







https://blog.csdn.net/hellozhxy/article/details/79911867
并查集
一种树形的 数据结构, 用来处理 一些不相交集合的 合并和查询问题。 通常以森林来表示。
两个操作步骤: 满足两个操作的一种数据结构。
1)查找两个元素,是否属于同一个集合,isSameSet
2)把两个集合合并成一个大集合。union
用 set 和 list实现,遍历代价较高。
逻辑实现:对于每一个集合, 里面的每一个元素都有一个node, node含有自己的value和指向上级的指针,
合并操作:刚开始,认为每一个单一数据都是一个集合,这些集合的上级指针指向本身; 合并操作之后,每个数据较少的集合加到这个链表后面。
单次查询 或者 单次合并的时间复杂度 O(1)
排序
排序定义:对一个序列对象,根据某个关键字进行排序。
排序中的属性:
稳定:a原本在b前面,a=b,排序之后,a仍然在b前面。
排序算法两大类: 基于比较的, 和基于非比较的。
十大排序算法。

比较排序:
比较排序:元素之间的次序依赖于它们之间的比较,必须与其它数进行比较,才能确定自己的位置。
适用于各种规模的数据,不在乎数据分布,都能进行排序,适用于一切需要排序的情况。
插入排序(直接插入排序、希尔排序),选择排序(简单选择排序、堆排序),交换排序(冒泡排序、快速排序),归并排序。
#####################################
选择排序: 分已排好序,未排序两部分。从未排序中(从前往后)找到最小的,放到已排序的末尾。无论如何,都是N2 (固定位置,找元素)
堆
堆的定义:
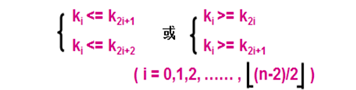
分别称为 最小化堆(小的在树顶), 最大化堆(大的在树顶)
若将和此序列对应的一维数组(即以一维数组做此序列的存储结构)看成是一个完全二叉树,堆的含义表明,完全二叉树中所有非终端节点的值,均不大于(或不小于)其左右孩子节点的值。
排序时,通常用大顶堆(大的值在上面)
小顶堆,主要用于优先队列。
堆排序:利用堆数据结构,完全二叉树,有序区元素为n-1,排序完成。堆顶为最小值。整体有序。
算法优势:在效率相同的前提下,只需要O(1)的辅助空间,很稳定。
#######################################
插入排序: 已排序序列(在前面),从后往前扫描,把未排序数据插入合适的位置(比较,移动,插入)。(固定元素,找位置)
希尔排序:将整个待排序记录序列,分割成若干子序列(这些组之前是交叉的,步长就是组数),对每个组分别进行直接插入排序,增量gap=2/len, gap为每组包含的元素,gap一直减小,减到1时,排序结束, 平均:nlogn, 最佳:nLog2n, 空间:1, 不稳定。
###############################################
基于交换的排序
冒泡排序: 比较相邻两个,大的往后移,一轮之后,最后一个数是最大的。依次循环多轮。最好的O(n),稳定的。把<条件
快速排序:通过一趟排序,将待排记录分割成独立的两部分,其中一部分关键字均比另一部分关键字肖,然后分别对这两部分继续进行排序,整个序列就有序了,
从数列中挑出一个元素,称为基准(pivot), 将串分为2个子串。 比pivot小的放在前面,比pivot大的放在后面。这个称为分区(partition)操作。 **递归(recursive)**把小于pivot的子数列和大于pivot的子数列排序。占用常数内存。 不稳定,最好的nlogn, 最差的n2.
