






 本文介绍了正则表达式的基础和扩展,包括常见的元字符如"^"、"$"、"*"等,以及扩展元字符如"+"、"?"、"()"和"|". 通过示例解释了它们在匹配字符串中的作用,适用于grep、egrep、sed和awk等工具。
本文介绍了正则表达式的基础和扩展,包括常见的元字符如"^"、"$"、"*"等,以及扩展元字符如"+"、"?"、"()"和"|". 通过示例解释了它们在匹配字符串中的作用,适用于grep、egrep、sed和awk等工具。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
`
一、通配符
在Linux中可以使用通配符替代或者识别某一些文件
| 符号 | 效果 |
|---|---|
| ? | 匹配一个字符 f?.txt(代表有且只有一个任意字符) |
| * | 匹配所有非隐藏的字符无论多长多短(代表0个或者多个任意字符) |
| {1…10} | 1到10 |
| {a…z} | a b c …z |
| {A…Z} | A B C …Z |
| [123] | 取其中之一有就显示没有也无所谓 |
| [a-z] | 范围需要注意 |
| [0-9] | 匹配数字范围(0123456789)([ ]代表的是任意一个括号内的列表中的字符) |
| \ | 转义符,表示原来的意思 |
| [[:lower:]] | 小写字母表示 a-z |
| [[:upper:]] | 大写字母表示 A-Z |
| [^zhou] | 匹配列表中的所有字符以外的字符 |
| [[:digit:]] | 任意数字,相当于0-9 |
通配符只能模糊的(有一定范围的)查询我们所需要的内容,
正则表达式,有点类似通配符,但匹配的精确度会比通配符更高,
通配符通常被用在模糊查询的场景中,正则表达式的匹配精确度比通配符更高
二、正则表达式
正则表达式 - - 通常用于判断语句中,用来检查某一字符串是否满足某一格式
正则表达式是由普通字符和元字符组成
● 普通字符包括大小写字母,数字,标点符号及一些其他符号
● 元字符是指在正则表达式中有特殊意义的专用字符,可以用来规定其前导转字符,(所谓前导字符 就是位于元字符前面的字符或表达式)在目标对象中的出现模式
■ 元字符通常意义上分为两大类
♦ 一类是基础正则表达式常见元字符
