效解决。
非关系数据库由于存储是分布式的,所以可以采用水平扩展方式扩展数据库,通过增加服务器来分担数据量增加带来的I/O开销。
查询方式
关系数据库是采用结构化查询语言(SQL)来对数据库进行查询。SQL支持数据库CRUD操作(增加、读取、更新、删除),具有非常强大的功能。
非关系数据库使用的是非结构化查询语言(UnQL)。UnQL以数据集为单位来管理和操作数据。
规范化
关系数据库中,一个数据实体被分为多个部分,再对这些部分进行规范化操作,然后再存储到多张关系表中。这个复杂过程得到一些平台提供的解决办法,例如ORM层(对象关系映射)将数据库中的对象模型映射到基于SQL的关系数据库中,或者对不同类型系统的数据进行转换。
非关系数据库没有上述问题,不需要规范化数据,它通常是再一个单独的存储单元中存储一个复杂的数据实体。
事务性
关系数据库强调ACID原则。可满足事务性要求较高或者需要进行复杂数据查询的数据操作,也可充分满足数据库操作的高性能和稳定性的要求。
非关系数据库强调BASE理论。其减少了对强一致性的支持,不能很好的支持事务操作。
读写性能
关系数据库强调数据的一致性,为此降低了数据的读写性能。当面对海量数据时,其效率会变得很低,尤其是遇到高并发读写,性能会很快下降。
非关系数据库是以数据集的方式进行存储的,因此扩展和读写都非常容易。
授权方式
关系数据库,除了MySQL,像是Oracle、SQL Server等都是非开源的,若要使用需要高昂的费用。
非关系数据库,像MongoDB、Redis、HBase等都是开源的,使用非企业版时无需费用。
NoSQL的基础理论
CAP原则
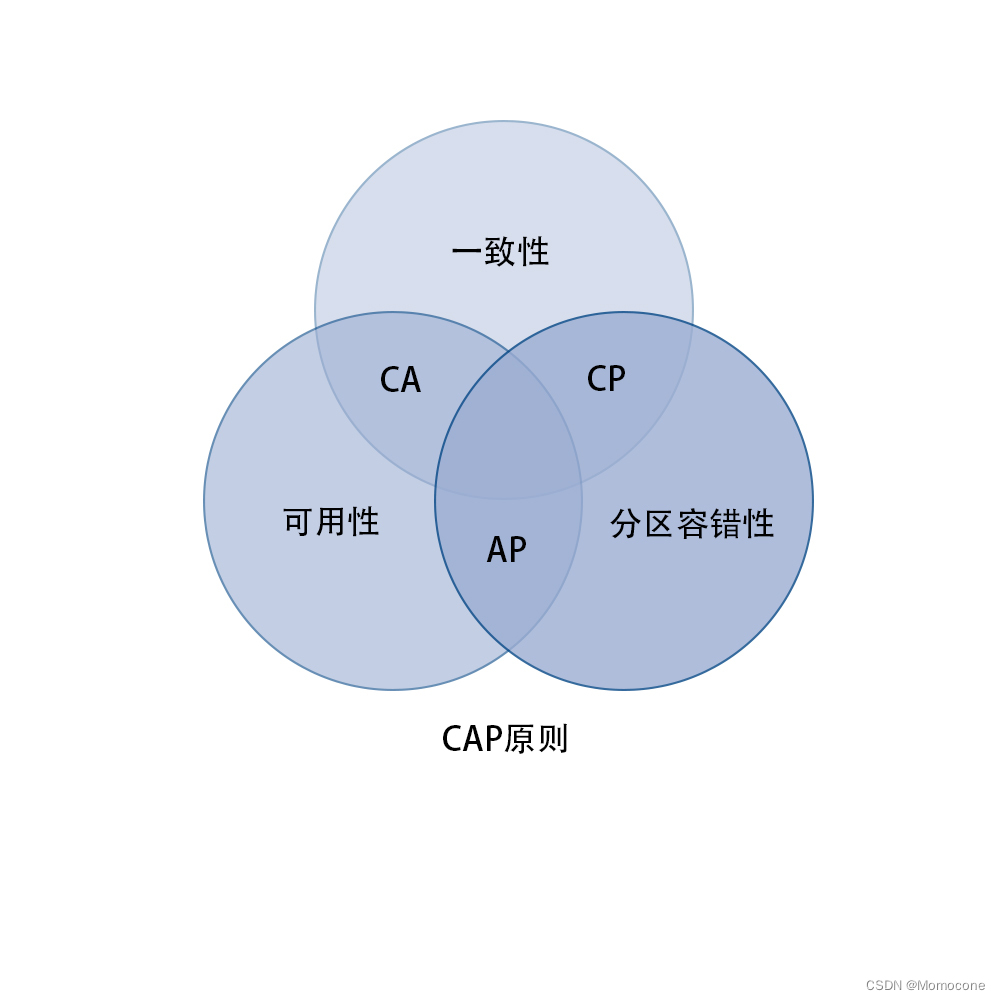
CAP原则包含以下三大元素:
- 一致性(Consistency):系统在执行过某项操作后,仍然处于一致的状态。
- 可用性(Availability):每一个操作总是能够在一定时间内返回结果。
- 分区容错性(Partition Tolerance):系统在遇到任何网络分区故障时,仍然能够保持对外提供服务,即系统对节点动态加入和离开的处理能力。
一个分布式系统中,最多同时实现上述两种元素,不可同时实现三个元素。
BASE理论
BASE理论是CAP原则的延伸,也包含三大元素:
- 基本可用(Basically Available):系统遇到故障时,允许损失部分可用性,保证系统核心可用即可。