快排的优势在于: 对于基本无序的序列, 效率最高,优势最明显。 核心在于划分, + 递归。
归并排序:
建立在归并操作上的有效的排序算法,采用分治法,时间上最差nlogn. 好的话n, 空间:n, 占用额外内存,稳定的。
分而治之,先使子序列有序,再使子序列间有序,将有序的子序列合并。可以采用递归。
核心: 先归, 再并/
1 void merge_sort(int arr[],int l,int r)
2 {
3 if(l >=r)
4 return ;
// 递归的操作
5 int mid=(l+r)/2;
6 merge_sort(arr,l,mid);
7 merge_sort(arr,mid+1,r);
//合并的操作
8 merge(arr,l,mid,r);
9 }
合并时, 两半的值临时存储, 双指针方式比较值的大小,重新在原数组赋值。
非比较排序:
桶排序:Bucket sort, 计数排序的升级版。人为设置一个bucket-size, 每个桶的容量。
- 计数排序 (时间复杂度:O(n) )
比较浪费空间,不能排序负数,如果数组长度小,但是最大值很大的话。
计数排序:线性时间复杂度,输入的数据必须是有确定范围的整数,稳定的排序算法。额外的数组空间,统计下标对应的值的个数。对于数组值范围很大的,需要大量时间和内存,
//计数排序,
void CountSort(vector<int>& arr, int maxVal){
int len = arr.size();
if(len < 1) return;
vector<int> count(maxVal+1, 0);
vector<int> tmp(arr);
for(auto x: arr)
count[x]++;
for(int i = 1; i <= maxVal; i++)
count[i] += count[i-1];
for(int i=len-1; i>=0; i--){
arr[count[tmp[i]] - 1] = tmp[i];
count[tmp[i]]--;
}
}
2)基数排序、
包括最低位优先,最高位优先, 两种方式道理相通的。
基数:指的是数据的位数(个位、十位、百位),每次从低到高进行排序。排完最高位之后,整个序列就变得有序了。每个位置排序时,跟其他位置无关。
给定 n个 d位数,每一位数位都有k种可能的取值,它的时间复杂度为O(d(n+k))
对日期的排序,可以用基数排序, 每位上的排序,都要用稳定的排序算法。
???? 自己手写一遍。。
3)桶排序。
将一个数组分为若干个桶(保证每个桶内数量均匀), 分桶(采用类似哈希的方法,除法), 桶和桶之间是有序的了, 桶内排完整体就有序了。,
得到每个桶内数据,按照基本排序把桶内数据排序好。 桶排序的时间复杂度取决于 桶的数量 + 桶内的排序算法。
只要确定每个元素之前已有的元素个数即可,一次遍历即可解决。时间复杂度O(n). 但是需要占用空间来确定唯一位置,对数据规模和数据分布有一定要求。
查找
七大查找算法
https://www.cnblogs.com/lsqin/p/9342929.html
给定某个数值,在查找表中确定一个关键字等于给定值的数据元素。
查找表; 关键字;
静态查找表, 只做查找操作。
动态查找表, 查找的时候同时进行插入删除操作。
顺序查找
对于线性表, 数组或者链表。
链表只能按顺序查找。
n很大时,查找效率很低。
二分查找
在有序数组中,查找某一特定元素。
https://baijiahao.baidu.com/s?id=1609200503642486098&wfr=spider&for=pc
C++ STL 容器:
顺序容器: vector、 deque、 list
关联容器: set、 multiset、 map、 multimap
https://blog.csdn.net/csdn_chai/article/details/77601420
(关联容器与顺序容器的区别在于,关联容器存储时,以关键字key为下标进行存储,底层都是红黑树,)
容器适配器:
(适配器是容器的接口,保存元素的机制是调用另一种顺序容器去实现)
