










优化MapReduce任务
使用Combiner
通过使用combiner可以使MapReduce整体性能得到提升。combiner等同于本地的Reduce操作,可以有效提升全局reduce操作效率。combiner可以从根本上优化和最小化键值对的数量,而键值对是通过网络在mapper和reducer之间传输的。combiner使用map操作处理键值对输出的中间结果,并不影响map和reduce函数中编写的转换逻辑。
要实现combiner首先意味着实现一个combiner类。一旦这个用户定义的类得以实现并添加,map函数并非like生成键值对形式的中间结果并输出,而是把键值对收集到列表中,其中每一个键对一个一列值。combiner以键值对形式输出键以及对应的值的列表。当combiner缓冲区中的键值对达到一定数目时,缓冲区中的数据就会被清空并转移到reduce函数。
调用一项作业的combiner自定义类的方法与设置map和reduce类的方法类似:job.setCombinerClass(MyCombine.clcass);
下图给出使用combiner时应该关注的Hadoop计数器:
上图所示可以看到,Combine input records和Combine output records的记录数为0,这是因为该作业并未实现任何combiner类。因此map output records的数量和reduce input records 的数量相同。下图是combiner实现后的效果:

如上图,请注意一下combine input records 和 Combine output records的记录数,以及reduce input records 和map out records的数量。可以看到combiner的实现减少了传递给reduce函数的数据量。
从上面两张图的对比可以看出,由于使用了combiner函数,这项作业的combiner记录数增加了。reduce的输入数据量由起初的10485760降低为685760.在数据量非常大的环境下,使用combiner是改善MapReduce作业整体性能的有途径。
如下图所示的代码片断展示了从一项MapReduce作业抽取的自定义combiner类。

由图可知,combiner类实现了reducer接口,并且与reducer函数一样,调用combiner会使用map输出的多个值作为参数。该类用自由代码覆盖了reduce()方法。代码中13-23行迭代mapper函数传递的值的列表,如果当前键与前一个键不同,则调用write() 方法输出结果。
使用压缩技术
压缩技术能够有效减少从底层存储系统(HDFS)读写的字节数。压缩提高了网络带宽和磁盘空间的效率。在Hadoop下,尤其是数据规模很大和工作负载密集的情况下,使用数据压缩显得非常重要。在这种情况下,I/O操作和网络传输要花费大量的时间。还有,Shuffle和Merge过程同样也面临着巨大的I/O压力。
鉴于磁盘I/O和网络带宽是Hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘I/O和传输非常有帮助。不过,尽管压缩与解压操作的CPU开销不高,其性能的提升和资源的节省并非没有代价。如果磁盘IO和网络带宽影响了MapReduce作业性能,在任意MapReduce阶段启用压缩都可以改善端到端处理时间并减少IO和网络流量。
压缩map输出对于减少map和reduce任务间的网络流量始终有效。压缩可能在MapReduce作业的任意阶段启用,如下图所示:
输入压缩:在有大量数据并计划重复处理的情况下,应该考虑对输入进行压缩。然而,你无需显式指定使用的编码解码方式。Hadoop自动检查文件扩展名,如果扩展名能够匹配,就会用恰当的编解码方式对文件进行压缩和解压。否则,Hadoop就不会使用任何编解码器。
使用复制技术时,对输入文件进行压缩可以节省存储空间并加速数据传输。要压缩输入数据,你应该使用不可拆分算法,如bzip2或者zlib的SequenceFile格式。
压缩mapper输出:当map任务输出的中间数据量很大时,应考虑在此阶段采用压缩技术。这能显著改善内部数据Shuffle过程,而Shuffle过程在Hadoop处理过程中是资源消耗最多的环节。如果发现数据量大造成的网络传输缓慢,应该考虑使用压缩技术。可用于压缩mapper输出的快速编解码器LZO、LZ4或者Snappy。
Limpel-Zif-Oberhumer(LZO)是供Hadoop压缩数据用的通用压缩编解码器。其设计目标是达到与硬盘读取速度相当的压缩速度,因此速度是其优先考虑的因素,而不是压缩率。与gzip编码器相比,它的压缩速度是gzip的5倍,而解压速度是gzip的2倍。同一个文件用LZO压缩后比用gzip压缩后大50%,但比压缩前小25%-50%。这对改善性能非常有利,map阶段完成时间快4倍。
压缩reducer输出:在此阶段启用压缩技术能够减少要存储的数据量,因此降低所需的磁盘空间。当MapReduce作业形成作业链条时,因为第二个作业的输入也已压缩,所以启用压缩同样有效。
对于reducer输出的压缩应该在存储或归档、改善写速度或者MapReduce作业时考虑。要压缩reducer输出,可使用标准实用工具(如gzip和bzip2)进行数据交换,并且对链式作业使用更快的编解码器。
下图展示了启用对map输出文件的压缩前MapReduce作业读写的字节数。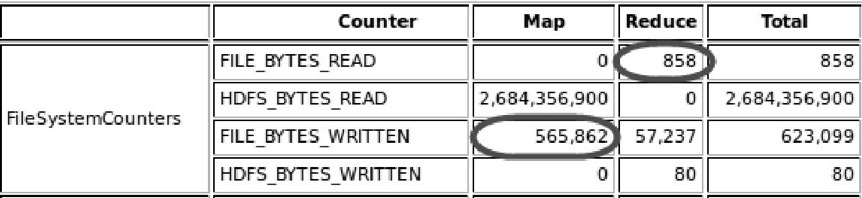
要启用压缩,可以修改下图所示参数mapred-site.xml:
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
<property>
<name>mapred.output.compressioon.type</name>
<value>BLOCK</value>
</property>在默认情况下:参数mapred.compress.map.output的值设置为false,而mapred.output.compressioon.type的值设置为RECORD。将这个值改为BLOCK可以提高压缩率。启用map输出文件的压缩以后,reduce函数读取字节数(268)与图6-5所示的(858)相比显著减少,如下图所示:
要在hadoop中启用压缩,可以参考下图表中的一些参数:

使用正确的writable类型
Hadoop使用自定义数据类型的序列化/RPC机制,并定义其自有的box类型的类(class)。这些类可用于操作字符串(Text)、整数(IntWritable)并实现了Writable类,Writable类定义了解序列化写意思。合理的使用类型,会得到不一样的效果。
优化MapReduce代码
优化mapper性能、优化reducer性能,经验而谈大概存在两个方面的问题:
- IO存取和溢写时间
- IO请求量过大导致附加等待时长
可能不是很完善,后续慢慢补充咯~
参考资料:Hadoop MapReduce性能优化
















 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











