









是否还在为如此优秀的你还没有对象而愁掉了头发,是否还在依赖OOP来new出一个对象.其实这个世界缺少的不是对象,而是发现对象的眼睛.当然如此优秀的你也可能只是缺少时间.
本文简要分析4中查找算法,看看能不能帮您找到那个心仪的对象.
1.顺序查找
2.二分查找
--斐波那契查找
--插值查找
3.分块查找
4.哈希查找
5.树形查找
找对象的步骤:
1>确定查找范围
你是在哪里找对象呢?是同学中?还是朋友中?还在同时中?还是陌生人中?抑或大街上?抑或夜店里?然后我们将这些待查找的对象放在一个容器中,比如列表.假设这被称为数据源.
2>确定查找目标
你是看中外貌呢?还是看中内在美呢?喜欢娇艳的容颜?还是性感的身材?又或者善良的品质?端庄贤惠?孝敬父母?相夫教子?
3>通过一种算法在待查找的容器中查找对象
4>如果找到,则返回True或者返回对象在列表中的位置
--如果没有找到,则返回False或者-1
5>找到----->学习高阶技巧------->如何和对象相处
--没找到------>继续找?
--换目标?
--换范围?
以下是7种基本的查找算法
1.顺序查找
1>算法思想:
1) 依次遍历数据源,将每一个元素依次与目标对象进行比较
2)若相等,表示查找成功,返回True
3)直到比较完最后一个元素,如果还是没找到,表示查找失败,则返回False
4)如果需要返回元素在列表中的位置,则添加相应的return语句即可
2>代码
def sequential_search(alist,item): # 无序列表
pos = 0
found = False
while pos < len(alist) and not found:
if alist[pos] == item:
found = True
else:
pos += 1
return found--测试用例1
if __name__ == '__main__':
lis1 = ['天使面孔','魔鬼身材','温柔善良','孝顺贤惠','富二代','小众另类']
tag1 = '张曼玉'
tag2 = '小众另类'
print(sequential_search(lis1,tag1)) # >>>查找失败
print(sequential_search(lis1,tag2)) # >>>查找成功3>适用范围
一切:数据源有序,无序.顺序存储,链式存储.
数据源较小
4>效率分析
查找算法的效率主要以平均
1)对于数据源无序的情况
比较次数
| 最好 | 最坏 | 平均 | |
| 存在目标对象 | 1 | n | n/2 |
| 不存在目标对象 | n | n | n |
2)数据源有序的情况
def order_sequential_search(alist,item): # 有序列表
pos = 0
found = False
stop = False
while pos < len(alist) and not found and not stop:
if alist[pos] == item:
found = True
else:
if alist[pos] > item:
stop = True
pos += 1
return found如果列表中某个元素已经大于了目标对象,可以直接结束循环,因为列表有序,后面的元素只可能比目标元素更大.
| 最好 | 最坏 | 平均 | |
| 存在目标对象 | 1 | n | n/2 |
| 不存在目标对象 | 1 | n | n/2 |
综上所述,顺序查找算法的时间复杂度为O(n)
5>简单应用
# 例题1
'''题目描述:
查找列表中第index个和目标单词是异序词的单词
异序词:两个单词所含的字母相同,但字母的顺序不同,则称这两个词为异序词'''
def brother_word(words,target_word,index):
'''异序词'''
res = []
for word in words:
if sorted(word) == sorted(target_word) and word != target_word:
res.append(word)
if index < 0 or index > len(res) -1:
print('index超出范围')
else:
return res[index]
# 例2
def str_search(txt,word):
'''匹配则返回word首字母在txt中的位置'''
i = 0
while i < len(txt) - len(word) + 1:
j = 0
while j < len(word) and txt[i+j] == word[j]:
j += 1
if j == len(word):
return i
i += 1
return -1
# 例3
def two_sum(alist,target):
'''在列表中查找两个元素的和等于目标值'''
for i in range(len(alist)):
for j in range(i+1,len(alist)):
if alist[i] + alist[j] == target:
return (i,j)
if __name__ == '__main__':
# lis = [1,2,3,4,56,7,23,342,3,65,567,577,23,5,4]
# print(seq_search(lis,4))
w = ['abc','bac','cab','bbc','sdd','fgw']
print(brother_word(w,'abc',0))
# print(brother_word(w,'abc',1))
txt = 'i love you'
print(str_search(txt,'love'))
l = [1,2,3,4,5,6,7,8,9,99]
print(two_sum(l,10))2.二分查找
鉴于顺序查找的低效率,如果数据源很少,顺序查找的时间尚能忍受,但是如果数据源很大,找个对象需要用30年的话,显然现实中是无法忍受的,所以找对象的达人开发了更快的查找算法.比如二分查找.
1>适用情况
1)数据源有序
2)数据源顺序存储.
