








【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
在深度学习中,经常使用卷积神经网络(CNN)或循环神经网络(RNN)对序列进行编码。想象一下,有了注意力机制之后,我们将词元序列输入注意力池化中,以便同一组词元同时充当查询、键和值。具体来说,每个查询都会关注所有的键-值对并生成一个注意力输出。由于查询、键和值来自同一组输入,因此被称为自注意力(self-attention),也被称为内部注意力(intra-attention)。本节将使用自注意力进行序列编码,以及如何使用序列的顺序作为补充信息。
import math
import torch
from torch import nn
from d2l import torch as d2l
一、自注意力
给定一个由词元组成的输入序列
x
1
,
…
,
x
n
\mathbf{x}_1, \ldots, \mathbf{x}_n
x1,…,xn,其中任意
x
i
∈
R
d
\mathbf{x}_i \in \mathbb{R}^d
xi∈Rd(
1
≤
i
≤
n
1 \leq i \leq n
1≤i≤n)。该序列的自注意力输出为一个长度相同的序列
y
1
,
…
,
y
n
\mathbf{y}_1, \ldots, \mathbf{y}_n
y1,…,yn,其中:
y
i
=
f
(
x
i
,
(
x
1
,
x
1
)
,
…
,
(
x
n
,
x
n
)
)
∈
R
d
(1)
\mathbf{y}_i = f(\mathbf{x}_i, (\mathbf{x}_1, \mathbf{x}_1), \ldots, (\mathbf{x}_n, \mathbf{x}_n)) \in \mathbb{R}^d \tag{1}
yi=f(xi,(x1,x1),…,(xn,xn))∈Rd(1) 根据
f
(
x
)
=
∑
i
=
1
n
α
(
x
,
x
i
)
y
i
f(x) = \sum\limits_{i=1}^n \alpha(x, x_i) y_i
f(x)=i=1∑nα(x,xi)yi中定义的注意力汇聚函数
f
f
f。下面的代码片段是基于多头注意力对一个张量完成自注意力的计算,张量的形状为(批量大小,时间步的数目或词元序列的长度,
d
d
d)。输出与输入的张量形状相同。
num_hiddens, num_heads = 100, 5
attention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens, num_hiddens, num_heads, 0.5)
attention.eval()

batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
attention(X, X, X, valid_lens).shape
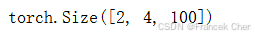
二、比较卷积神经网络、循环神经网络和自注意力
接下来比较下面几个架构,目标都是将由 n n n个词元组成的序列映射到另一个长度相等的序列,其中的每个输入词元或输出词元都由 d d d维向量表示。具体来说,将比较的是卷积神经网络、循环神经网络和自注意力这几个架构的计算复杂性、顺序操作和最大路径长度。请注意,顺序操作会妨碍并行计算,而任意的序列位置组合之间的路径越短,则能更轻松地学习序列中的远距离依赖关系。

