








放正文之前,先打个假,这段话不是罗素说的,是啰嗦说的。一些箴言必须借助名人之口才能传播,可见折服我们的不是真理,而是附着在权威身上的权势和名利。
这次将解读一篇博士论文,思路“新奇”,但不要见论文就拜。
如何在投资组合策略中运用上机器学习方法? 最近,我们翻了下之前存过的论文,决定对《A portfolio Strategy Based on XGBoost Regression and Monte Carlo Method》这篇论文 1 进行解读,共分三部分:

本文是第一部分,论文构建的基于 XGBoost 的基本框架。
基本框架

这是论文抽象出来的一个基本框架图。
这个框架能解决的什么问题呢?我们知道,在一个投资组合策略中,要重点考虑的第一个问题是,如何从给定的 universe 中,选择一部分股票纳入策略股票池;其次要考虑,这部分股票的持仓如何分配,使之在这个组合上,达到风险收益比最高。
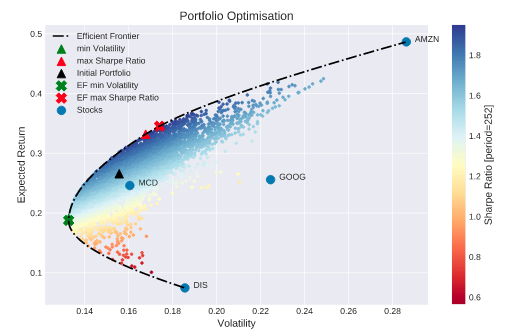
后一部分,最经典的方法就是运用 MPT 理论,寻找有效投资前沿。这里既可以用凸优化求解,也可以使用蒙特卡洛方案。这一部分,我们之前有一个系列文章:投资组合理论与实战,从基本概念到实战细节,都讲得非常清楚,这里就不详述了。
如何从 universe 中选择股票进入股票池? 这在单因子模型中比较容易解决,就是选择因子分层中,表现最佳的那个分层 (tier) 的股票进入股票池。各标的的权重可以按因子载荷来分配,也可以使用 MPT 方法。
但如何在多因子模型中选择股票进入股票池?这一直是一个难题。我们常常提到的 Barra 模型也只是一个风控模型,并不能选择出最佳的股票池出来。
论文的思路是,将股票的纳入选择看成一个回归问题,即,通过多因子的训练,找出最能被模型预测的那些股票进入股票池。
作者给出的结果是,在 2021、2020 和 2019 年,龙头股票投资组合的回报率分别为 27.86%, 6.20%和 23.26%。不过,作者并没有给出基准比较,此外,也没有深入分析,如果这些结果有超额收益的话,这些超额是来自于 MPT 呢,还是来自于 XGBoost。
这也是我们要对这篇论文进行解读的地方。希望通过我们的解读,你也可以学习到,究竟应该如何分析他人的论文,从中汲取正确的部分。
错误的回归
论文中使用的是 XGBoost 回归模型。这可能是值得商榷的地方。在资产定价模型中,我们要预测的是股票在截面上的强弱,而不是在时序上的走势。
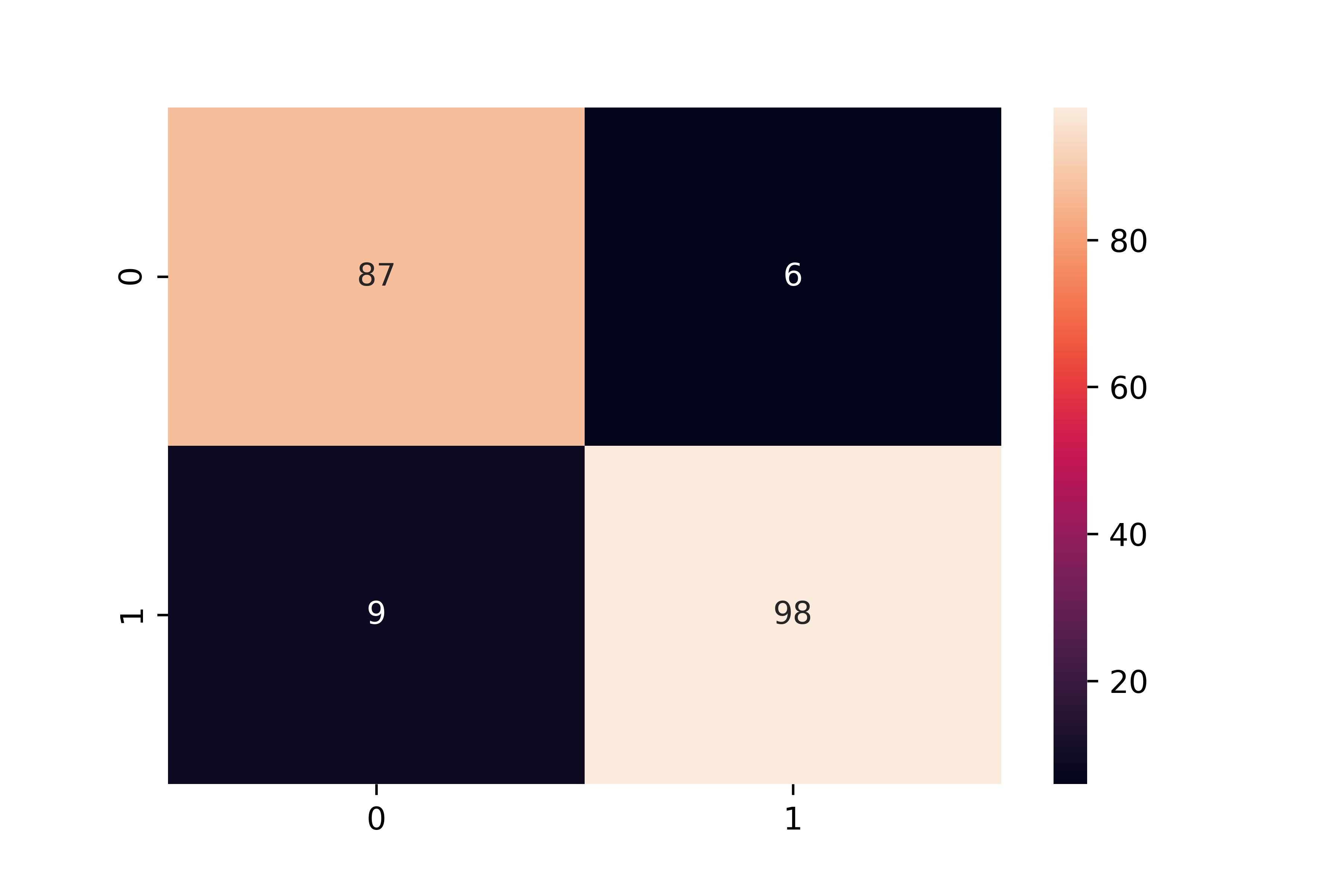
论文作者这里使用的方法是训练一个回归模型,从而使得它能较好地预测次日(或者后面一段时间的走势)。下图是论文作者得到的结果之一:

