







效果图
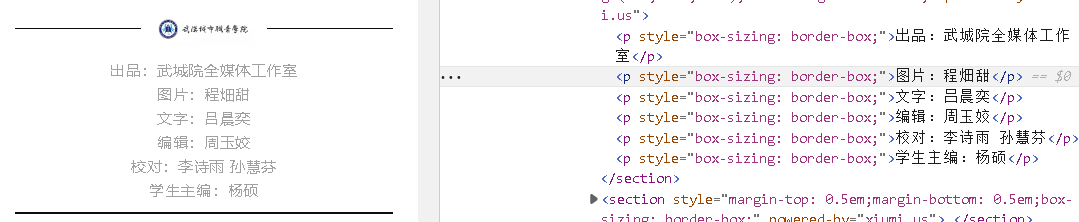
需要爬取的网页和内容
程序目的:根据公众号文章中的内容,爬取文章的标题、发布时间、责任人署名、文章链接,将这个python程序打包成为exe文件,在运行exe文件时可以爬取html的内容并保存为本地的Excel表格。
所含有的知识点
- requests爬虫请求
- 时间戳
- 表格操作,合并单元格、表格文字加粗、文字居中
- python保存为exe
- exe获取当前运行程序的路径
python脚本打包成exe文件获取当前路径的问题
【文章推荐】python获取程序执行文件路径方法
import os
import sys
# 确定应用程序是脚本文件还是被冻结的exe
if getattr(sys, 'frozen', False):
# 获取应用程序exe的路径
path = os.path.dirname(sys.executable)
elif __file__:
# 获取脚本程序的路径
path = os.path.dirname(__file__)
print(path)完整代码
from asyncio.windows_events import NULL
from doctest import Example
import importlib
from pathlib import Path
from lxml import etree
import re
from urllib import request, response
import requests
from urllib import request
import re #进行数据清洗要导入此模块
from lxml import etree
import xlsxwriter
from asyncio import sleep
import xlwt
import xlsxwriter
from datetime import date,datetime
from openpyxl import load_workbook
import time
import os
import sys
# 获取所有的推文链接
def GetSiteList(start, end,path):
siteLists = []
print("\n程序正在运行...")
for i in range(start, end):
parser = etree.HTMLParser(encoding='utf-8')
try:
tree = etree.parse(path+str(i)+".html", parser=parser)
except Exception as result:
print("错误:你保存的html文件名称错误,正确文件名称为:1.html、2.html、3.html,请重新运行程序。")
pass
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//*[@class='weui-desktop-mass-appmsg__title']/@href")
siteLists.extend(result)
return siteLists
# 获取所有推文中的责任姓名
def GetName(siteList,path):
headers = {"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Mobile Safari/537.36 Edg/105.0.1343.33"}
# 创建表格
workbook = xlsxwriter.Workbook(path+'官微每月作品表.xlsx')
worksheet = workbook.add_worksheet()
worksheet.merge_range('A1:I1',"记者团官方微信公众号 每月作品表汇总")
bold = workbook.add_format({'bold': True,"align":"center"})
worksheet.write('A1', '记者团官方微信公众号 每月作品表汇总', workbook.add_format({'bold': True,"size":15,"align":"center"}))
worksheet.write('A2', '日期', bold)
worksheet.write('A2', '日期', bold)
worksheet.write('B2', '选题名称', bold)
worksheet.write('C2', '编辑', bold)
worksheet.write('D2', '校对', bold)
worksheet.write('E2', '文字', bold)
worksheet.write('F2', '图片', bold)
worksheet.write('G2', '视频', bold)
worksheet.write('H2', '音频', bold)
worksheet.write('I2', '学生主编', bold)
worksheet.write('J2', '推文链接', bold)
time.sleep(0.5)
parser = etree.HTMLParser(encoding='utf-8')
line = 2
alignCenter = workbook.add_format({"align":"center"})
for i in range(len(siteList)-1,0,-1):
line = line + 1
# dict = {"time":NULL, "activity":NULL, "edit":NULL, "text":NULL, "proofreading":NULL, "picture":0, "video":NULL}
reponse = request.urlopen(siteList[i]).read().decode()
try:
pat1 = r"var ct = \"(\d+)\""
date1 = re.search(pat1, reponse).group(1)
date1 = int(date1)
#转换为其他日期格式,如:"%Y-%m-%d %H:%M:%S"