- 软状态(Soft-State):允许系统中的数据存在中间状态,即允许数据在不同结点的数据副本之间进行数据同步的过程存在延时。
- 最终一致性(Eventually Consistent):系统中所有数据副本经过一定时间后,最终能够达到一致的状态。
从下面的表中也能够直观看出其与ACID理论的差别:
| 区别 | BASE理论 | ACID理论 |
|---|---|---|
| 一致性 | 弱一致性 | 强一致性 |
| 可用性 | 可用性优先 | 不做要求 |
| 灵活性 | 变化速度快、灵活 | 稳定准确 |
NoSQL数据库的分类
1,键值对存储数据库
键值对存储数据库中的数据都是以键值对的形式来存储的,常见的键值对存储数据库有Redis、Tokyo Cabinet/Tyrant、Voldemort以及OracleBDB等数据库。
键值对存储数据库也是最简单的NoSQL数据库。
2,文档存储数据库
文档存储数据库中的数据通过文档存储,并且文档可以是不同类型,比如JSON、XML以及BSON等格式。常见的文档数据库有MongoDB、CouchDB以及RavenDB等数据库。
3,列式存储数据库
列式数据库是以列为单位存储数据,然后将列值顺序存入数据库中。常见的列式存储数据库有HBase、Cassandra、Riak以及HyperTable等数据库。
4,图形存储数据库
图形数据库主要应用图形理论来存储实体间的关系信息。常见的图形存储数据库有Neo4j、FlockDB、AllegroGrap以及GraphDB等数据库。
一、MongoDB的起源以及发展

起源
1995年,Dwight Merriman创立了DoubleClick,后来Kevin Ryan加入成为CEO,Eliot Horowitz则是一名开发工程师。这个网络广告公司后来被谷歌收购,而这三个人也正是10gen的创始人。
2007年,三人成立了10gen软件公司,意在进军云计算行业。Eliot和Dwight在寻找一个能够支持他们的云计算平台的海量数据库,当时成熟的数据库基本上都是基于单机架构的传统关系型数据库,例如Oracle,MS SQLServer等。即使Oracle支持一些集群部署,其扩展性也仅限于2到4台服务器的范围。他们在DoubleClick时就已经饱受关系数据库的折磨,因为这个网络公司提供的广告信息吞吐量非常大,以至于在关系数据库使用过程中的扩展性和灵敏性遭遇了不少困难。
