




上文:redis底层数据结构
String底层结构
一、编码方式
1.int编码
-
**适用范围:**64位整数(
long) -
**实现:**直接将数据存储在
redisObject的ptr指针位置。 -
内存布局:

2.embstr编码
-
**适用条件:**字符串大小<44字节。
- **实现:**将
redisObject与SDS分配在连续内存中。
- **实现:**将
-
内存布局:

-
redisObject (16B) SDS头 (3B) 字符串数据 (44B) 结尾'\0' (1B) -
总占用:16 + 3 + 44 + 1 = 64字节(刚好利用
jemalloc(按2的次方分配内存)的64B内存块,减少碎片)。
-
-
特点:
- 内存连续,访问高效(减少CPU缓存缺失)。
- 只读设计,修改时自动转为raw编码。
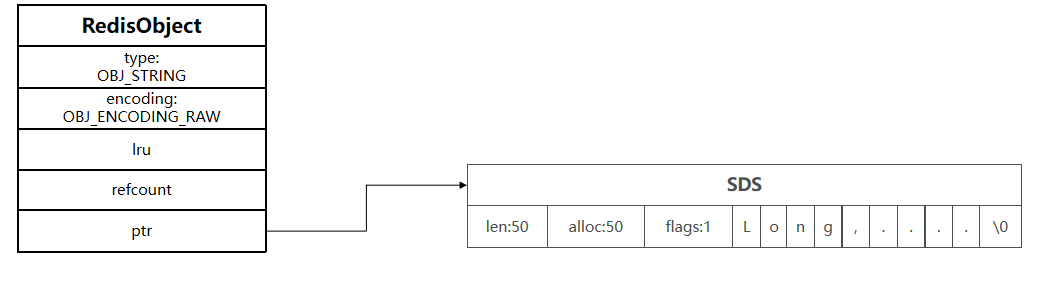
3.raw编码
- 适用条件:字符串长度 > 44字节或含二进制数据。
- 实现:
redisObject与SDS分两次分配内存,ptr指向独立的SDS结构。 - 内存布局:
二、编码转换场景
1.int → raw
执行非整数操作(如APPEND非数字字符)。
2.embstr → raw
修改embstr字符串(因embstr内存不可变)。
List底层结构
一、List的底层演进
| Redis版本 | 底层结构 | 特点 |
|---|---|---|
| ❤️.0 | ziplist 或 linkedlist | 小数据用ziplist(内存紧凑),大数据用linkedlist(操作高效) |
| 3.0~3.2 | quicklist(过渡阶段) | 初步引入分段ziplist设计 |
| ≥3.2 | quicklist(默认统一实现) | 每个节点为ziplist,通过双向链表连接,平衡内存与性能 |
Set底层结构
一、编码方式
1.intset
- 适用条件:
- 所有元素均为 整数(int64_t 范围)。
- 元素数量 ≤
set-max-intset-entries(默认512)。
- 特点:
- 内存紧凑:无指针开销,连续存储整数。
- 自动升级:插入超出当前编码范围的整数时,升级为更大编码。
- 二分查找:元素有序,查找时间复杂度 O(log n)。
- 缺点:
- 不支持非整数类型元素
intset设计初衷是存储整数,只能保存整数。如果尝试往intset里添加非整数类型的数据(如字符串、浮点数等),Redis会将intset升级为hashtable来存储。 - 升级操作开销大