timeArray = time.localtime(date1)
otherStyleTime = time.strftime("%m月%d日", timeArray)
worksheet.write('A'+str(line), otherStyleTime,alignCenter)
print(otherStyleTime,end=" ")
except Exception as result:
try:
pat2 = r"window.ct = \'(\d+)\'"
date2 = re.search(pat2, reponse).group(1)
date2 = int(date2)
timeArray2 = time.localtime(date2)
otherStyleTime2 = time.strftime("%m月%d日", timeArray2)
worksheet.write('A'+str(line), otherStyleTime2,alignCenter)
print(otherStyleTime2,end=" ")
except Exception as result:
pass
html = etree.HTML(reponse)
activity_name = html.xpath("//h1")[0].text.strip() #标题
worksheet.write('B'+str(line), activity_name,alignCenter)
print(activity_name)
try:
bianJi = r"编辑:([\u4e00-\u9fa5].*?)<"
bianJi = re.search(bianJi, reponse).group(1).replace(" "," ")
worksheet.write('C'+str(line),bianJi,alignCenter)
#print(bianJi)
except Exception as result:
pass
try:
jiaoDui = r"校对:([\u4e00-\u9fa5].*?)<"
jiaoDui = re.search(jiaoDui, reponse).group(1).replace(" "," ")
worksheet.write('D'+str(line),jiaoDui,alignCenter)
#print(jiaoDui)
except Exception as result:
pass
try:
text = r"文字:([\u4e00-\u9fa5].*?)<"
text = re.search(text, reponse).group(1).replace(" "," ")
worksheet.write('E'+str(line),text,alignCenter)
#print(text)
except Exception as result:
pass
try:
picture = r"图片:([\u4e00-\u9fa5].*?)<"
picture = re.search(picture, reponse).group(1).replace(" "," ")
worksheet.write('F'+str(line),picture,alignCenter)
#print(picture)
except Exception as result:
pass
try:
video = r"视频:([\u4e00-\u9fa5].*?)<"
video = re.search(video, reponse).group(1).replace(" "," ")
worksheet.write('G'+str(line),video,alignCenter)
#print(video)
except Exception as result:
pass
try:
audio = r"音频:([\u4e00-\u9fa5].*?)<"
audio = re.search(audio, reponse).group(1).replace(" "," ")
worksheet.write('H'+str(line),audio,alignCenter)
#print(audio)
except Exception as result:
pass
try:
zhuBian = r"学生主编:([\u4e00-\u9fa5].*?)<"
zhuBian = re.search(zhuBian, reponse).group(1).replace(" "," ")
worksheet.write('I'+str(line),zhuBian,alignCenter)
#print(zhuBian)
except Exception as result:
pass
try:
worksheet.write('J'+str(line), siteList[i])
except Exception as result:
#print("pass")
pass
# 关闭工作薄
workbook.close()
if __name__ == '__main__':
# 获取文件的路径
if getattr(sys, 'frozen', False):
application_path = os.path.dirname(sys.executable)
elif __file__:
application_path = os.path.dirname(__file__)
path = application_path.replace("\\","/")+"/"
print(path)
maxNum = input("请输入最大的html文件个数:")
getSiteList = GetSiteList(1,int(maxNum)+1, path)
GetName(getSiteList,path)
print("\nExcel文件位置:"+path+"官微每月作品表.xlsx")
input("\n程序运行完毕")















 2346
2346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











