







Hadoop1.X集群完全分布式模式环境部署
1 Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
2 实验环境
- 操作平台:parallers Desktop
- 操作系统:CentOS 6.5
- 软件版本:hadoop-1.2.1.tar.gz,jdk-8u121-linux-x64.tar.gz
-
集群架构:包括4个节点:1个Master,3个Salve,节点之间局域网连接,可以相互ping通。

-
节点IP地址分布如下:
| 主机名 IP | 系统版本 | Hadoop | node | hadoop进程名 |
|---|---|---|---|---|
| Master | 192.168.33.200 | CentOS 6.5 | master | namenode,jobtracker |
| Slave1 | 192.168.33.201 | CentOS 6.5 | slave | datanode,tasktracker |
| Slave2 | 192.168.33.202 | CentOS 6.5 | slave | datanode,tasktracker |
| Slave3 | 192.168.33.203 | CentOS 6.5 | slave | datanode,tasktracker |
四个节点上均是CentOS 6.5系统,并且有一个相同的用户hadoop。Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;3个Salve机器配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行。
2.1 配置网络
四台虚拟机按照上面的网络环境来进行配置
主机名,静态ip,hosts映射。
1.修改主机名
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=Master
2.修改ip地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0
BOOTPROTO="static" #dhcp改为static
ONBOOT="yes" #开机启用本配置
IPADDR=192.168.33.200 #静态IP
GATEWAY=192.168.33.1 #默认网关
NETMASK=255.255.255.0 #子网掩码
service network restart
3.修改ip地址和主机名的映射关系
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.33.200 Master
192.168.33.201 Slave1
192.168.33.202 Slave2
192.168.33.203 Slave3
4.关闭iptables并设置其开机启动/不启动
service iptables stop
chkconfig iptables on
chkconfig iptables off
2.2 安装JDK
在4台机器上分别配置好jdk
1.上传jdk-8u121-linux-x64.tar.gz到Linux上
2.解压jdk到/usr/local目录
tar -zxvf jdk-8u121-linux-x64.tar.gz -C /usr/local/
3.设置环境变量,在/etc/profile文件最后追加相关内容
vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
4.刷新环境变量
source /etc/profile
5.测试java命令是否可用
java -version
2.3 创建用户
- 创建新用户
[root@localhost ~]# adduser cmj
为这个用户初始化密码,linux会判断密码复杂度,不过可以强行忽略:
[root@localhost ~]# passwd cmj
更改用户 cmj 的密码
新的 密码:
无效的密码: 密码未通过字典检查 - 过于简单化/系统化
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
2.授权
[root@localhost ~]# ls -l /etc/sudoers
-r--r----- 1 root root 4251 9月 25 15:08 /etc/sudoers
sudoers只有只读的权限,如果想要修改的话,需要先添加w权限:
[root@localhost ~]# chmod -v u+w /etc/sudoers
mode of "/etc/sudoers" changed from 0440 (r--r-----) to 0640 (rw-r-----)
然后就可以添加内容了,在下面的一行下追加新增的用户:
[root@localhost ~]# vim /etc/sudoers
## Allow root to run any commands anywher
root ALL=(ALL) ALL
cmj ALL=(ALL) ALL #这个是新增的用户
wq保存退出,这时候要记得将写权限收回:
[root@localhost ~]# chmod -v u-w /etc/sudoers
mode of "/etc/sudoers" changed from 0640 (rw-r-----) to 0440 (r--r-----)
这时候使用新用户登录,使用sudo:
第一次使用会提示你,你已经化身超人,身负责任。而且需要输入密码才可以下一步。如果不想需要输入密码怎么办,将最后一个ALL修改成NOPASSWD: ALL。
3 先决条件
- 1) 确保在你集群中的每个节点上都安装了所有必需软件:sun-JDK ssh Hadoop。
- 2) JavaTM1.5.x,必须安装,建议选择Sun公司发行的Java版本。
- 3) ssh 必须安装并且保证 sshd一直运行,以便用Hadoop 脚本管理远端Hadoop守护进程。
- 4) 关闭防火墙和SELinux
4 SSH免密登陆