在没有很好的解决方案的情况下,他们决定自己研发一个数据存储服务,能够把开发者使用的程序对象数据存到一个类似数据库的地方,并提供非常易用的API让开发者可以对数据进行常见的增删改操作。
2008年,10gen进行第一轮融资,投资方为Union Square Venture,估值150万美元。
2年后,也就是2009年的2月份,10gen正式发布开源产品MongoDB1.0,并且成立了开源社区,通过社区运营MongoDB。
发展
2010年8月,10gen发布了MongoDB1.6,第四个大版本。这个版本最大的一个功能就是Sharding,自动分片。在关系数据库中,当数据量达到一定程度,单个节点服务器资源充分饱和无法保证及时的服务器响应时间时,通常会采用分区分表的数据库优化方案。但是这些方法都是侵入式的,很多时候意味着应用程序需要做较大的改动,来配合数据库端的改动。而MongoDB的自动分片,可以在一个集群的几个分片服务器内自动进行数据的分布和均衡。
分片,将数据拆分至不同数据节点的方式,是MongoDB高可用集群的一种形式。MongoDB将数据根据分片算法分割到Chunks,每个Chunk有一个基于分片键的左闭右开区间。一个分片Shard可以含有多个Chunk。MongoDB使用分片集群平衡器在分片集群中迁移Chunks,目的是使其在分片集群中均匀分布。
到2011年为止,10gen一直在通过开源社区扩大MongoDB的影响力,上至CTO,下至开发工程师,大家在社区里,论坛上,邮件组里热心为用户提供技术支持,吸取用户反馈。除了对社区提供技术支持,MongoDB社区极具特色的用户组织MUG则是推广MongoDB技术最有影响力的一个渠道。而MongoDB本身也极具优势,除了便捷的安装使用,还有易用的API操作,加之NoSQL概念如日中天,MongoDB的关注度也逐渐增加。
2013年8月,10gen公司正式更名MongoDB。
2014年12月,MongoDB收购了Keith Bostic和Michael Cahil的WiredTiger存储引擎团队,并将其集成到3.0版本中,成为一个新的存储引擎。WiredTiger的引入MongoDB走向一个成熟数据库的最重要的里程碑。在性能上,WiredTiger较之之前的老版本MongoDB提升了7-10倍,有效解决了之前MMAP在大量写入下的性能瓶颈。
WiredTiger存储引擎对外部通过游标(cursor)方式来实现数据的操作,内部通过journal_log、checkpoint等子模块协调访问IO存储。