♦ 另一类是扩展正则表达式元字符
这两种元字符都叫元字符,但是他们所能只吃的工具不太相同,比如说扩展元字符有些工具不能使用,需要添加特殊的功能,有的元字符是所有工具都能使用的,但,使用方法又会有些小的区别
1. 基础正则表达式常见元字符
正则表达式常见元字符(支持的工具:grep,egrep(grep的增项版),sed,awk)
| 符号 | 效果 |
|---|---|
| \ | 用于取消特殊符号的含义 |
| ^ | 匹配字符串开始的位置 |
| $ | 匹配字符串结束的位置(例;word$,^$匹配空行) |
| . | 匹配除\n之外的任意的一个字符(例go.d,g…g) |
| * | 匹配前面子表达式0次或者多次(例:goo*d,go.*d) |
| [list] | 匹配list列表中的一个字符,(例:go[ola]d,[abc]、[a-z]、[a-z0-9]、[0-9]匹配任意一位数字) |
| [^list] | 匹配任意非list列表中的一个字符,(例:[^0-9]、[^A-Z0-9]、[^a-z]匹配任意一位非小写字母) |
| \{n\} | 匹配前面的子表达式n次,(例:go\{2\}d、'[0-9]\{2\}'匹配两位数字) |
| \{n,\} | 匹配前面的子表达式不少于n次,(例:go{2,}d、'[0-9]\(2,}'匹配两位及两位以上数字) |
| \{n,m\} | 匹配前面的子表达式n到m次,例如:go\{2,3\}d,'[0-9]\{2,3\}'匹配两位到三位数字 |
| \w | 匹配包括下划线的任何单词字符。\w:匹配任何非单词字符。等价于"[A-Za-20-9_]"。 |
| \d | 匹配一个数字字符。\D:匹配一个非数字字符。等价于[0-9]。 |
| \s | 空白符。\s:非空白符 |
| 注: | egrep、awk使用(n}、{n,}、(n,m}匹配时“{}"前不用加“\“ |
1.“\ ” :“&”, “|”,“!”,“=”, “$”, “.”, “*”, ";"这些符号在linux系统中都是特殊符号,如果想让这些符号作为一个普通的符号字符存在的话,需要在他们前面加上反斜杠
"\"还可以把一些普通字符转换成特殊功能,例如:\n(换行),\t(制表符),\r(回车符)等等