stack、 queue,基于deque实现。
priority_queue,基于vector实现。
数组
一维数组、 多维数组
常见问题:
寻找数组中第k小的元素
找到数组中,第一个不重复出现的整数
合并两个有序数组
重新排列数组中的正值和负值
https://blog.csdn.net/fx677588/article/details/52794015
(C++ 数组、链表、vector等容器之间的区别)
C++ STL模板库 ,封装了一些数据结构。 vector相当于动态数组(连续空间存储,比普通数组更灵活), list也有封装好的链表)
vector: 连续空间存储,可以直接通过下标快速访问随机元素,末尾插入很快, 中间插入和删除操作很慢。空间不够的话,要重新分配,拷贝。
链表
链表一般用于实现文件系统、 哈希表 和 邻接表
链表常用形式: 单链表、 双向链表
list: 空间离散,用指针相联。访问随机元素很慢,没有vector数组快。 插入删除(从任何地方)操作比较快, 对每个元素分配空间,空间不存在不够用的情况。
栈 和 队列
C++ deque, 从前面或后面, 快速插入与删除。。 内部有一个map指针,可以直接访问元素。
stack, queue 使用deque的接口,适配。
stack: 先进后出, 不允许遍历。
queue: 先进先出, 不允许遍历。
优先队列
优先队列是队列的一种, 普通队列:先进先出,后进后出。
优先队列:出队和入队和顺序无关,和优先级有关。 优先级高的在队首。
优先队列,对队列数据结构做一些限制,相当于抽象出一个概念, 可以使用不同的底层数据结构来实现。

树
一种层级的数据结构, 由顶点和连接他们的边组成,n(n>=0)个节点的有序合集
树类似图,
树和图的区别: 树中不存在环路。
主要用于存储, 查询。
树数据结构常用术语: 根节点、 父节点, 子节点,叶子节点, 兄弟节点
节点的度: 节点拥有的子树的个数, 二叉树的度不大于2。
树的度: 树中最大的节点度数。
叶子: 度为0 的节点,也叫做终端节点。
高度: 叶子节点的高度为1, 根节点高度最高(从下往上)(从该节点到叶子节点的最长简单路径边的条数)。
深度: 从上往下, 根节点开始。(某节点的深度是指:从根结点到该节点的最长简单路径边的条数)
对整棵树来说,深度和高度是相等的, 对树中的节点来说,不一定相等。
层: 根在第一层, 依次类推
二叉树
https://blog.csdn.net/misayaaaaa/article/details/68941912
二叉树定义: 由一个节点和两颗互不相交的,分别称为这个根的左子树和右子树的二叉树构成(递归定义)
二叉树性质:
二叉树的第i层上,至多有2^( i - 1 )个节点 (根节点是第一层)
深度为k的二叉树,至多有2^k -1 个节点。
满二叉树: 按顺序填充,叶子节点一定在最后一层,非叶子节点都有左右两个孩子。
完全二叉树:最特别的二叉树,全部填满。
节点为i的子节点为:2 * i 和 2 * i + 1
节点为i的父节点为 i/2.
二叉树的遍历: 根据访问根节点的时机来分, 先序、中序、后序。 时间复杂度和空间复杂度都是O(n).
二叉树的存储结构:
1)顺序存储, 只适用于完全二叉树。 (可以用于堆排序)
2)链式存储(最普遍的存储方式, 左指针和右指针) 节点可能为空,浪费空间。
n个节点,需要2n个左指针,2n个右指针,但是用到的只有n-1个指针。
3)线索存储
Huffman编码
Huffman是一种前缀编码,建立在Huffman树基础上,
树的路径长度是每个叶节点到根节点的路径之和。
带权路径长度是:每个叶节点的路径长度*wi 之和。
Huffman树是: 最小带权路径长度的二叉树。

左节点小于右节点, 父节点是两个子节点的和。 权重大的节点在上面, 编码长度会比较小。
树结构的主要类型:
N元树、
平衡二叉树(又称AVL树, 平衡二叉查找树)、
普通的树结构或者二叉树结构,性能没有任何帮助,并且还增加了维护成本。
为了提升树的查找性能,基于二分法的思想, 提出了二叉平衡树。
任何一个节点的左子树和右子树都是平衡二叉树。 高度之差的绝对值不超过1。