2015年12月,在发布的3.2版本中,MongoDB的聚合框架中增加了一个操作符:$lookup,意味着作为一个NoSQL数据库,MongoDB终于开始支持关系数据库的核心功能:关联。
$lookup是MongoDB引入的一种多表关联查询操作, 通过将一个集合中的某个字段作为外键,与另一个集合中的某个字段进行匹配,从而将两个集合中的相关数据合并在一起返回。这个操作类似SQL中的join,但是更加灵活简单。
2017年10月,MongoDB成功上市纳斯达克,成为26年来第一家以数据库产品为主要业务的上市公司。
2018年,发布的MongoDB4.0获得了广泛的关注,并且其云数据库发展良好。2019年3月18日,Forrester授与MongoDB NoSQL领导者称号,股价突破百元大关,市值81亿美元。
总结
从MongoDB的发展历程中,我们很容易看出它成功的原因,除了开源吸引用户外,还通过良好的社区服务增加用户粘性,并借助用户反馈对MongoDB的功能进行完善。其不仅作为NoSQL的领头羊开辟新道路,还将自身的功能做到尽可能的简单易用。除此之外,没有提及的,推出多种商业付费的技术支持和服务,增加创收渠道,也是成功原因之一。
二、MongoDB的体系结构
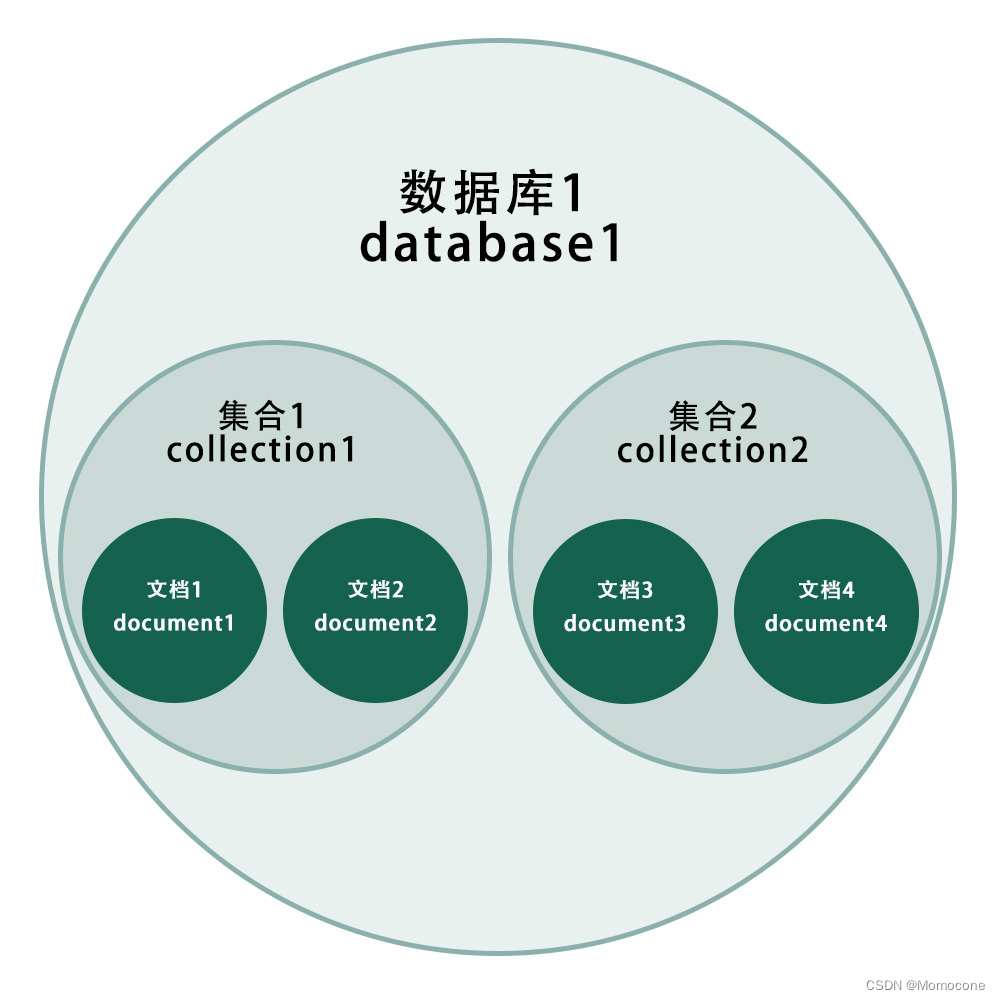
MongoDB的逻辑结构是体系结构的一种,也是层次结构,主要由文档、集合、数据库三部分组成。
1,数据库
MongoDB默认提供四个数据库,分别是admin、local、config、test。数据库存储着文档和集合,一个数据库中可以创建多个集合。
2,集合
一般集合:类似关系数据库中的数据表。集合是无模式或动态模式的,也就意味着集合没有固定的格式。在读写数据前,不需要创建集合模式就可使用,因此集合内的文档可以拥有不同的字段,也可以任意增减某个文档的字段。而通常插入集合的数据都具有一定的关联性。
上限集合:与一般集合的主要区别在于它可以限制集合的容量的大小,在数据存满时,可以从头开始覆盖最开始的文档进行循环写入。
在MongoDB的集合中,有{对象}和[数组],也有对象和数组的相互嵌套。
3,文档
文档以键值对(key:value)的形式存储在集合中,其中有唯一区分文档的主键,键值对中的值可以是任何复杂的文件类型,常见的有String、Double、Array、ISODate等。这种存储方式被称为BSON。MongoDB的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这是MongoDB与关系数据库的巨大差异。