当插入的新元素类型比 intset 现有元素类型长时,需要进行升级操作。整个升级过程涉及大量内存操作和数据类型转换,时间复杂度为 O ( N ) O(N) O(N),在大数据量场景下,会带来较大性能开销。 - 查找效率在数据量增大时降低
intset 内部使用有序数组存储元素,查找元素时采用二分查找算法,平均时间复杂度为 O ( l o g N ) O(log N) O(logN)。虽然二分查找效率较高,但随着元素数量 N 不断增加,查找时间也会相应变长。相比哈希表(平均查找时间复杂度为 O ( 1 ) O(1) O(1)),在大数据量场景下,intset 的查找效率会处于劣势。 - 插入和删除操作效率问题
插入和删除元素时,为了保持数组的有序性,需要移动大量元素。插入或删除操作的平均时间复杂度为 O ( N ) O(N) O(N),,在大数据量场景下,频繁的插入和删除操作会严重影响性能
- 不支持非整数类型元素
2.dict(hashtable)
-
适用条件:
- 元素包含 非整数。
- 元素数量 >
set-max-intset-entries。
-
结构设计:
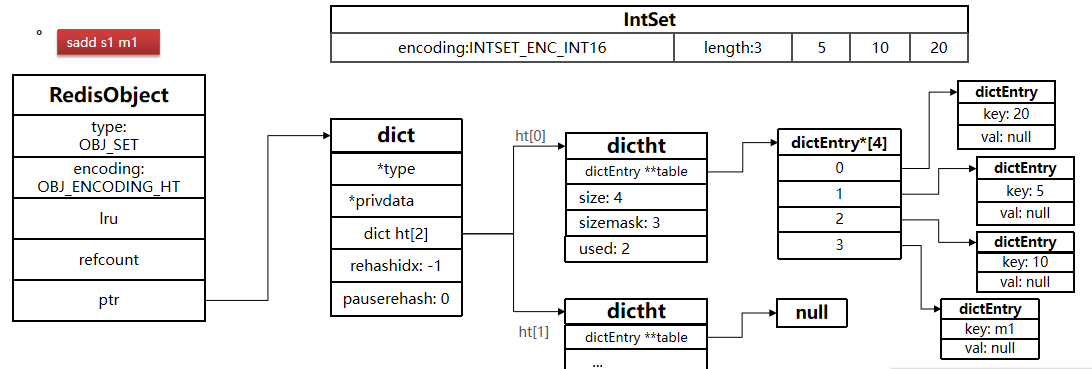
-
特点:
- O(1) 时间复杂度:插入、删除、查找均高效且无
intset升级操作。 - 内存开销大:每个元素需存储 Entry 结构(键指针 + next 指针)。
- O(1) 时间复杂度:插入、删除、查找均高效且无
二、编码转换机制
1. intset → hashtable
- 触发条件:
- 插入 非整数元素。
- 元素数量超过
set-max-intset-entries。
三、内存与性能对比
| 维度 | intset | hashtable |
|---|---|---|
| 内存占用 | 低(无指针,连续存储) | 高(Entry 结构 + 指针) |
| 插入性能 | O(n)(需维护有序性) | O(1)(平均) |
| 查找性能 | O(log n)(二分查找) | O(1)(哈希查找) |
| 适用场景 | 小规模纯整数集合 | 大规模或含非整数元素的集合 |
ZSet底层结构
一、编码方式
1. ziplist(压缩列表)
-
适用条件:
- 元素数量 ≤
zset-max-ziplist-entries(默认128)。 - 所有元素值(member)长度 ≤
zset-max-ziplist-value(默认64字节)。
- 元素数量 ≤
-
存储方式:
-
元素(member)和分数(score)成对存储,按分数升序排列。
-
结构示例:
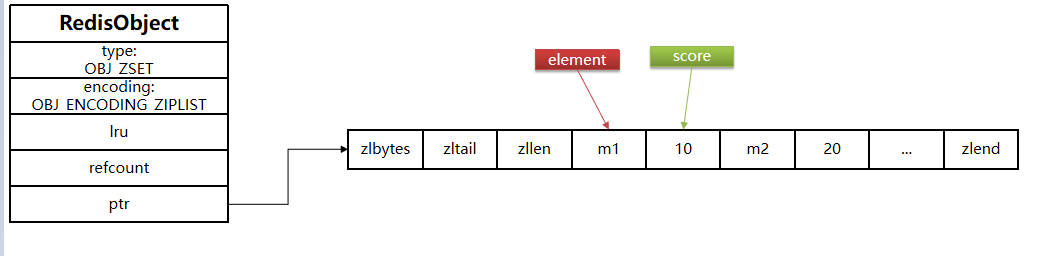
特点:
-
内存紧凑:连续内存块存储,无指针开销。
-
插入/删除低效:需重分配内存并移动数据,时间复杂度 O(n),大数据量场景下性能低。