考虑一个卷积核大小为 k k k的卷积层。在后面的章节将提供关于使用卷积神经网络处理序列的更多详细信息。目前只需要知道的是,由于序列长度是 n n n,输入和输出的通道数量都是 d d d,所以卷积层的计算复杂度为 O ( k n d 2 ) \mathcal{O}(knd^2) O(knd2)。如图1所示,卷积神经网络是分层的,因此为有 O ( 1 ) \mathcal{O}(1) O(1)个顺序操作,最大路径长度为 O ( n / k ) \mathcal{O}(n/k) O(n/k)。例如, x 1 \mathbf{x}_1 x1和 x 5 \mathbf{x}_5 x5处于图1中卷积核大小为3的双层卷积神经网络的感受野内。
当更新循环神经网络的隐状态时, d × d d \times d d×d权重矩阵和 d d d维隐状态的乘法计算复杂度为 O ( d 2 ) \mathcal{O}(d^2) O(d2)。由于序列长度为 n n n,因此循环神经网络层的计算复杂度为 O ( n d 2 ) \mathcal{O}(nd^2) O(nd2)。根据图1,有 O ( n ) \mathcal{O}(n) O(n)个顺序操作无法并行化,最大路径长度也是 O ( n ) \mathcal{O}(n) O(n)。
在自注意力中,查询、键和值都是 n × d n \times d n×d矩阵。考虑 s o f t m a x ( Q K ⊤ d ) V ∈ R n × v \mathrm{softmax}\left(\frac{\mathbf Q \mathbf K^\top }{\sqrt{d}}\right) \mathbf V \in \mathbb{R}^{n\times v} softmax(dQK⊤)V∈Rn×v中缩放的“点-积”注意力,其中 n × d n \times d n×d矩阵乘以 d × n d \times n d×n矩阵。之后输出的 n × n n \times n n×n矩阵乘以 n × d n \times d n×d矩阵。因此,自注意力具有 O ( n 2 d ) \mathcal{O}(n^2d) O(n2d)计算复杂性。正如在图1中所讲,每个词元都通过自注意力直接连接到任何其他词元。因此,有 O ( 1 ) \mathcal{O}(1) O(1)个顺序操作可以并行计算,最大路径长度也是 O ( 1 ) \mathcal{O}(1) O(1)。
总而言之,卷积神经网络和自注意力都拥有并行计算的优势,而且自注意力的最大路径长度最短。但是因为其计算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。
三、位置编码
在处理词元序列时,循环神经网络是逐个的重复地处理词元的,而自注意力则因为并行计算而放弃了顺序操作。为了使用序列的顺序信息,通过在输入表示中添加位置编码(positional encoding)来注入绝对的或相对的位置信息。位置编码可以通过学习得到也可以直接固定得到。接下来描述的是基于正弦函数和余弦函数的固定位置编码。
假设输入表示
X
∈
R
n
×
d
\mathbf{X} \in \mathbb{R}^{n \times d}
X∈Rn×d包含一个序列中
n
n
n个词元的
d
d
d维嵌入表示。位置编码使用相同形状的位置嵌入矩阵
P
∈
R
n
×
d
\mathbf{P} \in \mathbb{R}^{n \times d}
P∈Rn×d输出
X
+
P
\mathbf{X} + \mathbf{P}
X+P,矩阵第
i
i
i行、第
2
j
2j
2j列和
2
j
+
1
2j+1
2j+1列上的元素为:
p
i
,
2
j
=
sin
(
i
1000
0
2
j
/
d
)
p
i
,
2
j
+
1
=
cos
(
i
1000
0
2
j
/
d
)
(2)
\begin{aligned} p_{i, 2j} &= \sin\left(\frac{i}{10000^{2j/d}}\right) \\p_{i, 2j+1} &= \cos\left(\frac{i}{10000^{2j/d}}\right) \end{aligned} \tag{2}
pi,2jpi,2j+1=sin(100002j/di)=cos(100002j/di)(2)
乍一看,这种基于三角函数的设计看起来很奇怪。在解释这个设计之前,让我们先在下面的PositionalEncoding类中实现它。
#@save
class PositionalEncoding(nn.Module):
"""位置编码"""
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的P
self.P = torch.zeros((1, max_len, num_hiddens))
X = torch.arange(max_len, dtype=torch.float32).reshape(-1, 1) / torch.pow(10000, torch.arange(
0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = torch.cos(X)
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].to(X.device)
return self.dropout(X)
在位置嵌入矩阵 P \mathbf{P} P中,行代表词元在序列中的位置,列代表位置编码的不同维度。从下面的例子中可以看到位置嵌入矩阵的第 6 6 6列和第 7 7 7列的频率高于第 8 8 8列和第 9 9 9列。第 6 6 6列和第 7 7 7列之间的偏移量(第 8 8 8列和第 9 9 9列相同)是由于正弦函数和余弦函数的交替。
encoding_dim, num_steps = 32, 60
pos_encoding = PositionalEncoding(encoding_dim, 0)
pos_encoding.eval()
X = pos_encoding(torch.zeros((1, num_steps, encoding_dim)))
P = pos_encoding.P[:, :X.shape[1], :]
d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)',
figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)])
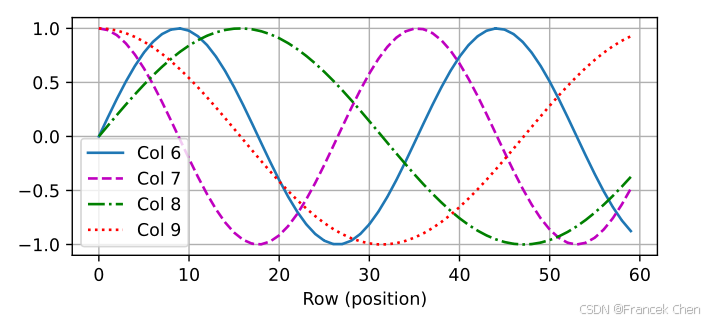
(一)绝对位置信息
为了明白沿着编码维度单调降低的频率与绝对位置信息的关系,让我们打印出 0 , 1 , … , 7 0, 1, \ldots, 7 0,1,…,7的二进制表示形式。正如所看到的,每个数字、每两个数字和每四个数字上的比特值在第一个最低位、第二个最低位和第三个最低位上分别交替。
for i in range(8):
print(f'{i}的二进制是:{i:>03b}')