BSON是类JSON的一种二进制形式的存储格式,即BinaryJSON,它和JSON一样,都是支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,例如Data和BinData类型。
MongoDB中的文档与关系数据库中的属性列(多元组)不同点在于,MongoDB中单个文档大小上限为16MB,相比之下已经够大了,但是如果还要存储更大的文档,MongoDB也提供了GridFS。
三、MongoDB的数据类型
| 数据类型 | 相关说明 |
|---|---|
| Double | 双精度浮点型,用于存储浮点值 |
| String | 字符串,常用的数据类型,MongoDB仅支持UTF-8编码的字符串 |
| Object | 对象类型,存储嵌入式文件 |
| Array | 数组类型,用于储存多个值 |
| Binary data | 二进制数据,用于储存二进制数据 |
| Undefined | 已弃用 |
| ObjectID | 对象ID类型,用于存储文档的ID |
| Boolean | 布尔类型,用于存储布尔值 |
| Date | 日期类型,以UNIX时间格式存储标准时间的毫秒数,不存储时区 |
| Null | 空值类型,用于创建空值 |
| Regular Expression | 正则表达式类型,用于存储正则表达式 |
| DBPointer | 已弃用 |
| Code | 代码类型,用于将JavaScript代码存储到文档中 |
| Symbol | 已弃用 |
| Int32 | 整型,用于存储32位整型数值 |
| Timestamp | 时间戳类型,用于记录文档修改或添加的具体时间 |
| Int64 | 整型,用于存储64位整型数值 |
| Decimal128 | Decimal类型,用于记录、处理货币数据,例如财经数据、税率数据等 |
| Min key | 将一个值与BSON元素的最低值相对比 |
| Max key | 将一个值与BSON元素的最高值相对比 |
MongoDB支持不同数据类型作为文档中字段对应的值。
Undefined类型非常容易跟null、空字符串混淆,而且经常会被误用。为了避免数据的混乱,MongoDB建议使用null和空字符串来代替Undefined类型。