构建过程:(中序有序的二叉树)
每一个非叶子节点的左子节点小于当前节点的值, 右子节点大于当前节点的值。
没有值相等,重复的点。
平衡二叉树的查询性能和树的层级( 高度h )成正比,
保证树的结构 左右两端大致平衡,降低二叉树的查询难度。
二叉搜索树(BST)
BST是一颗二叉树,使用链表结构表示,
用来做查找的, 中根序遍历, 左中右的顺序排列。
对于有n个节点的二叉树来说,search(查找), minimum(最小关键字节点), maxmun(最大关键字节点), predecessor(节点的先驱),successor(节点的后继),insert(插入), delete(删除), 等基本操作的时间复杂度,都是O(lg n)
堆树, 用来排序的,
大顶堆的话,根节点大于两个子节点,但两个子节点之间没有关系。
小顶堆同样道理。
构建堆的时间复杂度:
自顶向下: O(n * log n), 从根节点开始,一个个插入的方式构建。
自下向上: O(n), 从最后一个节点开始,逐个调整。
找出第k大数, 或者前k大数的多种解法。
https://blog.csdn.net/moli152_/article/details/44181297
利用堆: O(n + k * logn), n是构建堆的时间,后面是找出前k个的时间
利用快速排序的思想: 近乎是O(n)
利用计数排序的思想: O(n)
二叉树、
二叉搜索树、
平衡二叉树的两个版本:
红黑树、
2-3树
树常见的问题:
二叉树的高度
二叉搜索树中,查找第k个最大值。
查找与根节点距离k的节点。
二叉树中,查找给定节点的祖先节点。
字典树
Trie, 也称前缀树, 一种特殊的树状数据结构,常用于解决字符串相关的问题。
哈希表(Hashing)
唯一标识对象,并将每个对象存储在一些预先计算的唯一索引(键,key)的过程。
对象以键值对的形式存储,这些键值对的集合,被称为 字典。
可以使用键 搜索每个对象。
哈希表,通常使用数组 实现。
图
网络形式相互连接起来的节点, 节点又叫顶点, 一对节点(x, y)称为边(edge), 表示顶点x连接到顶点y。 边可以包含权重/成本,
模拟一些常见的网络。
网(network): 有些图的边或弧,带有与它相关的数字,这种与图的边或弧相关的数叫做权(weight),带权的图通常叫做网。
**无向完全图:任意两个顶点之间都存在边,含有n个顶点的无向完全图有 n(n-1)/2条边。
有向完全图:任意两个顶点之间都存在方向互为相反的两条弧,含有n个顶点的有向完全图有n(n-1)条边。
子图:假设有 两个图G1=(V1,E1)和G2=(V2,E2),如果V2含于V1,E2含于E1,则称G2为G1的子图(Subgraph)
环: 第一个顶点和最后一个顶点相同的路径,叫做环(cycle)
路径上的顶点,不重复出现,叫做简单路径。
连通: 顶点V1、V2之间有路径,则称V1和V2之间是连通的; 如果对于图中任意两个顶点之间都是连通的,则称这个图为连通图。
有向图中,的连通图 称为 强连通图。
连通图的生成树
一个连通图的生成树:一个极小的连通子图,含有图中全部的n个顶点,但只有足以构成一棵树的n-1条边。
如果一个有向图恰有一个顶点入度为0,其余顶点的入度为1,则是一棵 有向树。
图的类型: 无向图、 有向图。
图的表示形式: 邻接矩阵(二维矩阵)、 邻接表(链表)。
图的遍历算法: 广度优先搜索、 深度优先搜索。
https://blog.csdn.net/weixin_42061048/article/details/81448088
构造最小生成树:
(某一点 到其它所有点,的权值之和最小)
Prim算法,(贪心的策略,该点到其它每一个点的边的权值都是最小的,则总和就最小)
Kruskal算法。
最短路径:
Dijkstra算法
Floyd算法。
拓扑排序(判断图里有没有环, 检查图是否为树)
计算图的边数。
找到两点之间的最短路径。















 2251
2251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