2.“^” : 以什么字符或字符串开头,例如:^a代表这行内容以a开头的,^the代表这行内容以the开头^#代表这行内容以#号开头,^[a-z]中括号代表一个列表的值,^[a-z]代表任何以小写字母开头的行内容
3.“$” : 匹配字符串结束的位置,例如:word$代表以word结尾的内容,^$代表的是空行
4. “.” : 匹配除了\n意外的任意字符,例如:go.d(可以匹配good,gold,goad,go8d,只要不是换行符的任意都可以匹配到),g…d(可以匹配good,gold,goad,g08d,g45d,两个点点代表除了换行符以外的是两个任意字符)
5. “*” :匹配前面子表达式0次或者多次(*代表任意长度)
例如:(good,gold,goad,go8d,g45d,gald,god)
如果使用“*”可以匹配到(good,gold,goad,go8d,god)
首先good-点代表任意字符,星代表任意长度
其次gold-同样也能匹配到
再来goad-也同样能匹配到
之后go8d-也是能匹配到
下面的g45d-这个是匹配不到的,因为最少要有个o存在,g45d不符合匹配的要求
下面的gald-和上面的同理
最后两个god-可以匹配到,因为星代表的长度也可能为0,也就是可以没有的,所以god是可以匹配的
示例1:“^” “$” “*”
(1) 首先先建立一个里面输入无序字符的文档go.txt
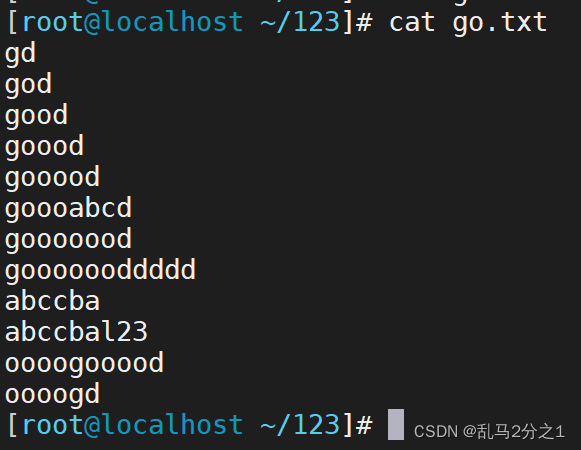
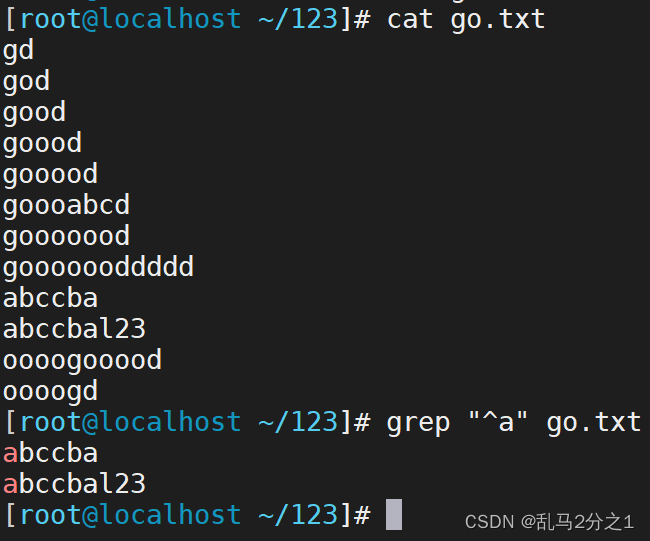
(2) 然后我们匹配所有以a开头的字符
grep "^a" go.txt
此时以a为开头的文件都被匹配到(如下图)
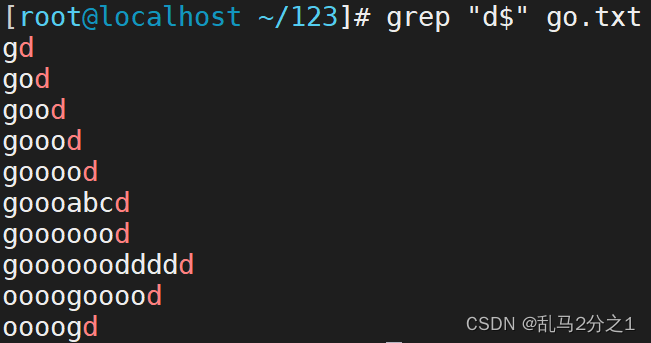
(3)接下来我们匹配所有以d为结尾的字符
grep "d$" go.txt
此时所有以d结尾的字符都被匹配到(如下图)
注意:这里“$”在d的右侧
(4)之后我们匹配goo\*d
grep "goo*d" go.txt
此时所有包含god的字符都会被匹配到(如下图)
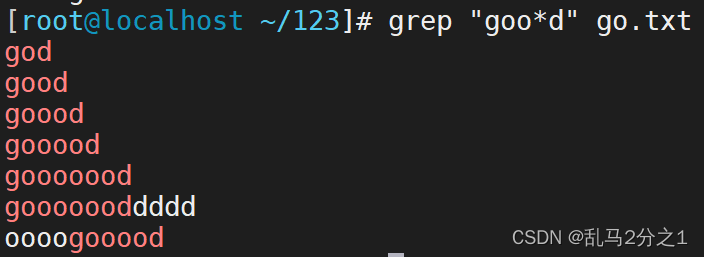
上面图片可以看到,无论g是否在第一个,或者末尾有多少个d也都会被匹配,