DBPointer在某些情况下存在安全问题,或者导致数据冗余。并且它只能用于MongoDB数据库之间的连接,不能用于其他类型的数据库连接。因此,MongoDB建议使用如文档嵌套、引用文档的方法或使用GridFS系统来存储大型二进制数据。
Symbol类型的值是唯一的且不可变的,会导致一些问题,所以MongoDB决定弃用Symbol类型以提高数据类型的一致性和可靠性。
1,数字类型
MongoDB支持多种数字类型,Int32、Int64、Double、Decimal128。在进行数值的存储时,MongoDB会自动将其转为64位浮点数。
由于32位整数都能由64位浮点数精确表达,所以二者没有什么区别,然而64位整数不能用64位浮点数精确表达,因此在mongo shell查看文档中的64位整数时,会通过NumberLong()显示。
而处理金钱等敏感数字时,128位的Decimal类型不会因为精度丢失而造成数值变化。因此在MongoDB中它是独立于其他几个数字类型的特殊存在。
2,日期类型
在mongo shell中创建包含日期类型数值的文档,类似JavaScript,我们需要使用new Date()的方式创建。在MongoDB中,它会自动将其保存为ISODate日期类型,并且会将时间存储为标准时间的毫秒数。其格式如下:
> db.bigdata.insert({"time":new Date()})
> db.bigdata.find()
[
{
_id: ObjectId("650ae6852db2d3d60cb06691"),
time: ISODate("2023-09-20T12:33:09.378Z")
}
]3,数组类型
MongoDB数组是一系列元素的集合,用中括号 [ ] 表示数组。数组元素允许重复且位置固定,数组中可以存在不同数据类型的元素。其格式如下:
{
_id: ObjectId("650983d4c163aaaf6ab6c444"),
"test":[
"math",
"english",
"P.E.",
"C++"
]
}4,ObjectID类型
ObjectID是一个12字节BSON类型,由一组十六进制的24个字符构成。其格式如下:

Time:时间戳;Machine:所在主机的唯一标识符;PID:进程标识符;INC:随机值。
5,内嵌文档
文档中一个对象类型的字段在MongoDB中被称为内嵌文档,也是MongoDB的推荐存储格式。其格式如下:
{
……
"size": {
"h" : 8.5,
"w" : 11.0
},
……
}6,Code类型
在MongoDB数据库的文档中,可以存储一些JavaScript方法。Code类型文档格式如下:
{
_id: ObjectId("650983d4c163aaaf6ab6c444"),
"jscode":function jsCode(a){b=a+2;return b;}
}那么我们也会产生一个疑问,为什么不用String类型记录这些JavaScript方法呢?反而专门用一个Code类型来存储呢?之前被弃用的数据类型不正是被一些类型所取代吗?
相比起String,Code类型存储代码的好处在于三个方面:
- 代码验证和执行:Code类型允许MongoDB服务器验证和执行存储在字段中的JavaScript代码,在数据库中可以存储和运行JavaScript函数、脚本,而不必将它们从字符串解析和执行;
- 安全性:通过Code类型,MongoDB可以更好地管理和控制存储在字段中的JavaScript代码的执行,也允许我们去限制代码的权限和访问,以防止不安全的算法;
- 代码重用:通过将JavaScript代码存储为Code类型,便可以在多个地方重用同一段代码,而不用多次复制粘贴。
四、MongoDB的安装部署
MongoDB下载地址:Install MongoDB Community Kubernetes Operator | MongoDB
MongoDB Shell下载地址:MongoDB Shell Download | MongoDB
1,MongoDB的安装
前往官网下载页面,并选择自己要安装的版本,如下图。
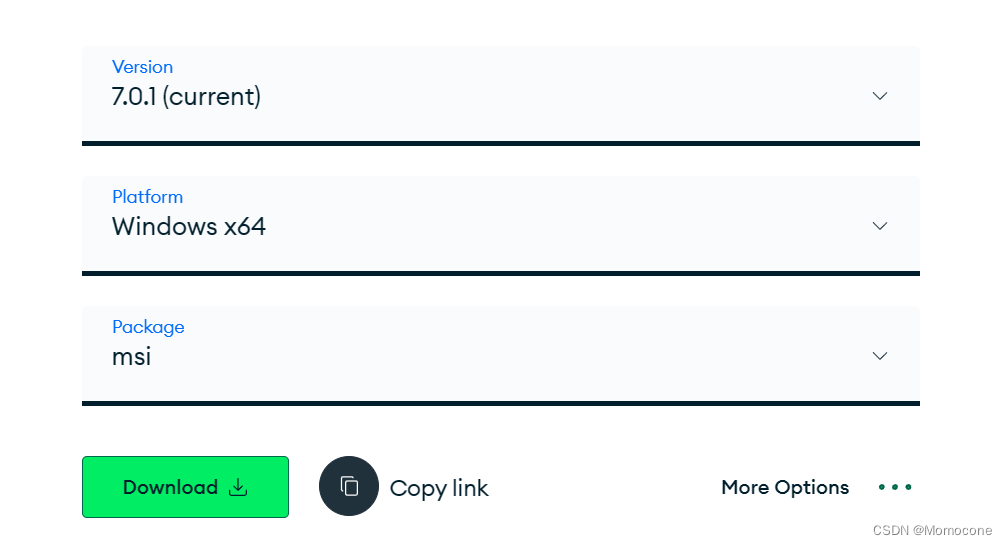
其中,Version是安装的版本号,格式为X.Y.Z,其中X为安装的版本主号;Y用以区分稳定版和测试版,若为偶数则是稳定版,反之为测试版;Z为修订号。Platfotm是OS选择,X64代表64位系统。Package则是打包方式选择,有msi的安装,以及zip的解压安装。
下面介绍Win11的msi安装过程:
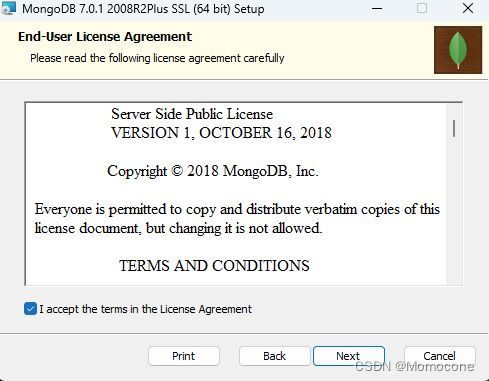
点击next,勾选I accpect,点击next。
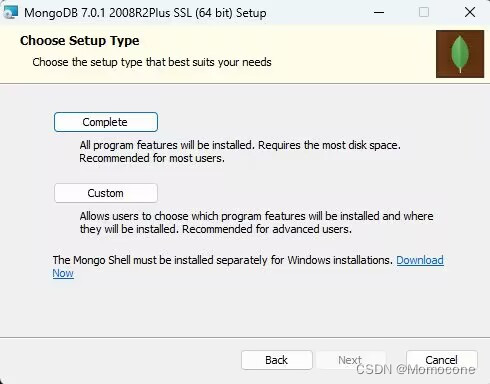
