








no free lunch
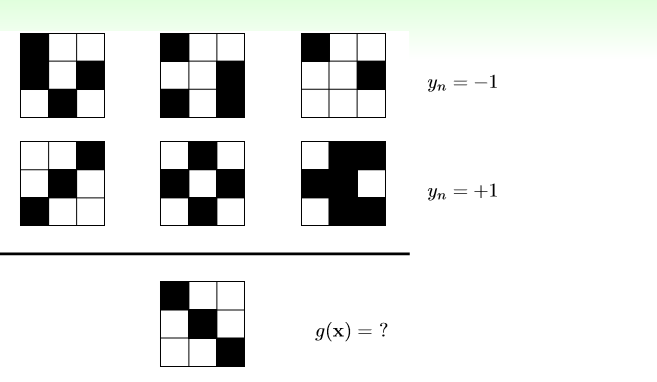
从以上6个图片里看看,第七个图片应该是什么类型??
如果我说规律是,左上角有黑块的标签为-1,否则为1,那么g(x)=-1,但是如果我说图形不对称的为-1,对称的为1 ,那么我说g(x)=1.
所以,不管我们的答案是什么 ,都有另一个解释说我的答案是错误的。
即在没有任意的前提(假设,也就是所谓的附加条件)的话,我们是不能找到一个模型正确的吧第七个图形分类的。

再一个例子,给你5个样本(如上图),请你预测出剩下的3个输入值对应的标签。
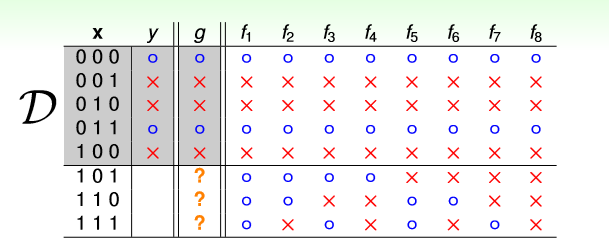
如上图,很显然,即使我们让模型完全记住5个样本,我们剩下8种情况要挑选。但是,如果什么都不告诉我们,仅仅就给5个样本去模拟的话,我们是无法从8个里面挑选最正确的g与正在的f 相近的。
所以,得出结论,当仅仅给我们数据D,而没有任何假设,任何前提的话(即我们不知道真正的f的任何信息的话),用D学习到的模型去预测数据D外的数据,得到结果一定是很差的。

很大的几率 U=V
用概率营救

假设我们有一个装满橘色和绿色弹珠的罐子,弹珠多的我们无法去数。我们想知道橘色弹珠占有的比例!
那我们该怎么做?我们会抓一把,看看这一把的弹珠里橘色的比例。但是这一定就是正确的吗?不一定。但是我们可以说有很大的概率二者是相似的。因为有可能抓到全是绿色的情况,但是全是绿色的概率很小。
Hoeffding (霍夫丁)不等式
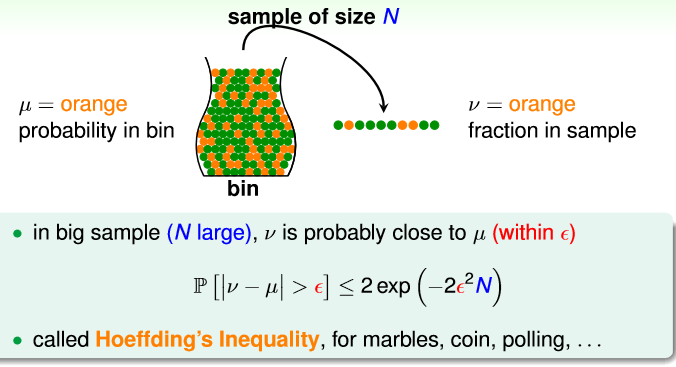
我们假设罐子里有u个橘色弹珠,抓出来的样本有v个橘色的弹珠。
那么在大样本(N large)的情况下,有
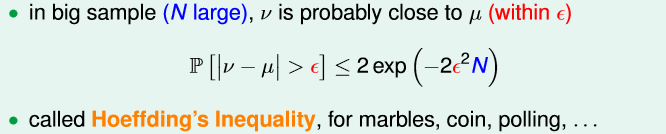
即在大样本的情况下,N就很大。那么|v-u|>
ϵ
的概率就很小,即u和v就很接近。
所以,在大样本的情况下,v=u 我们可以说 大概差不多是对的(PAC)
probably :大概,即取到极端的情况(全是绿色)的概率很小
approximately:差不多,即 v 几乎接近u,比如u=100,那么v为99,98
所以在大样本(N large)的情况下,我们有很大的概率去用v表示u.
与机器学习的联系(h能否接近f)
h(xn)
为我们估计的模型,f是最正确的模型。
(xn,yn)
是样本N。
在大样本N,且
xn
是独立同分布的抽取时,我们大概可以用样本的[
h(xn)≠yn
] 的多少来推断出[
h(xn)≠f(x)
]。即用
h(xn)
与
yn
的正确率,推断出
h
与f的相似度。(这里,我们就认为上面的v就表示 【