--->因为二分查找需要获取任意下标对应的值
3)不适用数据量太小或者数据量太大
--->因为数据量太小二分查找带来的性能提升无法抵消排序造成的时间复杂度开销
--->而数据量太大,内存没有足够的连续空闲空间进行顺序存储
4)适用于静态数据(没有频繁的数据插入删除操作)
--->顺序存储的局限性
2>算法思想
0)使用中间元素mid将数据源列表分割为左右子区间
1)将列表的中间元素mid和目标对象比较
2)如果相等 --->查找成功
3)mid > 目标元素:
在左区间继续运用二分查找
4)mid < 目标元素:
在右区间继续运用二分查找
3>代码
# 二分查找
def binary_search(alist,item): # 循环版
'''
:param alist: 原始数据必须有序
:param item: 待查找
:return: bool
'''
first = 0 # 首元素指针
last = len(alist)-1 # 尾元素指针
found = False
while first <= last and not found:
mid = (first + last) //2
if alist[mid] == item:
found = True
elif alist[mid] < item:
first = mid + 1
else:
last = mid - 1
return found
def binary_search2(alist,item): # 递归版
if not alist: # 列表为空作为递归边界
return False
mid = len(alist)// 2
if alist[mid] == item:
return True
elif alist[mid] < item:
return binary_search2(alist[mid+1:],item)
else:
return binary_search2(alist[:mid], item)
'''
算法分析:
时间复杂度:O(logn)
对于递归版本,因为切片操作的时间复杂度是O(k),所以达不到O(logn)
但可以通过传递下标的方式改进
'''
def binary_search3(alist,first,last,item): # 递归改进版
if first <= last: # 列表为空作为递归边界
return False
mid = first + last // 2
if alist[mid] == item:
return True
elif alist[mid] < item:
return binary_search3(alist,mid+1,last,item)
else:
return binary_search3(alist,first,mid, item)
if __name__ == '__main__':
lis = list(range(1,100))
# print(binary_search(lis,52))
# print(binary_search(lis,102))
# print(binary_search(lis,-5))
print(binary_search2(lis,43))
print(binary_search2(lis,112))
print(binary_search3(lis,0,len(lis)-1,43))
print(binary_search3(lis,0,len(lis)-1,112))4>应用示例
# 二分查找
'''
适用情况:
1.数据源有序
2.数据源顺序存储.
--->因为二分查找需要获取任意下标对应的值
3.不适用数据量太小或者数据量太大
--->因为数据量太小二分查找带来的性能提升无法抵消排序造成的时间复杂度开销
--->而数据量太大,内存没有足够的连续空闲空间进行顺序存储
4.适用于静态数据(没有频繁的数据插入删除操作)
--->顺序存储的局限性
5.既要获得二分查找的高性能,又要改进无法插入\删除数据的局限性,可以考虑二分查找树的数据结构
复杂度分析:
1.时间
最好:O(1)
最坏和平均:O(logn)
2.空间
O(1)
缺陷:
当待查找数据源中存在重复元素时,只能查找到其中一个元素,无法查找左右边界元素
但可通过修改二分查找代码,完成上述功能
'''
# 循环版
def bin_search(items,key):
start,end = 0,len(items) - 1
while start <= end:
mid = start + (end - start) //2 # 这种写法在下标很大时,可以防止溢出?
if items[mid] == key:
return mid
elif items[mid] > key:
end = mid -1
else:
start = mid + 1
return -1 # 查找失败
# 递归版(不使用切片)
def bin_search_by_recursion(items,start,end,key):
if start > end:
return -1
else:
mid = (start + end)//2
if items[mid] == key:
return mid
elif items[mid] < key:
bin_search_by_recursion(items,mid+1,end,key)
else:
bin_search_by_recursion(items, start, mid-1, key)
# 例题
'''1.查找目标值的左边界
查找与目标值相等的元素,并返回其下标,若有多个相等的元素,则返回第一次出现的
下标,即相同目标元素最左侧的下标位置。
思路分析:
1.改进二分查找
2.当找到目标元素时,进一步考虑mid左边的元素是否和目标值相等
3.需要注意是否mid已经是第0个元素
'''
# 方法1
def left_bin_search(items,key):
start,end = 0,len(items) - 1
while start <= end:
mid = start + (end - start) //2 # 这种写法在下标很大时,可以防止溢出?
if items[mid] == key: # 相等时需要进一步考虑
if mid != 0 and items[mid-1] == key:
end = mid - 1
else:
return mid
elif items[mid] > key:
end = mid -1
else:
start = mid + 1
return -1 # 查找失败
# 方法2
def left_bin_search2(items,key):
start,end = 0,len(items) - 1
while start <= end:
mid = start + (end - start) // 2 # 这种写法在下标很大时,可以防止溢出?
if items[mid] == key: # 相等时需要进一步考虑
index = mid
while items[index-1] == key: # 用一个循环找到最左边相等的值
index -= 1
return index
elif items[mid] > key:
end = mid - 1
else:
start = mid + 1
return -1 # 查找失败
'''2. 查找目标值的右边界
查找与目标值相等的元素,并返回其下标,若有多个相等的元素,则返回最后一次出现
的下标,即相同目标元素最右侧的下标位置。
思路分析:
1.改进二分查找
2.当找到目标元素时,进一步考虑mid右边的元素是否和目标值相等
3.需要注意是否mid已经是最后一个元素,否则会索引错误'''
def right_bin_search(items,key):
start,end = 0,len(items) - 1
while start <= end:
mid = start + (end - start) //2 # 这种写法在下标很大时,可以防止溢出?