(5)如果想精确的匹配g开头或者d结尾的话
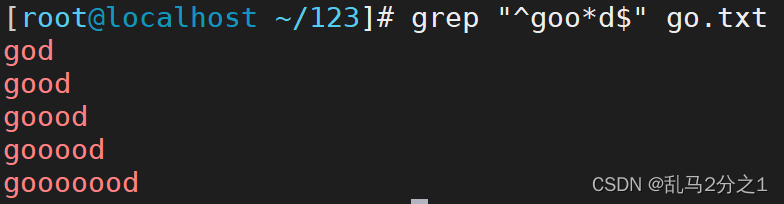
grep "^goo*d\$" go.txt
在g前面加上^,在d后面加上$就可以精确匹配出来(如下图)
6. “[list]” : 中括号里面是个列表,是一串字符列表,可能是字母也可能是数字也可能是大小写字母加数字或其他什么符号,中括号的作用就是无论括号里面是什么样的字符列表,都可以匹配任意的一个字符,但是默认情况下只能匹配其中一个字符。例如:go[ola]d(他可以匹配good,gold,goad),
7. “[^list]” : 上尖角这里代表的是取反的效果,匹配非中括号内字符列表内的字符、例如:[^0-9]就代表不能是0-9,可以是字母,可以是大小写字母,就是不能是数字0-9,[^A-Z0-9]代表他只能去匹配小写的字母和一些符号字符大写的字母和数字就不能去匹配了,[^a-z]代表能匹配非小写字母以外的任意
8.\{n\} : 匹配前面的字符n次。例如:go\{2\}d代表匹配前面的o两次,也就是两个o,
[0-9]\{2\}代表,匹配前面中括号里面列表字符里面中任意字符两次
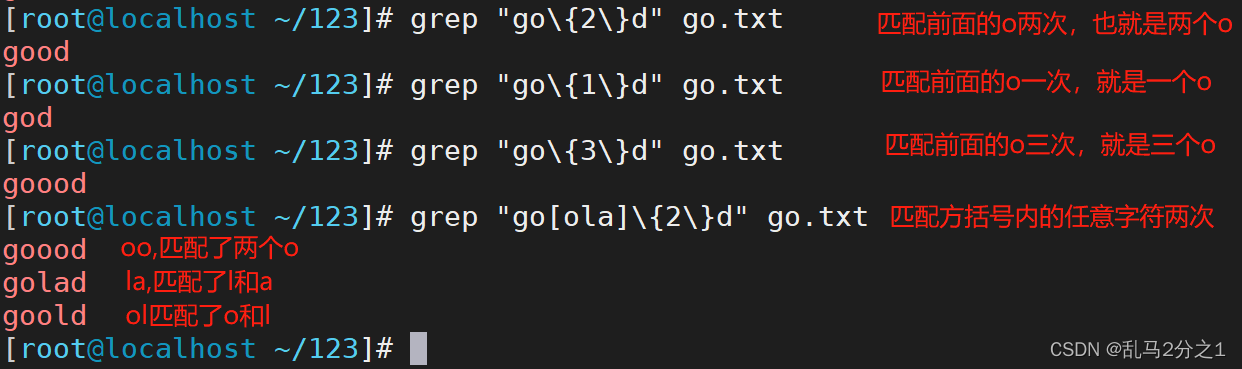
示例2:“ \ {n\ }”
grep "go\{2\}d" go.txt 匹配前面的o两次
grep "go\{1\}d" go.txt 匹配前面的o一次
grep "go\{3\}d" go.txt 匹配前面的o3次
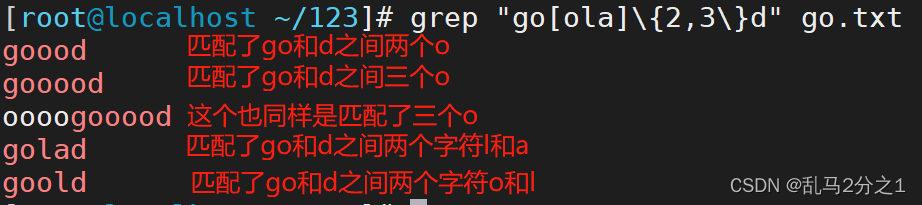
grep "go[ola]\{2\}d" go.txt 匹配中括号内的任意字符(o,l,a)两次
9. \{n,\}|匹配前面的子表达式不少于n次,例如:go\{2,\}d、'[0-9]\{2;\}'匹配两位及两位以上数字)
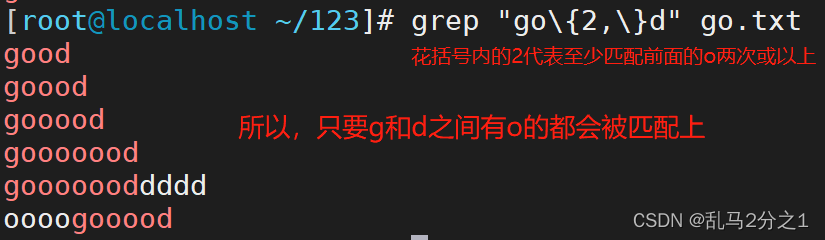
示例3:“ \ {n,\ }”
grep "go[ola]\{2,\}d" go.txt 匹配前一个字符最少两次,就是大于等于2
10. \{n,m\} :匹配前面的子表达式n到m次,此处m必须大于n。例如:go\{2,3\}d,'[0-9]\{2,3\}'匹配两位到三位数字
示例4:“\ {n,m\ }”
