







集合(Set)是Python中的一种无序、不重复的数据结构。集合是由一组元素组成的,这些元素必须是不可变数据类型,但在集合中每个元素都是唯一的,即集合中不存在重复的元素。
集合的基本语法:
1、元素值必须是不可变数据类型
集合的元素值不能嵌套列表等。
s1 = {1, 2, 3}
print(s1)
s2 = {1, 2, 3, [4, 5]}
print(s2)

集合的数据类型具有长度。
s1 = {1,2,3}
print(len(s1))
print(type(s1))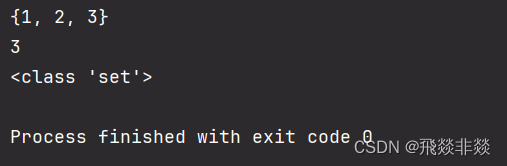
2、无序:没有索引
因集合里的元素值是无序的,即使显示是按照顺序打印的。所以集合没有索引的使用方法。
s1 = {1, 2, 3}
print(s1[0])
3、唯一: 集合可以去重
集合里定义的元素值,即使有多个重复的值,会进行去重处理,保证值的唯一。
s2 = {1, 2, 3, 3, 2, 2}
print(s2)
4、列表与集合的组合使用
列表与集合是可以在符合条件下的情况相互做类型转换的。
例如,可以使用集合将列表里的元素值做去重处理,去重处理后得到的集合,同样可转为列表。
list01 = [1, 2, 3, 3, 2, 2]
# 类型转换:将列表转为集合
list01 = set(list01)
print(list01)
print(type(list01))
# 类型转换:将集合转为列表
list01 = list(list01)
print(list01)
print(type(list01))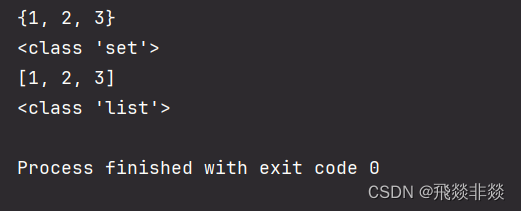
集合的特性:
- 无序性:集合中的元素是无序的,即元素没有固定的顺序。因此,不能使用索引来访问集合中的元素。
- 唯一性:集合中的元素是唯一的,不允许存在重复的元素。如果尝试向集合中添加已经存在的元素,集合不会发生变化。
- 可变性:集合是可变的,可以通过添加或删除元素来改变集合的内容
以上为Python的集合的基本语法和特性。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