if items[mid] == key: # 相等时需要进一步考虑
if mid != len(items) -1 and items[mid+1] == key:
start = mid + 1
else:
return mid
elif items[mid] > key:
end = mid -1
else:
start = mid + 1
return -1 # 查找失败
'''3.查找第一个≥目标值的元素
查找第一个大于等于目标值的元素,若有元素与目标值相等,则查找的是其左边界,若
没有元素与目标值相等,则查找的是第一个大于目标值的元素。
待查找序列为{3, 3, 7, 7, 7, 8, 8},目标元素为 7 时,由于序列中有多个与目标值相等的
元素,因此返回左边界的索引位置,即返回下标 2。
待查找序列为{1, 2, 3, 5, 7, 8, 8},目标元素为 4 时,由于序列中没有与目标值相等的元
素,于是找到第一个大于目标值的元素,即返回下标 3。
待查找序列为{1, 2, 3, 5, 7, 8, 8},目标元素为 9 时,序列中没有大于等于目标值的元素,
返回-1。
思路分析:
1.如果mid >= 目标值
如果mid == 0 或者 mid - 1 < 目标值
返回 mid
否则:
左边找
2.如果mid < 目标值 ,右边找'''
def bnigger(items,key):
start,end = 0,len(items) - 1
while start <= end:
mid = start + (end - start) //2
if items[mid] >= key:
if mid == 0 or items[mid-1] < key:
return mid
else:
end = mid -1
else:
start = mid + 1
return -1 # 查找失败
'''4.查找最后一个小于等于给定值的元素
查找最后一个小于等于目标值的元素,若有元素与目标值相等,则查找的是其右边界,
若没有元素与目标值相等,则查找最后一个小于目标值的元素。
待查找序列为{1, 2, 2, 3, 7, 8, 8},目标元素为 2 时,由于序列中有多个与目标值相等的
元素,因此返回右边界的索引位置,即返回下标 2。'''
def smaller(items,key):
start,end = 0,len(items) - 1
while start <= end:
mid = start + (end - start) //2
if items[mid] <= key:
if mid == len(items) -1 or items[mid+1] > key:
return mid
else:
start = mid +1
else:
end = mid - 1
return -1 # 查找失败
'''5.一个长度为n、无重复元素、按升序排列的数组,经过多次旋转后得到新的数组,
请利用二分查找思想,在新的数组中找到最小值。数组是如何旋转的呢?
数组[1,2,3,4,5]旋转一次的结果为[2,3,4,5,1],旋转两次的结果为[3,4,5,1,2]。
旋转一次是指将数组首位元素移动到末尾。
注意:数组中无重复元素。
输入描述:
输入旋转n次后的数组,数字之间以空格分隔
输出描述:
输出数字中的最小元素
输入示例:
3 4 5 1 2
输出示例:
1
'''
def minNumberInRotateArray(rotateArray):
#最小值 一定比前面的要小
# 二分法查找数据 找左右的方法是:
#右边的值大于中值,就说明最小值在左边
if not rotateArray:
return 0
left = 0
right = len(rotateArray) - 1
while left <= right:
mid = (left + right) >> 1
#如果说中间的数的上一个数 > 中间数,那么就说明,我们要找的数就是这个中间的数,返回这个数。
if rotateArray[mid - 1] > rotateArray[mid]:
return rotateArray[mid]
#如果说中间的数 < 中间数的上一个数,那么就说明,我们要找的数在二分法的左侧,所以右侧取值的索引需要改变为中间的索引-1;因为越往左索引值越小
elif rotateArray[mid] < rotateArray[right]:
right = mid - 1
#否则就说明,我们要找的数在二分法的右侧,所以左侧取值的索引需要改变为中间的索引+1;因为越往右索引值越小
else:
left = mid + 1
return 0
if __name__ == '__main__':
# lis = [1,2,2,2,2,3,5,7,8,9,9,9,9,10,14,15,15,15]
# res = bin_search(lis,7)
# print(res)
# res = bin_search_by_recursion(lis,0,len(lis)-1,7)
# print(res)
# print(left_bin_search(lis,9))
# print(left_bin_search2(lis,9))
# print(right_bin_search(lis,9))
# print(right_bin_search(lis,9))
# print(right_bin_search(lis,15))
# print(right_bin_search(lis,2))
# print(bnigger(lis,2))
# print(bnigger(lis,16))
# print(smaller(lis,16))
# print(smaller(lis,2))
# print(smaller(lis,9))
lis = [4,4,5,5,3,3]
print(minNumberInRotateArray(lis))5>二分查找的两种变体
--斐波那契查找
# 斐波那契查找
'''
算法思想:
1.二分查找的变体
2.分割的时候不以中点分割,而是以黄金比例分割
3.步骤:
1>产生斐波那契数列的列表
2>为了使待查找数列满足斐波那契数列的性质,扩充待查找的源数列
选取k值:使得k满足 f(k) - 1 >= n(源数列长度)
将源数列扩充到f(k) - 1位,即将源数列的最后一个元素复制(f(k) -1 -n)次
为什么扩充为f(k) - 1?
为了将分割点踢出来,f(k) - 1 = [f(k-1) -1] + 1 + [f(k-2) -1]
3>计算分割点 split_point = start + f(k-1) -1 即起始下标加上左边序列的长度
分割后的数列大约是这个样子:[f(k-1) -1] + split_point + [f(k-2) -1]
4>比较分割点的值和目标值:
1)相等 查找成功
如果split_point < n:
return split_point
else:
return n -1
2)分割点 < 目标值
start = split_point + 1
k = k - 2
3)分割点 > 目标值
k = k - 1
end = split_point -1 # 因为计算分割点的值的时候,并不使用end的值,这一步是否可以省略?.但end需要用来控制循环结束
适用情况:
1.数据源有序
2.数据源顺序存储.