点击Custom,在Location一行选择安装地址,默认C盘,请安装到自己能记住的地方,等下配置环境变量需要用到。
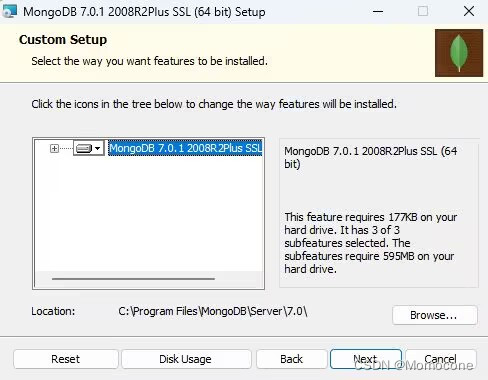
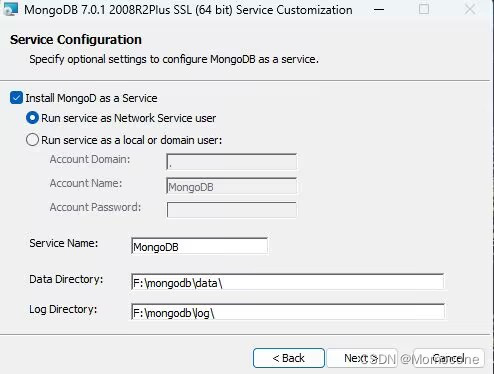
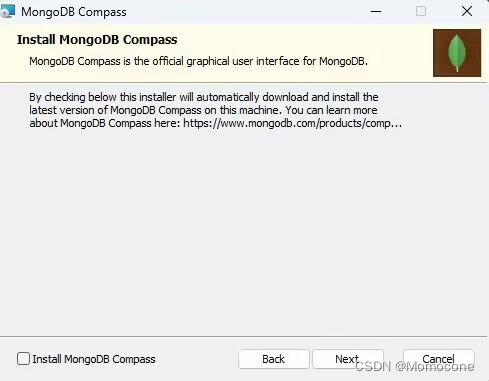
下面的页面保持默认就好,点击next,取消勾选compass,点击next,开始安装。
2,环境变量的设置
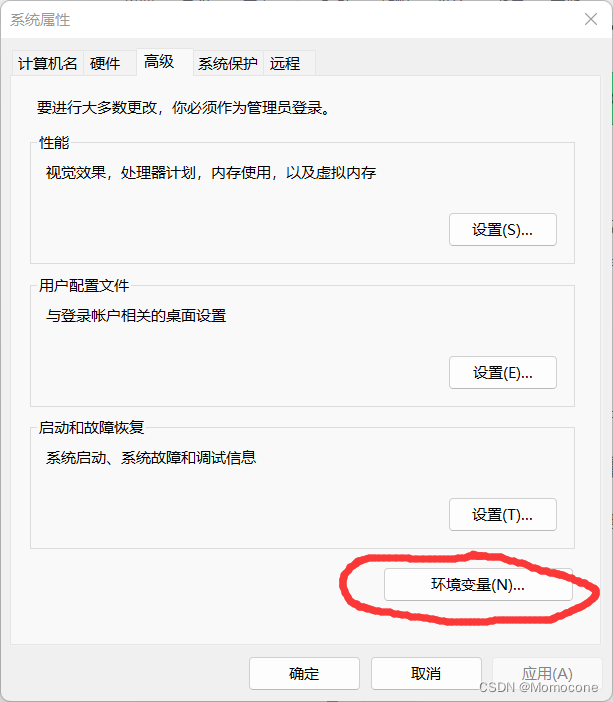
重启电脑后,右键点击此电脑,进入高级系统设置,点击环境变量。
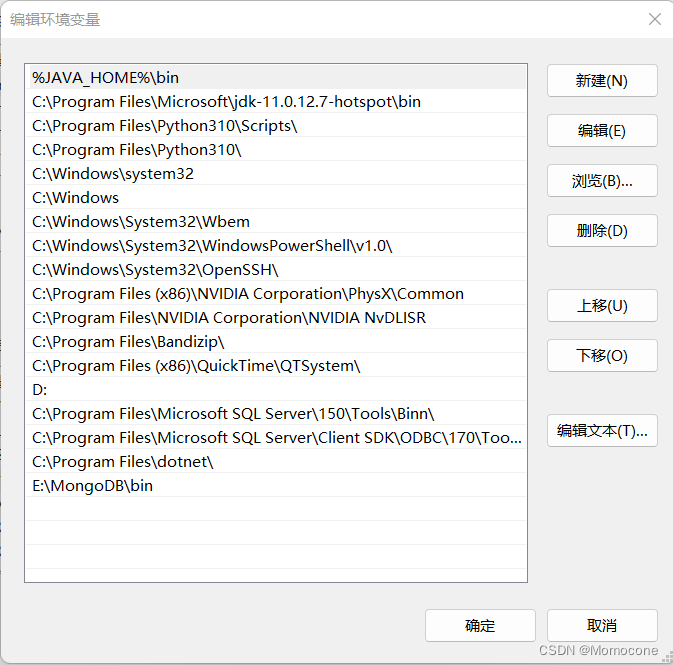
双击系统变量中的Path,点击新建,将此前下载的MongoDB中的Bin文件夹文件地址复制其中。
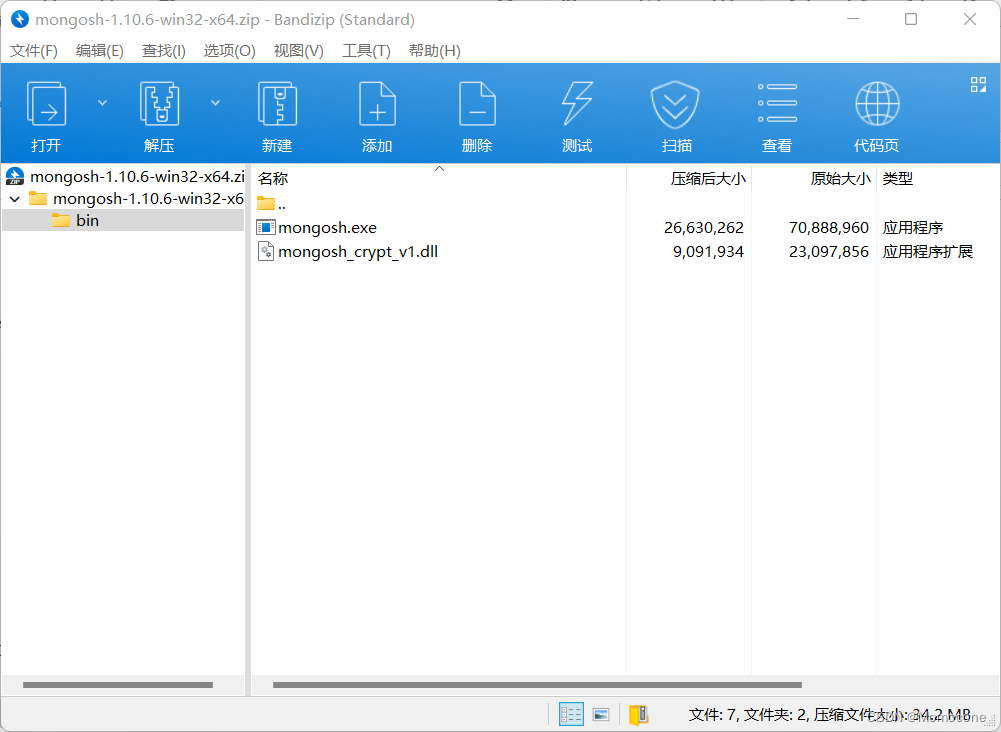
3,Shell的安装
在shell官网下载zip文件,解压后,将bin文件夹中的两个文件移动至此前下载MongoDB的Bin文件夹中。
移动完成后,打开cmd面板,输入mongod,弹出内容如下:
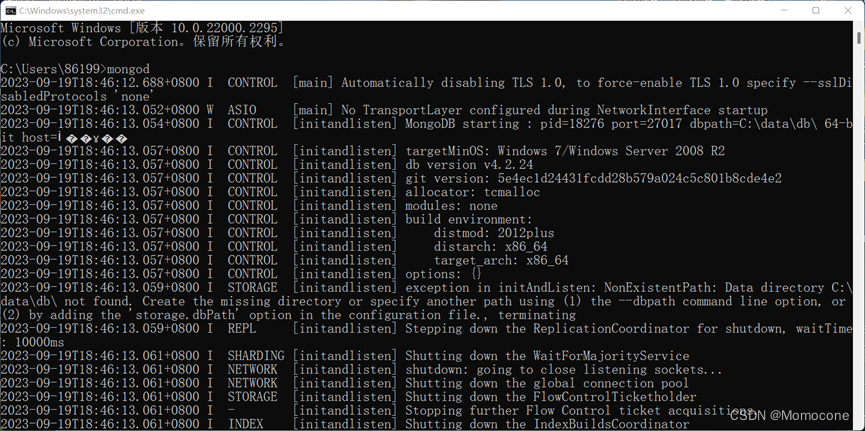
随后输入mongosh,弹出内容,接着继续输入show dbs,弹出自带的三个数据库。
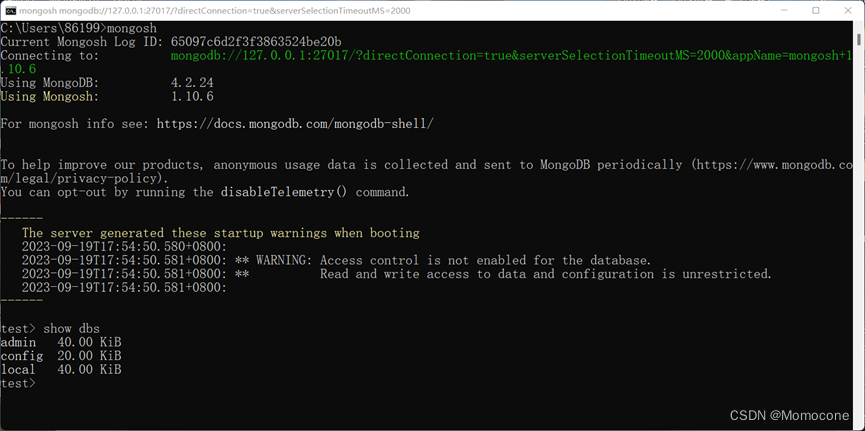
至此,MongoDB下载已完成。
结语
在跟进讲师课程的同时,也触发自身许多思考,例如在学习过程中,提出问题往往比解决问题更为重要,这象征着自己挖掘知识的能力。在课上讲师也提出了许多问题,例如:为什么MongoDB要弃用一些数据类型,是被替代了还是其他原因?为什么Code类型没有被String类型替代,反而保留下来单独存储JavaScript的代码?等等。知识的学习重要的是吸收而不是流于表面,如果只是记概念并不能将其理解透彻。
正值秋招,也很感慨,大学两年浑浑噩噩,蹉跎岁月。前几天看完无职,也开始思考自己的人生,不管怎么说,学习的路途尚且遥远,惟愿自己能够坚持走下去。也希望你在这条路上永远不会孤单。
















 4361
4361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