Ein(h)
表示样本的错误率
Eout(h)
表示样本外的错误率
依据上图式子,在大样本的情况下:

所以如果
Ein(h)
小,那么很大概率
Eout(h)
也小。那么在数据都服从同一分布的情况下,h
≈
f
说了这么多,以上只是验证函数h能否接近f。
但是当H有很多的h时该怎么办呢??
我们以上说的都在一个h的情况,那如果有很多的h呢??
我们知道,根据hoeffding 不等式
以投硬币为例。当只有一个人投时,投5次全是正面的概率为
132
。但是当有150个人投硬币,每人投5次,有一次全是正面的概率为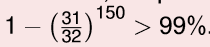
我们类比一下,每一个人相当于每一个h,5次全是正面的情况相当于我用样本得到的
Ein
与真实的
Eout
不符合,那么我们就说这些样本是BAD sample。
# 我们现在证明的是机器学习的可行性,即我用机器学习算法拟合样本数据,得到的模型是不是和f差不多,差不多其实就是$E_{in}\approx E_{out}$。我们希望的是对于任意的模型,任意的h,都有$E_{in}\approx E_{out}$。所以 $E_{in}$与真实的$E_{out}$不符合 表示出问题的是样本数据,而不是模型h可是,在真实的机器学习实践中,h不是都很多嘛??那不是意味着BAD sample 出现的概率会很大很大,即 Ein 与真实的 Eout 不符合 的概率不是会很大很大,那机器学习 不是不可行的吗???
现在我们来证明在有限的H(假设H内h的个数为M个),机器学习算法依然是可行的!(无限的H下节在说)
hoeffding 不等式
当有M个h时,总体的BAD sample 为 all
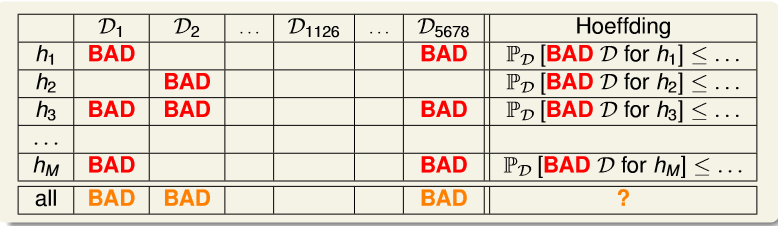
证明:
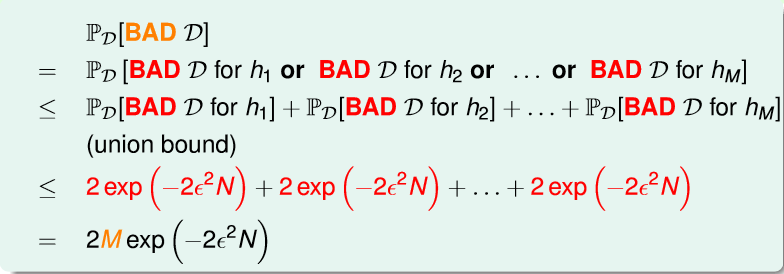
根据以上证明,在有限的H,M是一定的。只要N足够大,那么
PD[BADsample]
也会很小。即

那么我们就可以找到最好的g,使得g的 Ein 最小。又 Ein≈Eout 是PAC的。那么g就是最好的模型。
但问题是,H一般是无限的。该怎么办???见下一讲!!!















 1207
1207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