--->因为斐波那契查找需要获取任意下标对应的值
3.不适用数据量太小或者数据量太大
--->因为数据量太小斐波那契查找带来的性能提升无法抵消排序造成的时间复杂度开销
--->而数据量太大,内存没有足够的连续空闲空间进行顺序存储
4.适用于静态数据(没有频繁的数据插入删除操作)
--->顺序存储的局限性
5.既要获得二分查找的高性能,又要改进无法插入\删除数据的局限性,可以考虑二分查找树的数据结构
复杂度分析:
1.时间
最好:O(1)
最坏和平均:O(logn)
2.空间
O(n): 扩充数列占用的空间
3.和二分查找的对比:
1>最坏情况查找效率低于二分查找
分割不均匀
2>平均情况查找效率优于二分查找
计算分割点时,不需要计算除法,'''
def fibnacci(n):
'''斐波那契数列'''
arr = [1,1]
i = 2
while i <= n:
arr.append(arr[i-1] + arr[i-2])
i += 1
return arr
def fib_search(alist,item):
n = len(alist)
fib_arr = fibnacci(n)
# 计算k
k = 0
while fib_arr[k]-1 < n:
k += 1
# 扩充数组
ex_arr = alist + [alist[n-1]]*(fib_arr[k]-1-n)
# 查找
start = 0
end = n-1
while start <= end:
spilt_point = start + fib_arr[k-1] - 1
if ex_arr[spilt_point] == item:
if spilt_point < n:
return spilt_point
else:
return n-1
elif ex_arr[spilt_point] < item:
start = spilt_point + 1
k = k - 2
else:
end = spilt_point -1
k = k - 1
return -1
if __name__ == '__main__':
f = fibnacci(8)
print(f)
lis = [0,1,1,1,2,2,2,3,4,5,5,5,5,6,7,8,9,10]
for i in range(13):
print(fib_search(lis,i))
--插值查找
# 插值查找
'''
算法思想:
1.二分查找的变体
2.分割的时候不以中点分割,而是根据待查找值动态调整分割点的位置
3.步骤:
1>用start.end标识查找表的首尾,假设带查找的元素为key
2>计算分割点split_point,
使得split_point = start + int((key-items[start])/(items[end]-items[start])*(end-start))
3>比较分割点对应的元素items[split_point]和key的大小:
1)如果items[split_point]>key:
end = split_point - 1
2)如果items[split_point]<key:
start = split_point + 1
3)如果items[split_point]=key:
返回split_point
4>直到start>end:
返回: 查找失败
适用情况:
1.数据源有序
2.数据源顺序存储.
--->因为插值查找需要获取任意下标对应的值
3.适用于均匀分布的查找表
如
均匀:[10,20,30,40,50,60,70,80,90,100]
不均匀[10,10,10,10,90,99,100]
复杂度分析:
1.时间
平均:O(log(log n))
最坏:O(n) # 当查找表不是均匀分布的时候
2.空间
O(1)
'''
def interpolation_search(items,key):
start,end = 0,len(items) - 1
count = 0 # 统计次数
while start <= end:
split_point = start + int((key-items[start])/(items[end]-items[start])*(end-start))
count += 1
if items[split_point] < key:
start = split_point + 1
elif items[split_point] > key:
end = split_point - 1
else:
return split_point,count
return (-1,count)
def bin_search(items,key):
start,end = 0,len(items) - 1
count = 0
while start <= end:
mid = start + (end - start) //2 # 这种写法在下标很大时,可以防止溢出?
count += 1
if items[mid] == key:
return mid,count
elif items[mid] > key:
end = mid -1
else:
start = mid + 1
return -1,count # 查找失败
if __name__ == '__main__':
lis = list(range(10,301,5))
res = interpolation_search(lis,88)
print("被查找的元素位于{},共计比较{}次".format(res[0],res[1]))
res1 = bin_search(lis,88)
print("被查找的元素位于{},共计比较{}次".format(res1[0],res1[1]))
斐波那契查找和插值查找同二分查找的主要区别是分割数据源的方法不同,二分查找每次以中点分割,斐波那契以黄金比例分割,而插值查找则是按比例分割.
3.分块查找
分块查找也叫索引查找,原理是先将数据源分块,之后建立索引.索引维护一个每块起始地址和该块元素的最大值或者最小值.块和块之间有序,快内数据无序.查找时可利用顺序或者二分查找先找到目标元素所对应的快,然后在快内应用顺序查找查找目标元素.
def seq_search(alist,item):
'''简单顺序查找'''
for i in range(len(alist)-1):
if alist[i] == item:
return i
return -1
def bin_search(items,key):
'''二分查找'''
start,end = 0,len(items) - 1
while start <= end:
mid = start + (end - start) //2 # 这种写法在下标很大时,可以防止溢出?
if items[mid] == key:
return mid
elif items[mid] > key:
end = mid -1
else:
start = mid + 1
return -1 # 查找失败
def block_search(alist,block_num,target):
'''分块查找'''
# 1.分块
index_list,div_block_list = div_block(alist,block_num)
print(index_list)
print(div_block_list)
# 2.查找块号
block_id = 0
for index in index_list:
if target <= index[1]:
block_id = index_list.index(index)
print('如果待查找元素{}存在,则位于第{}块'.format(target,block_id))
break
# 3.块内查找
res = seq_search(div_block_list[block_id],target) # 直接调用顺序查找
if res != -1:
print('元素{}查找成功,位于第{}块,第{}个位置'.format(target,block_id,res))
else:
print('查找失败')
def div_block(alist,block_num):
'''
alist : 数据源存放的列表 形如[1,2,6,3,5,9,15,18,13,16,19,22,25,21]
block_num : 需要划分的块数
return : 分好块的二维列表
index_list:索引表 该列表的元素为(index,max)这样的二元组,分别代表本快起始位置和本块最大元素'''
list_max_ele = max(alist)
list_lengh = len(alist)
# 构造索引表 index_list
index_list = [[] for _ in range(block_num)]
# 确定各个块的起始地址和最大元素
for i in range(block_num):
index_list[i].append(i*(list_lengh//block_num)) # 添加本块的起始索引
# 添加本块的最大元素
if i == block_num - 1:
index_list[i].append(list_max_ele)
else:
index_list[i].append(list_max_ele * (i+1) // block_num)
# print(index_list)
# 按索引表对原列表进行分块
res = []
for key in index_list:
sub_list = []
# for i in range(list_lengh-1): # 本段代码因为不停的在删除alist的元素,导致index错误
# if alist[i] <= key[1]:
# tmp = alist.pop(i)
# sub_list.append(tmp)
# res.append(sub_list)
for ele in alist[:]: # 遍历的时候通过alist的浅复制来遍历,将alist中的所有元素分配到分块的二维列表中
if ele <= key[1]:
sub_list.append(ele)
# print(sub_list)
alist.remove(ele)
res.append(sub_list)
# print('alist:',alist)
return index_list,res
if __name__ == '__main__':
import random
lis = [28, 15, 2, 25, 21, 16, 6, 22, 13, 5, 9, 29, 1, 3, 18, 19]
print(len(lis))
# random.shuffle(lis)
# print(lis)
# print(div_block(lis,3))
block_search(lis,3,17)
索引表的第一个元素,起始位置这里暂时没用上,本算法还有较多需要改进的地方.