在二进制表示中,较高比特位的交替频率低于较低比特位,与下面的热图所示相似,只是位置编码通过使用三角函数在编码维度上降低频率。由于输出是浮点数,因此此类连续表示比二进制表示法更节省空间。
P = P[0, :, :].unsqueeze(0).unsqueeze(0)
d2l.show_heatmaps(P, xlabel='Column (encoding dimension)', ylabel='Row (position)', figsize=(3.5, 4), cmap='Blues')
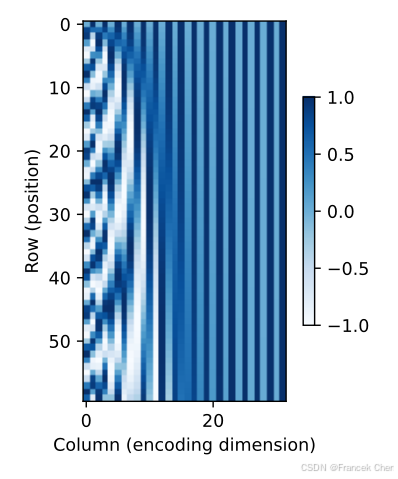
(二)相对位置信息
除了捕获绝对位置信息之外,上述的位置编码还允许模型学习得到输入序列中相对位置信息。这是因为对于任何确定的位置偏移 δ \delta δ,位置 i + δ i + \delta i+δ处的位置编码可以线性投影位置 i i i处的位置编码来表示。
这种投影的数学解释是,令
ω
j
=
1
/
1000
0
2
j
/
d
\omega_j = 1/10000^{2j/d}
ωj=1/100002j/d,对于任何确定的位置偏移
δ
\delta
δ,式(2)中的任何一对
(
p
i
,
2
j
,
p
i
,
2
j
+
1
)
(p_{i, 2j}, p_{i, 2j+1})
(pi,2j,pi,2j+1)都可以线性投影到
(
p
i
+
δ
,
2
j
,
p
i
+
δ
,
2
j
+
1
)
(p_{i+\delta, 2j}, p_{i+\delta, 2j+1})
(pi+δ,2j,pi+δ,2j+1):
[
cos
(
δ
ω
j
)
sin
(
δ
ω
j
)
−
sin
(
δ
ω
j
)
cos
(
δ
ω
j
)
]
[
p
i
,
2
j
p
i
,
2
j
+
1
]
=
[
cos
(
δ
ω
j
)
sin
(
i
ω
j
)
+
sin
(
δ
ω
j
)
cos
(
i
ω
j
)
−
sin
(
δ
ω
j
)
sin
(
i
ω
j
)
+
cos
(
δ
ω
j
)
cos
(
i
ω
j
)
]
=
[
sin
(
(
i
+
δ
)
ω
j
)
cos
(
(
i
+
δ
)
ω
j
)
]
=
[
p
i
+
δ
,
2
j
p
i
+
δ
,
2
j
+
1
]
(3)
\begin{aligned} &\begin{bmatrix} \cos(\delta \omega_j) & \sin(\delta \omega_j) \\ -\sin(\delta \omega_j) & \cos(\delta \omega_j) \\ \end{bmatrix} \begin{bmatrix} p_{i, 2j} \\ p_{i, 2j+1} \\ \end{bmatrix}\\ =&\begin{bmatrix} \cos(\delta \omega_j) \sin(i \omega_j) + \sin(\delta \omega_j) \cos(i \omega_j) \\ -\sin(\delta \omega_j) \sin(i \omega_j) + \cos(\delta \omega_j) \cos(i \omega_j) \\ \end{bmatrix}\\ =&\begin{bmatrix} \sin\left((i+\delta) \omega_j\right) \\ \cos\left((i+\delta) \omega_j\right) \\ \end{bmatrix}\\ =& \begin{bmatrix} p_{i+\delta, 2j} \\ p_{i+\delta, 2j+1} \\ \end{bmatrix} \end{aligned} \tag{3}
===[cos(δωj)−sin(δωj)sin(δωj)cos(δωj)][pi,2jpi,2j+1][cos(δωj)sin(iωj)+sin(δωj)cos(iωj)−sin(δωj)sin(iωj)+cos(δωj)cos(iωj)][sin((i+δ)ωj)cos((i+δ)ωj)][pi+δ,2jpi+δ,2j+1](3)
2 × 2 2\times 2 2×2投影矩阵不依赖于任何位置的索引 i i i。
小结
- 在自注意力中,查询、键和值都来自同一组输入。
- 卷积神经网络和自注意力都拥有并行计算的优势,而且自注意力的最大路径长度最短。但是因为其计算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。
- 为了使用序列的顺序信息,可以通过在输入表示中添加位置编码,来注入绝对的或相对的位置信息。


















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