在Hadoop启动以后,Namenode是通过SSH(Secure Shell)来启动和停止各个datanode上的各种守护进程的,这就须要在节点之间执行指令的时候是不须要输入密码的形式,故我们须要配置SSH运用无密码公钥认证的形式。以本文中的四台机器为例,现在Master是主节点,他须要连接Slave1、Slave2和Slave3。须要确定每台机器上都安装了ssh,并且datanode机器上sshd服务已经启动。
切换到hadoop用户( 保证用户hadoop可以无需密码登录,因为我们后面安装的hadoop属主是hadoop用户。)需要使得Master到Slave1,Slave2,Slave3免密登陆,以及Slave1,Slave2,Slave3到Master的免密登陆,以及Master,Slave1,Slave2,Slave3到自身回环口的免密登陆

1) 在每台主机生成密钥对
注意是在cmj用户之下,而不是root,因为我们最终是要使用cmj用户来使用hadoop,而你在cmj用户下配置免密登陆后,切换至root用户或者其他用户的使用ssh登陆时,仍然需要密码。
#su cmj
#ssh-keygen -t rsa
#cat ~/.ssh/id_rsa.pub
这个命令生成一个密钥对:id_rsa(私钥文件)和id_rsa.pub(公钥文件)。默认被保存在~/.ssh/目录下。
2) 将Master公钥添加到远程主机Slave1的 authorized_keys 文件中
在/home/cmj/.ssh/下创建authorized_keys
上传Master公钥到Slave1中:
#scp /home/cmj/.ssh/id_rsa.pub cmj@slave1:/home/cmj/
到slave1中将刚才复制的公钥追加到authorized_keys中
#cd ~
#cat id_rsa.pub >> .ssh/authorized_keys
#rm -f id_rsa.pub #删除Master复制到slave1下的临时key
权限设置为600.(这点很重要,网没有设置600权限会导致登陆失败)
#chmod 600 .ssh/authorized_keys
测试登陆
$ ssh Slave1
The authenticity of host 'Master (192.168.33.200)' can't be established.
RSA key fingerprint is d5:18:cb:5f:92:66:74:c7:30:30:bb:36:bf:4c:ed:e9.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'Master,192.168.33.200' (RSA) to the list of known hosts.
Last login: Fri Aug 30 21:31:36 2013 from slave1
[cmj@Slave1 ~]$
同样的方法,将Master 的公钥复制到其他节点。另外自身节点要设置免密登陆。把自身的公钥追加到自身的authorized_keys中。
3)配置好其他的免密登陆
步骤类似上面。
3、安装Hadoop
1) 切换为cmj用户,下载安装包后,直接解压安装即可:
#su cmj
#wget http://apache.stu.edu.tw/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
#tar -zxvf hadoop-1.2.1.tar.gz
我的安装目录为:
/home/cmj/hadoop-1.2.1
为了方便,使用hadoop命令或者start-all.sh等命令,修改Master上/etc/profile 新增以下内容:
export HADOOP_HOME=/home/cmj/hadoop-1.2.1
export PATH=$PATH:$HADOOP_HOME/bin
修改完毕后,执行source /etc/profile 来使其生效。
2) 配置conf/hadoop-env.sh文件
配置conf/hadoop-env.sh文件,添加:
export JAVA_HOME=/usr/local/jdk1.8.0_121/
这里修改为你的jdk的安装位置。
测试hadoop安装:
/home/cmj/hadoop-1.2.1/bin/hadoop jar hadoop-0.20.2-examples.jarwordcount conf/ /tmp/out
4、集群配置(所有节点相同)
1) 配置文件:conf/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/cmj/tmp</value>
</property>
</configuration>
fs.default.name是NameNode的URI。hdfs://主机名:端口/
hadoop.tmp.dir :Hadoop的默认临时路径,这个最好配置,如果在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令。
2) 配置文件:conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>Master:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/home/cmj/tmp</value>
</property>
</configuration>
mapred.job.tracker是JobTracker的主机(或者IP)和端口。主机:端口。
3) 配置文件:conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/cmj/name1, /home/cmj/name2</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/cmj/data1, /home/cmj/data2</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