需改进的地方:
1.索引表的第一个元素和数据源alist之间的映射关系
2.使用二分查找确定块号
4.哈希查找
哈希查找这在哈希表上进行查找的一种算法.该算法比二分查找更有效率,在理想的不存在冲突的哈希表中查找数据的时间复杂度能达到O(1),即常数时间复杂度,就像是找对象的时候,根本不需要比较,就能直接从数据对象的集合中一眼挑出你心仪的那个对象,这就叫做一见钟情.
武侠小说告诉我们越是厉害的武功,对习练者的要求也越高.放在查找算法这件事上也一样.顺序查找对带查找数据源没有任何要求,有序/无序/顺序存储/链式存储都可以,二分查找的前提条件是数据源有序,而哈希查找的前提条件是必须将数据源存放在一个哈希表中.
1>构造哈希表(散列表)
1)哈希函数
哈希函数是将待存储的元素映射到存储地址空间的一种函数.简单来说就是把要存储的值通过一个函数的变换得到的函数值,即为存储空间地址.比如要将以下数据元素存入哈希表,首先在内
存开辟一块000-009的存储空间,选取一个哈希函数,本例使用取模函数.然后计算每个数据的哈希函数值,并将其存入对应的地址.
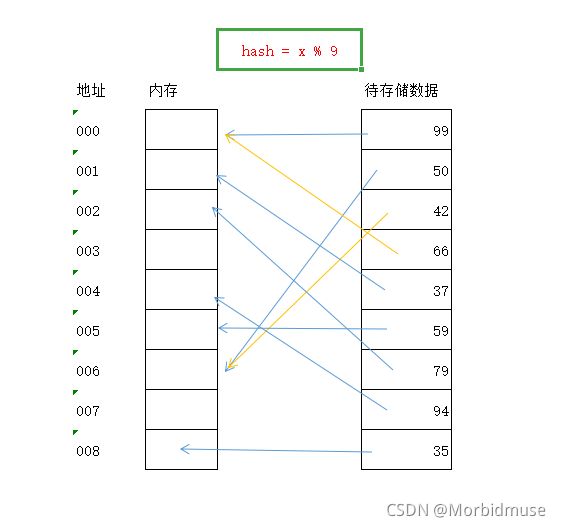
上图中黄色箭头表示两个或者二个以上的关键字映射到了一个地址,这被称为冲突.后续解释冲突的解决办法.
这样存储的好处是显而易见的,当需要查询元素的时候,我们无须一次比对元素的值,而只需将元素的值运行一次哈希函数,得到的结果就是该元素存放的位置.
2)哈希函数选取的原则
A.计算简单
B.尽可能减少冲突
2>示例
# 散列表
'''
1.其中的元素以一种便于查找的方式存贮
2.散列函数
0>完美散列函数
给定一个元素集合,能将每一个元素映射到不同的槽
1>常见散列函数
取余函数
折叠法:4365554601
分段 436-555-460-001
相加 1452 也可首尾相加
取余 假设有11个槽 1452 % 11
平方取中:取元素的平方的中间几位
字符串的ascii码最为散列值
3.载荷因子
元素个数/散列表的大小
4.冲突
两个元素的散列值相等称为冲突
5.冲突处理
1>开放定址
1)线性探测
如冲突,则依次遍历列表,直到找到空槽,则插入
缺点:元素聚集
2)再散列
rehash(pos) = (pos + skip) % tablesize
3)平方探测
skip(步长)不固定 取平方 如h+1,h+4,h+9....
2>拉链法
同一个位置可以存多个元素,使用链表的方式存储
但如果一个槽的链表过长,降低查找效率
6.散列表搜索算法分析: 时间复杂度: O(1)
lambda(载荷因子) = 元素个数/散列表的大小
比较次数(线性探测)
最好 最坏 普通情况
存在目标元素 \ \ 1/2(1+1/(1-lambda)
不存在目标元素 \ \ 1/2(1+(1/(1-lambda)**2))
比较次数(拉链法)
最好 最坏 普通情况
存在目标元素 \ \ 1+lambda/2
不存在目标元素 \ \ lambda
'''
def hash(astring,table_size):
'''
以字符串的ascii码来作为哈希函数
:param astring:
:param table_size: 散列表长
:return: 哈希值
'''
return sum([ord(x) for x in astring]) % table_size
# 以上方法对于异序词计算会得到相同的哈希值
# 改进: 对每一位增加权重
def hash1(astring,table_size):
return sum([ord(x)*i for x,i in zip(astring ,range(1,len(astring)+1))] ) % table_size
if __name__ == '__main__':
# print(hash('about',7))
# print(hash('hero',7))
# print(hash('asshole',7))
print(hash1('asshole',7))
print(hash1('abc',7))
print(hash1('bac',7))
3>用散列表模拟字典
'''
映射:将键和值关联起来的无序集合
键不能重复
键和值一一对应
操作:
map():创建空映射
put(key,value):加入新的键值对
get(key):返回key对应的value
del map(key):删除键值对
len():返回键值对的数目
in:通过 key in map 这样的语句在key存在时返回True,否则...
