







本次实验爬虫任务工具较为简单,主要是熟悉正则表达式的匹配:
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>', re.S)以上的正则表达式中,分别匹配:
电影的id(\d+),图片的地址(……src=”(.?)”.?name”>……),名称(……<\a.?>(.?)……),演员信息(……star”>(.?)<\/p>……),上映时间(……releasetime”>(.?)<……)以及评分(……integer”>(.?)<…….?fraction”>(.*?)<……,),之后再使用yield进行格式化:
`yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5]+item[6]
}`得到上述的格式化数据之后,就可以写入txt文件进行持久化保存了。整个代码如下:
import json
import requests
from requests.exceptions import RequestException
import re
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
# 解析网页
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?in'
'teger">(.*?)</i>.*?fraction">(.*?)</i>', re.S)
items = re.findall(pattern, html)
print(items)
# 将解析的结果格式化
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5]+item[6]
}
def write_to_file(content):
with open("result.txt", 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False)+'\n')
f.close()
# 以offset作为参数,实现分页抓取数据
def main(offset):
url = "http://maoyan.com/board/4?offset=" + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
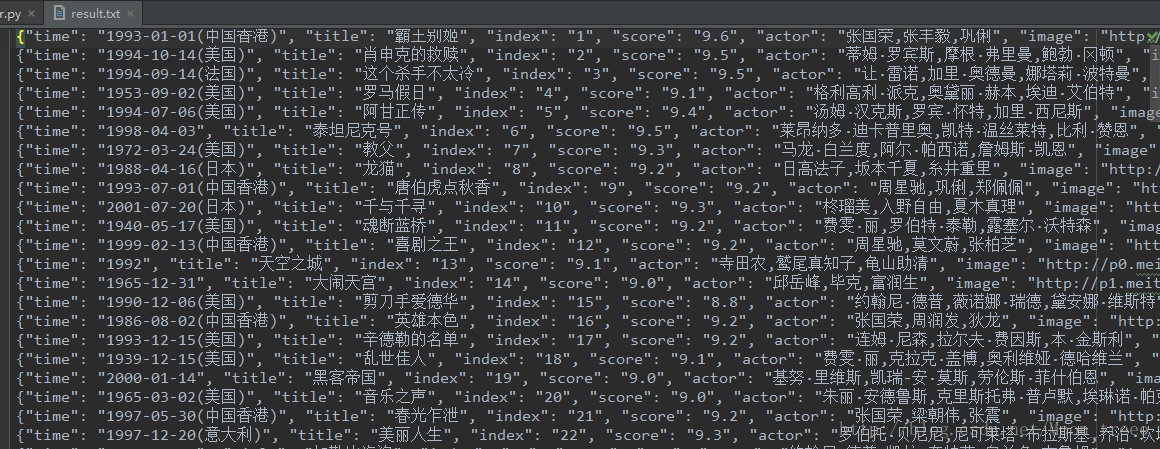
main(i*10)最终效果如下图:















 3785
3785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