dfs.name.dir是NameNode持久存储名字空间及事务日志的本地文件系统路径。 当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。
dfs.data.dir是DataNode存放块数据的本地文件系统路径,逗号分割的列表。 当这个值是逗号分割的目录列表时,数据将被存储在所有目录下,通常分布在不同设备上。
dfs.replication是数据需要备份的数量,默认是3,如果此数大于集群的机器数会出错。
注意:此处的name1、name2、data1、data2目录不能预先创建,hadoop格式化时会自动创建,如果预先创建反而会有问题。
4) 配置masters和slaves主从结点
配置conf/masters和conf/slaves来设置主从结点,注意最好使用主机名,并且保证机器之间通过主机名可以互相访问,每个主机名一行。
$vim masters:
输入:
Master
$vim slaves:
输入:
Slave1
Slave2
Slave3
配置结束,把配置好的hadoop文件夹拷贝到其他集群的机器中,并且保证上面的配置对于其他机器而言正确,例如:如果其他机器的Java安装路径不一样,要修改conf/hadoop-env.sh
$scp -r /home/cmj/hadoop-1.2.1 Slave1:/home/cmj/
$scp -r /home/cmj/hadoop-1.2.1 Slave2:/home/cmj/
$scp -r /home/cmj/hadoop-1.2.1 Slave3:/home/cmj/
5、hadoop启动
1) 格式化一个新的分布式文件系统
$ cd /home/cmj/hadoop-1.2.1
$ bin/hadoop namenode -format
成功情况下系统输出:
Warning: $HADOOP_HOME is deprecated.
13/09/10 16:39:31 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = Master/192.168.137.100
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.2.1
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1503152; compiled by 'mattf' on Mon Jul 22 15:23:09 PDT 2013
STARTUP_MSG: java = 1.6.0_45
************************************************************/
13/09/10 16:39:32 INFO util.GSet: Computing capacity for map BlocksMap
13/09/10 16:39:32 INFO util.GSet: VM type = 64-bit
13/09/10 16:39:32 INFO util.GSet: 2.0% max memory = 1013645312
13/09/10 16:39:32 INFO util.GSet: capacity = 2^21 = 2097152 entries
13/09/10 16:39:32 INFO util.GSet: recommended=2097152, actual=2097152
13/09/10 16:39:32 INFO namenode.FSNamesystem: fsOwner=hadoop
13/09/10 16:39:32 INFO namenode.FSNamesystem: supergroup=supergroup
13/09/10 16:39:32 INFO namenode.FSNamesystem: isPermissionEnabled=true
13/09/10 16:39:32 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
13/09/10 16:39:32 INFO namenode.FSNamesystem: isAccessTokenEnabled=falseaccessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
13/09/10 16:39:32 INFO namenode.FSEditLog: dfs.namenode.edits.toleration.length = 0
13/09/10 16:39:32 INFO namenode.NameNode: Caching file names occuring more than 10 times
13/09/10 16:39:33 INFO common.Storage: Image file /home/hadoop/name1/current/fsimage of size 112 bytes saved in 0 seconds.
13/09/10 16:39:33 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/home/hadoop/name1/current/edits
13/09/10 16:39:33 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/home/hadoop/name1/current/edits
13/09/10 16:39:33 INFO common.Storage: Storage directory /home/hadoop/name1 has been successfully formatted.
13/09/10 16:39:33 INFO common.Storage: Image file /home/hadoop/name2/current/fsimage of size 112 bytes saved in 0 seconds.