实例:python中的dict
散列表搜索算法分析:
时间复杂度: O(1)
'''
class HashTable:
def __init__(self):
self.size = 11 # 长度
self.slots = [None] * self.size # 保存键
self.datas = [None] * self.size # 保存值
def hash_function(self, key, size):
return key % size
def rehash(self, oldhash, size):
return (oldhash + 1) % size
def put(self, key, value):
hash_value = self.hash_function(key, self.size)
if self.slots[hash_value] == None: # 键不存在,直接插入
self.slots[hash_value] = key
self.datas[hash_value] = value
else:
if self.slots[hash_value] == key: # 键已经存在,替换值
self.datas[hash_value] = value
else: # 处理冲突
next_slot = self.rehash(hash_value, self.size)
while self.slots[next_slot] != None and self.slots[next_slot] != key: # 直到找到下一个空槽或者值为key的槽
next_slot = self.rehash(next_slot, self.size)
if self.slots[next_slot] == None:
self.slots[next_slot] = key
self.datas[next_slot] = value
else:
self.datas[next_slot] = value
# def get(self,key): # 自己写的
# hash_value = self.hash_function(key,self.size)
# if self.slots[hash_value] == None:
# return '键{}不存在'.format(key)
# else:
# if self.slots[hash_value] == key:
# return self.datas[hash_value]
# else:
# next_slot = self.rehash(hash_value, self.size)
# while self.slots[next_slot] != None and self.slots[next_slot] != key: # 直到找到下一个空槽或者值为key的槽
# next_slot = self.rehash(next_slot, self.size)
# if next_slot == None:
# return '键{}不存在'.format(key)
# else:
# return self.datas[next_slot]
def get(self, key): # 老师写的
start_slot = self.hash_function(key, len(self.slots))
data = None
stop = False
found = False
pos = start_slot
while self.slots[pos] != None and \
not found and not stop:
if self.slots[pos] == key:
found = True
data = self.datas[pos]
else:
pos = self.rehash(pos, len(self.slots))
if pos == start_slot: # 回到start说明没找到
stop = True
return data
def __getitem__(self, key):
return self.get(key)
def __setitem__(self, key, value):
self.put(key,value)
def __delitem__(self, key):
if key in self.slots:
self.slots[self.slots.index(key)] = None
self.datas[self.slots.index(self[key])] = None
else:
raise KeyError
def __len__(self):
return sum([1 for x in self.slots if x is not None])
def __contains__(self, key):
return key in self.slots
if __name__ == '__main__':
dic1 = HashTable()
dic1.put(23, '张三')
dic1.put(5, '李四')
dic1.put(44, '王二麻子')
dic1.put(55, '宝气')
print(dic1.slots)
print(dic1.datas)
print(dic1.get(14))
print(dic1.get(44))
print(dic1.get(55))
print(dic1[23])
dic1[78] = '白水'
print(dic1[78])
print(dic1.slots)
print(dic1.datas)
del dic1[78]
print(dic1.slots)
print(dic1.datas)
print(len(dic1))
print(78 in dic1)
5.树形查找
前面说到了二分查找的效率是O(logn),和顺序查找相比,在效率上有很好的提升,但是二分查找有一个局限,即要求待查找的数据源使用顺序存储.但顺序存储就会产生插入\删除数据效率低下的问题.所以一般二分查找更适合不常进行修改的静态数据,那么既想获得二分查找的高效性,又有动态增删数据的需求,怎么办呢?答案就是二叉查找树.
'''
二叉搜素性:
1.小于父节点的键都在左子树
2.大于父节点的键都在右子树
'''
class BinarySearchTree:
def __init__(self):
self.root = None
self.size = 0
def length(self):
return self.size
def __len__(self):
return self.size
def __iter__(self):
return self.root.__iter__()
def put(self,key,val):
if self.root:
self.__put(key,val,self.root)
else:
self.root = TreeNode(key,val)
self.size += 1
def __put(self,key,val,currentNode):
if key < currentNode.key:
if currentNode.hasLeftChild():
self.__put(key,val,currentNode.leftChild)
else:
currentNode.leftChild = TreeNode(key,val,parent=currentNode)
elif key == currentNode.key: # 处理键相同的情况,使用新的val替换原来的值
currentNode.payload = val
else:
if currentNode.hasRightChild():
self.__put(key,val,currentNode.rightChild)
else:
currentNode.rightChild = TreeNode(key,val,parent=currentNode)
def __setitem__(self, key, value):
self.put(key,value)
def get(self,key):
if self.root:
res = self.__get(key,self.root)
if res:
return res.payload
else:
return None
else:
return None
def __get(self,key,currentNode):
if not currentNode:
return None
elif currentNode.key == key:
return currentNode # 返回的是节点
elif key < currentNode.key:
return self.__get(key,currentNode.leftChild)
else:
return self.__get(key,currentNode.rightChild)
def __getitem__(self, key):
return self.get(key)
def __contains__(self, key):
if self.get(key):
return True
else:
return False
def delete(self,key):
if self.size > 1: # 树中不止一个节点
nodeToRemove = self.__get(key,self.root)
if nodeToRemove:
self.remove(nodeToRemove)
self.size -= 1
else:
raise KeyError('error,key not in tree')
elif self.size == 1 and self.root.key == key: # 移除根节点
self.root = None
self.size -= 1
else:
raise KeyError('error,key not in tree')
def __delitem__(self, key):
self.delete(key)
def remove(self,currentNode):
'''分三种情况:
1.待删除节点没有儿子