-
2. skiplist(跳跃表) + dict(哈希表)
- 适用条件:
- 元素数量或值大小超过上述阈值。
- 结构设计:
- 跳跃表(zskiplist):
- 按分数排序,支持 O(log n) 的插入、删除和范围查询。
- 节点结构包含成员(member)、分数(score)、多层前向指针。
- 哈希表(dict):
- 键为成员(member),值为分数(score),支持 O(1) 的成员查找。
- 跳跃表(zskiplist):
- 协作机制:
- 插入:同时向跳跃表和哈希表插入数据,保证一致性。
- 查询:哈希表快速定位分数(
zscore),跳跃表处理范围操作(zrangezrevrangezrangebyscore)。
- 特点:
- 查询效率高
- 内存开销大
二、编码转换机制
- ziplist → skiplist:
- 触发条件:插入元素导致数量或值大小超限。
- 过程:遍历 ziplist,将所有元素插入跳跃表和哈希表。
Hash底层结构
Hash底层采用的编码与Zset基本一致,只需要把排序有关的SkipList去掉即可。
一、编码方式
1.ziplist
- 适用条件:
- 字段数量 ≤
hash-max-listpack-entries(默认512)。 - 每个字段的值长度 ≤
hash-max-listpack-value(默认64字节)。
- 字段数量 ≤
- 结构特点:
- 内存紧凑:连续存储字段-值对,无指针开销。
- 顺序存储:字段和值按添加顺序排列,适合小数据量。
- 快速遍历:支持线性遍历,但随机访问需顺序查找。
- 操作限制:
- 插入/删除低效:需内存重分配和数据移动,时间复杂度 O(n)。
- 自动转换:超出阈值时转为hashtable。
2.hashtable(字典dict)
- 适用条件:
- 字段数量或值大小超过listpack/ziplist阈值。
- 结构设计:
- 哈希表:使用链地址法解决冲突,每个哈希节点存储字段和值的指针。
- 快速操作:
- 查找/插入/删除:平均 O(1) 时间复杂度。
- 支持大规模数据:动态扩容缩容,适应数据增长。
- 内存开销:
- 每个字段需额外存储指针和哈希表元数据,内存占用较高。
二、编码转换机制
- listpack/ziplist → hashtable:
- 触发条件:字段数超限或单个值超长。
三、内存结构
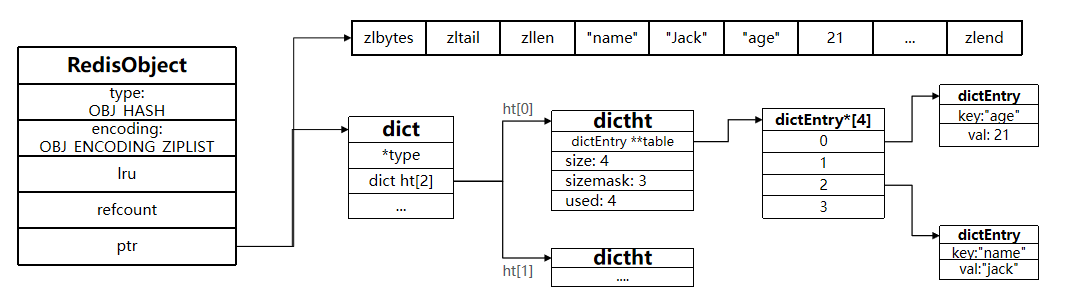


















 4609
4609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