13/09/10 16:39:33 INFO namenode.FSEditLog: closing edit log: position=4, editlog= /home/hadoop/name2/current/edits
13/09/10 16:39:33 INFO namenode.FSEditLog: close success: truncate to 4, editlog= /home/hadoop/name2/current/edits
13/09/10 16:39:33 INFO common.Storage: Storage directory /home/hadoop/name2 has been successfully formatted.
13/09/10 16:39:33 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at Master/192.168.137.100
************************************************************/
查看输出保证分布式文件系统格式化成功执行完后可以到master机器上看到/home/hadoop//name1和/home/hadoop/name2两个目录。在主节点master上面启动hadoop,主节点会启动所有从节点的hadoop。
2) 启动所有节点
启动方式1:
$ bin/start-all.sh
(同时启动HDFS和Map/Reduce)系统输出:
$ bin/start-all.sh
Warning: $HADOOP_HOME is deprecated.
starting namenode, logging to /home/hadoop/hadoop-1.2.1/libexec/../logs/hadoop-hadoop-namenode-Master.out
Slave3: starting datanode, logging to /home/hadoop/hadoop-1.2.1/libexec/../logs/hadoop-hadoop-datanode-Slave3.out
Slave2: starting datanode, logging to /home/hadoop/hadoop-1.2.1/libexec/../logs/hadoop-hadoop-datanode-Slave2.out
Slave1: starting datanode, logging to /home/hadoop/hadoop-1.2.1/libexec/../logs/hadoop-hadoop-datanode-Slave1.out
The authenticity of host 'master (192.168.137.100)' can't be established.
RSA key fingerprint is d5:18:cb:5f:92:66:74:c7:30:30:bb:36:bf:4c:ed:e9.
Are you sure you want to continue connecting (yes/no)? yes
Master: Warning: Permanently added 'master,192.168.137.100' (RSA) to the list of known hosts.
hadoop@master's password:
Master: starting secondarynamenode, logging to /home/hadoop/hadoop-1.2.1/libexec/../logs/hadoop-hadoop-secondarynamenode-Master.out
starting jobtracker, logging to /home/hadoop/hadoop-1.2.1/libexec/../logs/hadoop-hadoop-jobtracker-Master.out
Slave2: starting tasktracker, logging to /home/hadoop/hadoop-1.2.1/libexec/../logs/hadoop-hadoop-tasktracker-Slave2.out
Slave3: starting tasktracker, logging to /home/hadoop/hadoop-1.2.1/libexec/../logs/hadoop-hadoop-tasktracker-Slave3.out
Slave1: starting tasktracker, logging to /home/hadoop/hadoop-1.2.1/libexec/../logs/hadoop-hadoop-tasktracker-Slave1.out
执行完后可以到master(Master)和slave(Slave1,Slave2,Slave3)机器上看到/home/hadoop/hadoopfs/data1和/home/hadoop/data2两个目录。
启动方式2:
启动Hadoop集群需要启动HDFS集群和Map/Reduce集群。
在分配的NameNode上,运行下面的命令启动HDFS:
$ bin/start-dfs.sh
(单独启动HDFS集群)
bin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。
在分配的JobTracker上,运行下面的命令启动Map/Reduce:$bin/start-mapred.sh
(单独启动Map/Reduce)
bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动TaskTracker守护进程。
3) 关闭所有节点
从主节点master关闭hadoop,主节点会关闭所有从节点的hadoop。
$ bin/stop-all.sh
Hadoop守护进程的日志写入到 ${HADOOP_LOG_DIR}目录 (默认是 ${HADOOP_HOME}/logs).
${HADOOP_HOME}就是安装路径.