直接删除该节点,并移除父节点对其的引用
2.待删除节点有一个子节点
1>当前节点有左儿子
1)当前节点是左儿子
a)当前节点的左儿子的父亲指向当前节点的父亲
b)当前节点的父亲的左儿子指向当前节点的左儿子
2)当前节点是右儿子
a)当前节点的左儿子的父亲指向当前节点的父亲
b)当前节点的父亲的右儿子指向当前节点的左儿子
3)当前节点没有父亲
用当前节点的左儿子的信息来替换当前节点
2>当前节点有右儿子
1)当前节点是左儿子
a)当前节点的右儿子的父亲指向当前节点的父亲
b)当前节点的父亲的左儿子指向当前节点的右儿子
2)当前节点是右儿子
a)当前节点的右儿子的父亲指向当前节点的父亲
b)当前节点的父亲的右儿子指向当前节点的右儿子
3)当前节点没有父亲
用当前节点的右儿子的信息来替换当前节点
3.有两个子节点
1>查找次大键节点 后继节点 nextNode
2>移除后继节点
因为后继节点要么是叶子节点,要么只有右儿子,所以可用前两种情况来移除这个节点
3>将后继节点的key和payload复制到当前节点'''
if currentNode.isLeaf(): # 情况1
if currentNode.parent.leftChild ==currentNode:
currentNode.parent.leftChild = None
else:
currentNode.parent.rightChild = None
elif currentNode.hasBothchildren():
succ = currentNode.findSuccessor()
succ.spliceOut()
currentNode.key = succ.key
currentNode.payload = succ.payload
else: # 情况2
if currentNode.hasLeftChild(): # 1>
if currentNode.isLeftChild(): # 1)
currentNode.leftChild.parent = currentNode.parent # a)
currentNode.parent.leftChild = currentNode.leftChild # b)
elif currentNode.isRightChild():
currentNode.leftChild.parent = currentNode.parent # a)
currentNode.parent.rightChild = currentNode.leftChild # b)
else:
currentNode.replaceNodeData(currentNode.leftChild.key,
currentNode.leftChild.payload,
currentNode.leftChild.leftChild,
currentNode.leftChild.rightChild)
else:
if currentNode.isLeftChild():
currentNode.rightChild.parent = currentNode.parent
currentNode.parent.leftChild = currentNode.rightChild
elif currentNode.isRightChild():
currentNode.rightChild.parent = currentNode.parent
currentNode.parent.rightChild = currentNode.rightChild
else:
currentNode.replaceNodeData(currentNode.rightChild.key,
currentNode.rightChild.payload,
currentNode.rightChild.leftChild,
currentNode.rightChild.rightChild)
class TreeNode:
def __init__(self,key,val,left = None,right = None,parent = None):
self.key = key
self.payload = val # 有效荷载
self.leftChild = left
self.rightChild = right
self.parent = parent # 父节点
self.balanceFactor = 0
def hasLeftChild(self):
return self.leftChild
def hasRightChild(self):
return self.rightChild
def isLeftChild(self):
return self.parent and \
self.parent.leftChild == self
def isRightChild(self):
return self.parent and \
self.parent.rightChild == self
def isRoot(self):
return not self.parent
def isLeaf(self):
return not (self.leftChild or self.rightChild)
def hasAnyChildren(self):
return self.leftChild or self.rightChild
def hasBothchildren(self):
return self.leftChild and self.rightChild
def replaceNodeData(self,key,value,lc,rc):
self.key = key
self.payload = value
self.leftChild = lc
self.rightChild = rc
if self.hasLeftChild():
self.leftChild.parent = self
if self.hasRightChild():
self.rightChild.parent = self
def findSuccessor(self):
'''
后继节点:
1.如果当前节点有右儿子,则其后继节点为右子树中最小的节点
2.如果没有右儿子,且当前节点是父节点的左儿子,则后继节点为父节点
且当前节点时父节点的右儿子,则后继节点为除其本身以外的父节点的后继节点'''
succ = None
if self.hasRightChild():
succ = self.rightChild.findMin()
else:
if self.parent:
if self.isLeftChild():
succ = self.parent
else:
self.parent.rightChild = None
succ = self.parent.findSuccessor()
self.parent.rightChild = self
return succ
def findMin(self):
current = self
while current.hasLeftChild():
current = current.leftChild
return current
def spliceOut(self):
if self.isLeaf(): # 情况1
if self.isLeftChild():
self.parent.leftChild = None
else:
self.parent.rightChild = None
elif self.hasAnyChildren(): # 情况2
if self.hasLeftChild():
if self.isLeftChild():
self.parent.leftChild = self.leftChild
else:
self.parent.rightChild = self.leftChild
self.leftChild.parent = self.parent
else:
if self.isLeftChild():
self.parent.leftChild = self.rightChild
else:
self.parent.rightChild = self.rightChild
self.rightChild.parent = self.parent
def __iter__(self):
if self:
if self.hasLeftChild():
for ele in self.leftChild:
yield ele
yield self.key
if self.hasRightChild():
for ele in self.rightChild:
yield ele
if __name__ == '__main__':
my_tree = BinarySearchTree()
my_tree.put(70,'A')
my_tree.put(31,'B')
my_tree.put(93,'C')
my_tree.put(14,'D')
my_tree.put(73,'E')
my_tree.put(120,'F')
my_tree.put(23,'G')
my_tree[8] = 'H'
# print(my_tree[14])
# print(my_tree[23])
# print(my_tree[21])
# print(my_tree[73])
# print(120 in my_tree)
# print(321 in my_tree)
def inOrder(treeRoot):
if treeRoot:
inOrder(treeRoot.leftChild)
print(treeRoot.key)
inOrder(treeRoot.rightChild)
# inOrder(my_tree.root)
# print('================')
# del my_tree[14]
# inOrder(my_tree.root)
# print('================')
for i in my_tree:
print(i)
二叉查找树在树平衡的时候性能接近二分查找,但在不平衡的树中性能退化为单链表的查找
所以平衡二叉查找树(AVL)有应运而生.
