







 本文介绍了字节跳动数据库从2015年至今的发展历程,包括早期的石器时代,标准化和系统化阶段,以及当前的融合智能化阶段。在演进过程中,数据库团队面临了业务种类繁多、增速快和成本高等挑战。目前,字节跳动的veDB数据库系统采用计算和存储分离的设计,提供了高可用性、高性能和低成本的优势。未来,团队将关注场景融合、基础设施层面的分离和整合,以及数据库的智能化运维。
本文介绍了字节跳动数据库从2015年至今的发展历程,包括早期的石器时代,标准化和系统化阶段,以及当前的融合智能化阶段。在演进过程中,数据库团队面临了业务种类繁多、增速快和成本高等挑战。目前,字节跳动的veDB数据库系统采用计算和存储分离的设计,提供了高可用性、高性能和低成本的优势。未来,团队将关注场景融合、基础设施层面的分离和整合,以及数据库的智能化运维。
日前,字节跳动技术社区 ByteTech 举办的第四期字节跳动技术沙龙圆满落幕,本期沙龙以《字节云数据库架构设计与实战》为主题。在沙龙中,字节跳动基础架构数据库资深工程师张雷,跟大家分享了《字节跳动数据库的过去、现状与未来》,本文根据分享整理而成。
数据库技术一直是信息技术中极其重要的一环,在步入云原生时代后,云基础设施和数据库进一步整合,弥补了传统数据库的痛点,带来了高可扩展性、全面自动化、快速部署、节约成本、管理便捷等优势。
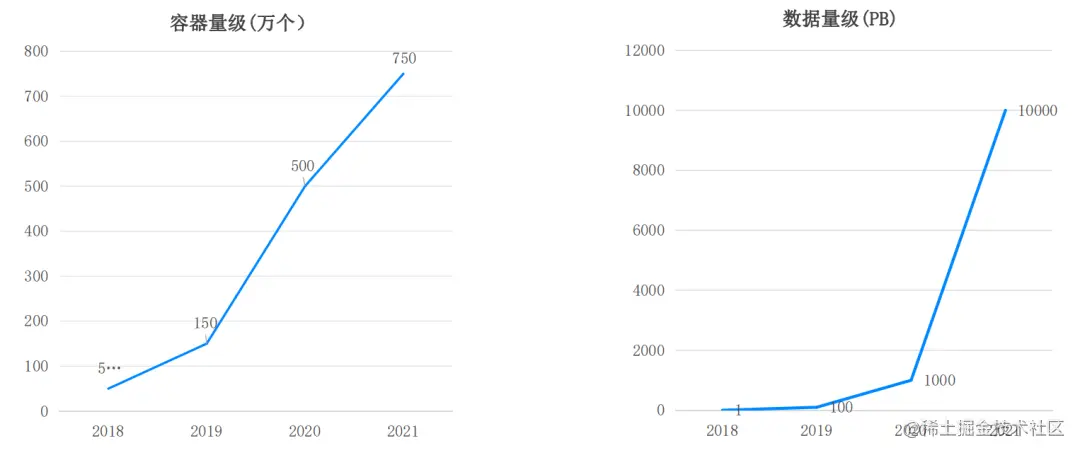
从 2018 到 2021 年,伴随业务和数据的迅猛增长,字节跳动的分布式数据库系统取得了令人振奋的发展。如下图所示,在这 4 年间,公司应用侧容器数量从 5 万个增长到了 750 万个,截至目前已经突破 1000 万。这 1000 万个容器筑成了字节跳动坚实的云原生基础设施,支撑着整个业务体系的发展。
从在线数据角度看,1000 万个容器构成了超过 10 万个微服务,这些微服务在线上运行期间会产生大量数据。在 2020 年,字节跳动的在线数据量级达到 EB 级;到 2021 年 5 月份,字节跳动数据库团队已支撑超过 10 EB 的存储规模。
面对如此庞大的应用规模和数据规模,如何在数据库领域进行数据管理和数据治理,成了摆在数据库团队面前的巨大难题。而在字节跳动内部,数据库建设主要面临三大挑战:
业务种类繁多。 以抖音为例,为了管理用户之间复杂的社交关系,同时根据用户点赞、关注等行为进行智能推荐,我们需要用图进行管理。再如抖音电商商城设计订单、库存等数据,这些信息适合用关系型结构化的结构表达。除此之外抖音还存在大量结构化和非结构化数据,如用户上传的图片、视频,这些信息适合用云存储、对象存储这样的系统来管理。
业务增速快,诉求不断变化。 如上图所示,近 3 年内,字节跳动的数据量迎来了近 100 倍的增长,业务对数据的诉求也产生了一些变化。一开始客户只需要几 TB 或几十 GB 的数据,到一年两年后,他们就要求基础架构能应对数十 TB 甚至数百 TB 的数据量级。如何快速满足应用侧的数据容量需求、吞吐需求变化,是我们遇到的第二个挑战。
数据存量太多,成本居高不下。 随着业务的快速发展,如何管理庞大的结构化和非结构化数据,并有效应对高昂的成本,对我们而言也十分具有挑战性。
字节跳动数据库的演进
字节跳动数据库经历了以下三个阶段:

2015 - 2017 年:刀耕火种的石器时代。 在这一阶段,字节跳动的业务量级比较小,主要的 App 是今日头条,因此数据库的实例大概在 1~2k 量级,产品主要以开源的 MySQL 和 MyRocks 为主,运维体系主要是依靠人工和脚本。
2018 - 2021 年:标准化、系统化。 随着抖音的快速发展,字节的业务规模也迎来快速增长,达到数千套库和数万个数据库实例,原有产品体系已难以解决用户需求,因此我们引入了类似 MongoDB 等开源方案。此外,我们也从 2019 年开始研发云原生分布式数据库产品 veDB 。 我们还更新了运维体系,由原来半自动化半人工的状态逐渐走向平台化,大大提升运营效率。
2021 年底至今:融合智能化。 当前,字节跳动内部已经开始研发数据库的第三代产品技术体系。在未来几年内,我们预计公司业务规模会上升到数万套库、数十万数据库实例,因此在原有产
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