看起来模型能比较完美地预测次日走势。

显然,由于 XGBoost 回归模型本身没有预测股票强弱的能力,所以,即使通过回归模型找出了完美拟合的股票,也没有任何意义。因为一支下跌中的股票,也可能被完美地拟合出来。所以,论文中提到的收益,即使有超额,很可能也来自于 MPT 理论。
但是,作者仍然给出了一个如何通过 XGBoost 来寻找多因子模型中表现最佳个股的线索。我们只需要把它改造成一个分类模型,然后通过分类模型,筛选出表现最好的股票就可以了。
训练集中的 X 部分不用改变,但我们需要重新设定标签,即 y 部分。对给定的因子 X i X_i Xi,对应的 y i y_i yi需要能反映是上涨或者下跌。如果有可能,我们可以将标签设置为 5 类,-2 表示大跌,2 表示大涨,中间部分以此类推。
然后构造分类器进行训练。训练完成后,通过模型预测出来属于大涨标签的,我们就放入股票池,此时可以平均分配权重,也可以通过 MPT 理论来进行优化。
当然,我们构造标签和训练数据集时,要综合考虑实盘的持仓周期。
端到端训练及新的网络架构
论文作者使用的框架是两阶段式的,即先选择股票进入策略池,再通过 MPT 优化权重。
但即使是在第一阶段,它仍然是两段式的。每次进行训练时,它都只使用了一个标的的多因子数据。因此,如果 universe 中有 1000 支标的,就要训练出 1000 个模型(这是论文中暗示的方法,也可以考虑一个模型,训练 1000 次)。
这么做的原因是技术限制。XGBoost 只支持二维输入。如果我们要使用多个标的的多个因子同时进行训练,就必须使用 panel 格式的数据,或者将多个标的的多个因子进行一维展开。但如果标的数过多,展开后的训练会很困难。
也就是,由于技术限制,要么进行单因子的多标的同时训练,要么进行多因子的单标的训练。
但是,论文作者在这里给出了一个方法,就是你可以分别训练多个标的各自的模型,然后同样分别进行预测,然后再通过 MAPE 进行评估。当我们改成分类模型之后,可以简单地看分类结果,也可以结合分类的 metric 评估(在时序维度上的),选择准确性和分类结果都好的标的,纳入策略股票池。
这是我们从论文中应该学习到的方法。

结论
本期解读介绍了基于 XGBoost 的多因子组合策略的模型构建方法。它是一个两段式构造,通过训练单标的、多因子的多个模型,实现多因子模型选股。但是,论文作者错误地选择了回归模型,因而论文的结果很可能无法到达预期。
下一期文章,我们聊聊 MAPE 这个 metric。

















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