6、测试
1) 用jps检验各后台进程是否成功启动
--在master节点查看后台进程
$ /usr/local/jdk1.6.0_45/bin/jps
3180 Jps
2419 SecondaryNameNode
2236 NameNode
2499 JobTracker
--在slave节点查看后台进程
$ /usr/local/jdk1.6.0_45/bin/jps
2631 Jps
2277 DataNode
2365 TaskTracker
2) 通过用浏览器和http访问NameNode和JobTracker的网络接口:
NameNode – http://Master:50070/dfshealth.jsp
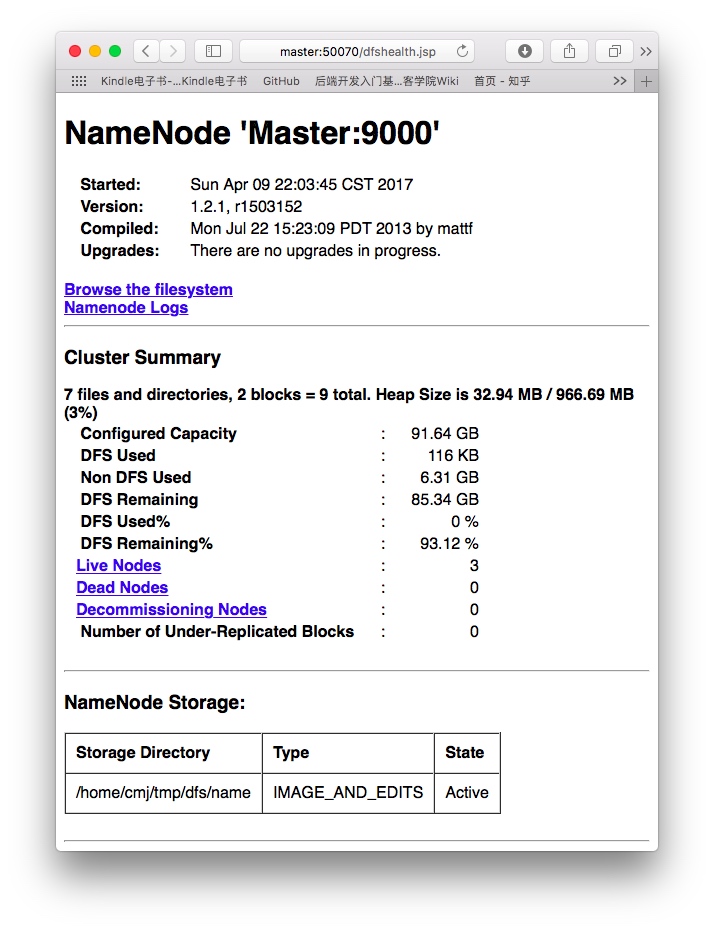
3) 使用s查看端口9000和9001是否正在使用。
HDFS操作
运行bin/目录的hadoop命令,可以查看Haoop所有支持的操作及其用法,这里以几个简单的操作为例。
建立目录
$bin/hadoop dfs -mkdir testdir
Warning: $HADOOP_HOME is deprecated.
13/09/10 17:29:05 WARN fs.FileSystem: "Master:9000" is a deprecated filesystem name. Use"hdfs://Master:9000/" instead.
在HDFS中建立一个名为testdir的目录
复制文件
$ bin/hadoop dfs -put /home/hadoop/hadoop-1.2.1.tar.gz testfile.zip
Warning: $HADOOP_HOME is deprecated.
13/09/10 17:30:32 WARN fs.FileSystem: "Master:9000" is a deprecated filesystem name. Use"hdfs://Master:9000/" instead.
13/09/10 17:30:33 WARN fs.FileSystem: "Master:9000" is a deprecated filesystem name. Use"hdfs://Master:9000/" instead
把本地文件/home/hadoop/hadoop-1.2.1.tar.gz拷贝到HDFS的根目录/user/hadoop/下,文件名为testfile.zip
查看现有文件
$ bin/hadoop dfs -ls
Warning: $HADOOP_HOME is deprecated.
13/09/10 17:32:00 WARN fs.FileSystem: "Master:9000" is a deprecated filesystem name. Use"hdfs://Master:9000/" instead.
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2013-09-10 17:29 /user/hadoop/testdir
-rw-r--r-- 3 hadoop supergroup 63851630 2013-09-10 17:30 /user/hadoop/testfile.zip















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