from pythonds import BinarySearchTree
class AVLTree(BinarySearchTree):
def __put(self , key , val , currentNode):
'''重载__put,添加节点时更新平衡因子
平衡因子 = 左子树的高度 - 右子树的高度'''
if key < currentNode.key:
if currentNode.hasLeftChild():
self.__put(key,val,currentNode.leftChild)
else:
currentNode.leftChild = TreeNode(key,val,parent=currentNode)
self.updateBalance(currentNode.leftChild)
elif key == currentNode.key: # 处理键相同的情况,使用新的val替换原来的值
currentNode.payload = val
else:
if currentNode.hasRightChild():
self.__put(key,val,currentNode.rightChild)
else:
currentNode.rightChild = TreeNode(key,val,parent=currentNode)
self.updateBalance(currentNode.rightChild)
def updateBalance(self,node):
'''更新平衡因子
1.如果当前节点需要再平衡,则调用rebalance再平衡,不需要更新父节点
2.如果存在父节点:
1>如果当前节点是左儿子:
父节点的平衡因子+1
2>如果当前节点是右儿子:
父节点平衡因子-1
3.如果父节点的平衡因子不为0,递归更新父节点,直到根节点'''
if node.balanceFactor > 1 or node.balanceFactor < -1:
self.rebalance(node)
return
if node.parent != None:
if node.isLeftChild():
node.parent.balanceFactor += 1
elif node.isRightChild():
node.parent.balcnceFactor -= 1
if node.parent.balcnceFactor != 0:
self.updateBalance(node.parent)
def rotateLeft(self,rotRoot):
'''左旋
1.将右子节点提升为子树的根节点
2.将旧根节点作为新根节点的左儿子
3.如果新根节点已经有一个左子节点,则将其作为新左子节点的右子节点'''
newRoot = rotRoot.rightChild
# 处理新根节点的左子节点
rotRoot.rightChild = newRoot.leftChild
if newRoot.leftChild != None:
newRoot.leftChild.parent = rotRoot
# 处理新根
newRoot.parent = rotRoot.parent
if rotRoot.isRoot():
self.root = newRoot
else:
if rotRoot.isLeftChild():
rotRoot.parent.leftChild = newRoot
else:
rotRoot.parent.rightChild = newRoot
# 处理新根和旧根
newRoot.leftChild = rotRoot
rotRoot.parent = newRoot
# 更新平衡因子
rotRoot.balanceFactor = rotRoot.balanceFactor + 1 - min(newRoot.balanceFactor ,0)
newRoot.balanceFactor = newRoot.balanceFactor + 1 -max(rotRoot.balanceFactor,0)
def rotateRight(self, rotRoot):
'''右旋
1.将右子节点提升为子树的根节点
2.将旧根节点作为新根节点的左儿子
3.如果新根节点已经有一个左子节点,则将其作为新左子节点的右子节点'''
newRoot = rotRoot.leftChild
# 处理新根节点的左子节点
rotRoot.leftChild = newRoot.rightChild
if newRoot.rightChild != None:
newRoot.rightChild.parent = rotRoot
# 处理新根
newRoot.parent = rotRoot.parent
if rotRoot.isRoot():
self.root = newRoot
else:
if rotRoot.isLeftChild():
rotRoot.parent.leftChild = newRoot
else:
rotRoot.parent.rightChild = newRoot
# 处理新根和旧根
newRoot.rightChild = rotRoot
rotRoot.parent = newRoot
# 更新平衡因子
rotRoot.balanceFactor = rotRoot.balanceFactor - 1 - max(newRoot.balanceFactor, 0)
newRoot.balanceFactor = newRoot.balanceFactor - 1 + min(rotRoot.balanceFactor, 0)
def rebalance(self,node):
'''再平衡
1.如果子树需要左旋:
1>先检查右儿子的平衡因子
如果右子树左倾,对右子树做一次右旋
2>原节点做一次左旋
2.如果子树需要右旋:
1>先检查左儿子的平衡因子
如果左子树右倾,对右子树做一次左旋
2>原节点做一次右旋
'''
if node.balanceFactor < 0 :
if node.rightChild.balanceFactor > 0:
self.rotateRight(node.rightChild)
self.rotateLeft(node)
else:
self.rotateLeft(node)
elif node.balanceFactor > 0 :
if node.leftChild.balanceFactor < 0:
self.rotateLeft(node.leftChild)
self.rotateRight(node)
else:
self.rotateRight(node)
if __name__ == '__main__':
my_avl = AVLTree()
my_avl.put(70,'A')
my_avl.put(31,'B')
my_avl.put(93,'C')
my_avl.put(14,'D')
my_avl.put(73,'E')
my_avl.put(120,'F')
my_avl.put(8,'G')
my_avl.put(23,'H')
my_avl.put(7,'I')
for i in my_avl:
print(i)
x = my_avl.root.leftChild.balanceFactor
print(x)好了,7种查找算法介绍完了,那么你能找到对象了吗?
等等,对象哪有代码可爱?是吧,哈哈哈.
参考:
1.布拉德利.米勒 戴维.拉努姆<<pythons数据结构与算法分析>>(第二版)
2.dingdangcode刁老师数据结构与算法课程
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