grep "go\{2,3\}" go.txt 匹配前面的字符n到m次,此处m必须大于n
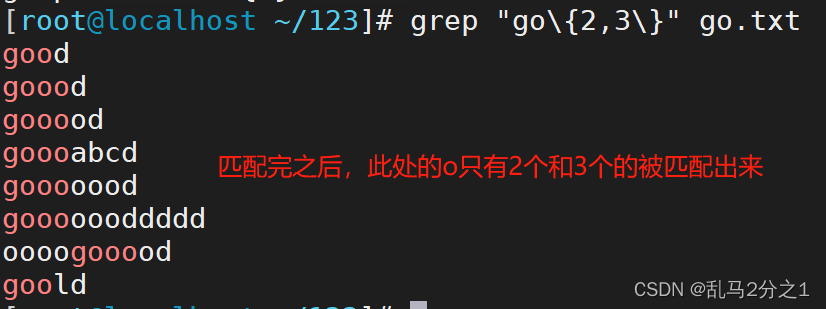
grep "go\{2,3\}d" go.txt 匹配g和d之间的o,两次到三次,所以两个o和3个o的字符都被匹配出来

grep "go[ola]\{2,3\}d" go.txt 匹配go和d之间中括号内的任意字符的两个到三个之间的字符
示例5:“egrep”
egrep "go\{2,3\}d" go.txt egrep的命令加上反斜杠反而会无法执行
egrep "go{2,3}d" go.txt egrep的命令执行grep的命令时不需要反斜杠
grep -E "go{2,3}d" go.txt 如果一定要用grep命令执行且不想加反斜杠的话在grep后加-E

2. 扩展正则表达式元字符
扩展正则表达式元字符:(支持的工具:egrep、awk)grep -E sed -r
| 符号 | 效果 |
|---|---|
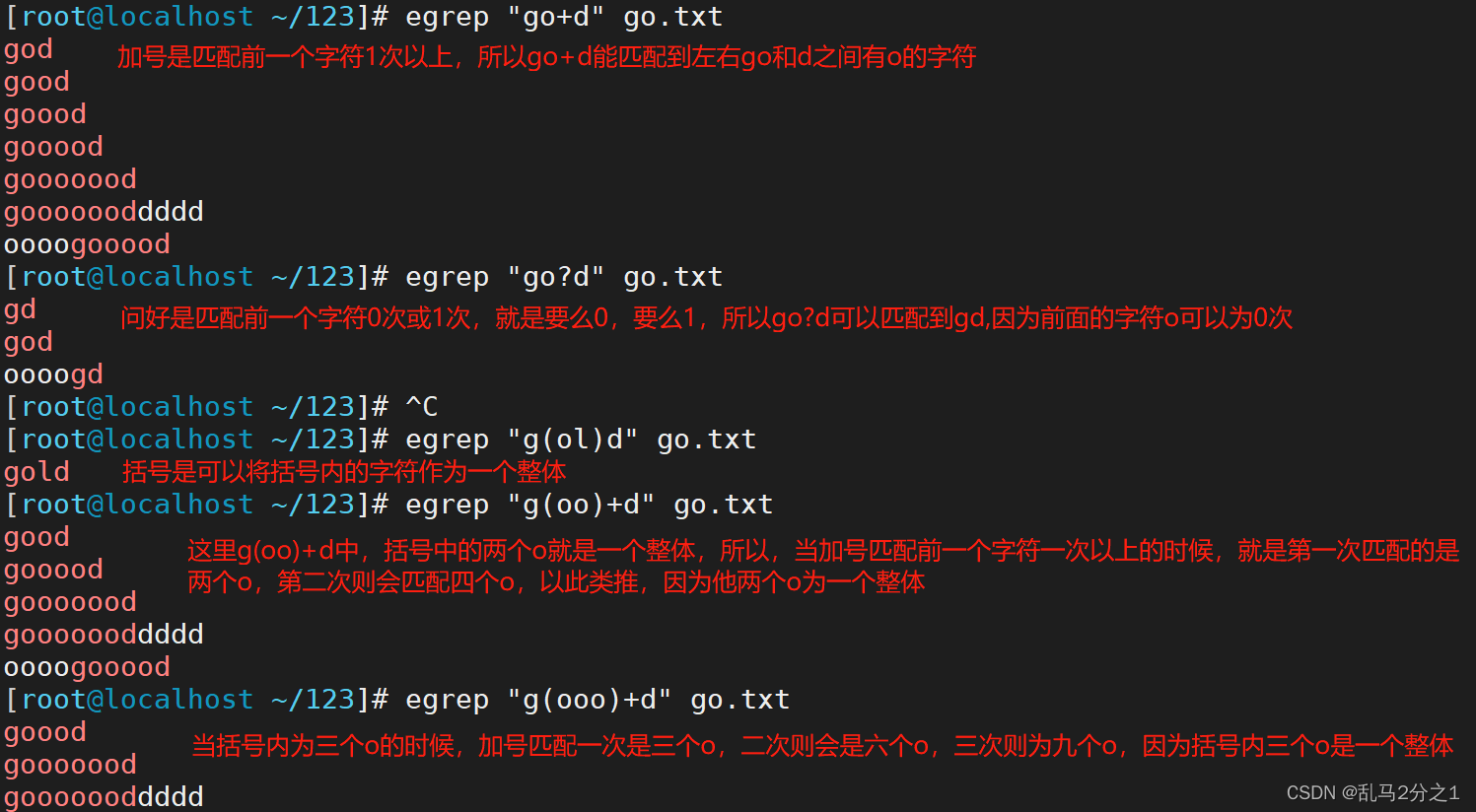
| + | 匹配前面子表达式1次以上,例:go+d,将匹配至少一个o,如god、good、goood等 |
| ? | 匹配前面子表达式o次或者1次,例:go?d,将匹配gd或god |
| () | 将括号中的字符串作为一个整体,例1:g(oo)+d,将匹配oo整体1次以上,如good、gooood等 |
| | | 以或的方式匹配字条串,例:g(oolla)d,将匹配good或者glad |
示例6:“+” “?” “()” “|”
egrep "go+d" go.txt 加号匹配前面字符必须是一次以上,也就是大于1,可以是1次,可以是2次,三次,就是没有0次
egrep "go?d" go.txt 匹配前面字符0次或者一次
egrep "g(oo)+d" go.txt 括号内的字符为一个整体,当加号匹配前一个字符时候所匹配的就是括号内所有的字符,并且二次匹配时候同样是括号内的字符的倍数
egrep "go(oo|la)d" go.txt 匹配括号内oo或者la


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









